






Conditional Image-to-Video Generation with Latent Flow Diffusion Models
问题描述
cI2V:基于条件的图像到视频的生成任务是指在给定一张初始图片(如一张人脸)和一个条件的情况合成一段视频,这个任务的核心就是视频内容要和给定图片和条件所对应空间网和时间动态保持一致。
与现有的条件图像生成任务类似,大多数现有的方法都是基于给定源图像和相应的条件来逐帧生成生成目标视频,或者直接基于给定源图像和条件生成目标视频,但是这两类方法往往难以具备良好的时空一致性。因此作者提出一个基于潜空间的流扩散模型(LFDM)来解决这样一个问题,该模型从时间和空间两个维度来解决时空一致性不足的问题。
总体思路
该模型整体思路如下:
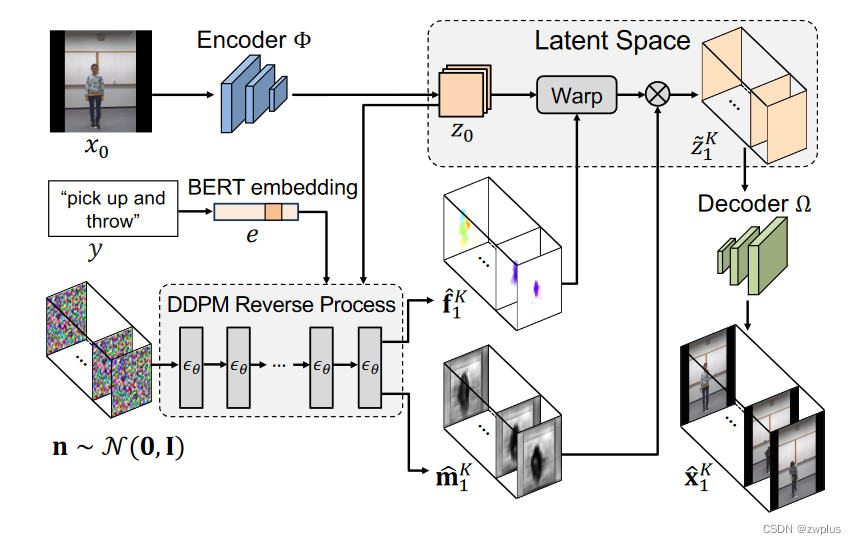
- 首先利用一个编码器将源图像x0映射成潜空间中对象z0
- 然后利用一个条件扩散模型以z0和文本类别描述作为约束来生成潜空间的上的光流图序列和遮挡图序列
- 然后利用生成光流图序列f和遮挡图序列m对z0在潜空间上进行扭曲变化,生成相应的潜空间对象序列
- 最后使用解码器对这个潜空间序列进行解码生成目标视频序列。
通过这样一个设计,生成的视频的时间一致性就可以通过使用潜空间上的流扩散模型依据于约束条件来生成这样光流序列来进行保证,同时这些光流序列都是源图像进行扭曲变化,这样就可以有助于生成的视频序列中每一帧图片的外观都和源图像保持一致,这样也可以避免使用之前的合成帧造成的伪影累积。(之前的方法会通过z0生成z1,再从z1生成z2这种渐进式的生成,是因为这种方法可以提高最后生成的序列的时间一致性,但是这样也就会存在着空间内容的误差在这种递进过程中不断增大的情况,而本文中的时间一致性通过使用扩散模型生光流序列来实现的,因此在扭曲阶段没有采用渐进式的生成,而是所有的流序列都是和z0进行扭曲操作的。)
详细设计
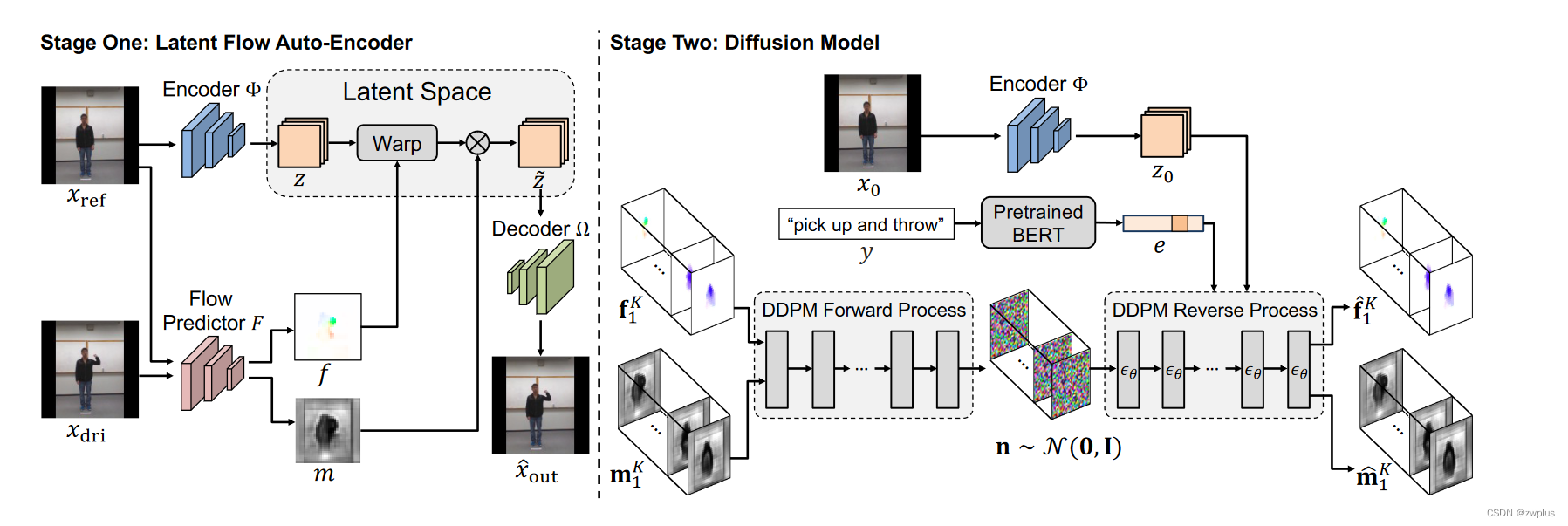
上述方法是本文的第一个创新点,也是本文的解决CI2V这样一个任务的核心思路,剩下的就是如何实现这样的一个思路。因为本文模型虽然是一个模型,但是本质上是两个模型组合产物:
- 第一个模型就是这样一个潜空间上的流扩散模型,这个扩散模型的任务就是依据于文本类别描述和源图像潜空间特征z0作为约束条件,生成相应的流变化序列。
- 第二个模型则是一个潜空间流自动编码器模型(LFAE),其主要任务就是,将源图像映射到潜空间中去,然后依据潜空间中的光流进行扭曲变化得到目标图像在潜空间中对象,再使用解码器将其解码成目标图像。
从这拆分出的这样的两个模型可以知道,这样的两个模型是没有办法组合起来进行训练的,因此本文提出了一个两阶段的训练方法来分别训练这两个模型,通过分步训练训练方式的也实现空间外观和时序变化的解耦操作。
阶段一
阶段一主要是训练LFAE(潜空间的流自编码器),前面我们提到说LFAE的任务就是依据于给定光流在潜空间对图片进行扭曲,再对扭曲后的图像在潜空间上的对象解码生成目标图像。因此LFAE需要一个编码器来将图像映射到潜空间,还需要一个解码器来将潜空间中对象映射回像素空间,除此之外还需要一个流预测器来根据源图片和目标图片预测流图。整个训练过程如下:
-
从一段视频中随机抽取两帧图像分布作为原图和目标图像,
-
使用流预测器以源图像和目标图像作为输入预测出变化流图f和遮挡图m
-
使用编码器将源图片映射到潜空间中,生成潜空间变量Z,并使用2中生成的变化流图f来对Z进行扭曲来将其编码目标图像在潜空间中映射,但是只使用变化流图f进行扭曲并不能很好将变成目标图像在潜空间中的对象,因为使用流图进行扭曲的操作只能使用z已有的外观信息,如果目标图像存在着源图像中不可见的部分,这时只使用扭曲操作是不能很好表示这些对源图像来说未知部分,因此此时需要使用遮挡图来指示出那些地方存在遮挡。这里遮挡图的取值范围在0-1之间,表示遮挡程度[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
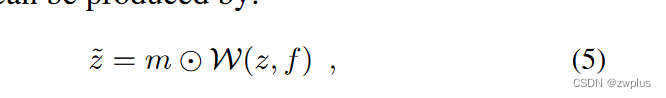
-
在到经过扭曲和遮挡后潜空间对象后,使用解码器恢复出可以见部分和并重绘不可见部分,所以这解码器不同于一般自编码器中的重建操作,其还需要生成未知的外观部分,因此在模型设计上,这里解码器要比编码器更大一点
-
最后将生成图像和目标图像做差作为整个LFAE模型的损失函数来优化模型
阶段二
阶段二就是训练一个diffusion模型,该模型的目标就是依据给定的文本类别和源图像的潜空间对象作为条件生成相应流图序列和遮挡图的序列。这个diffusion模型有几个需要注意的地方是:
- 因为需要生成流图序列和遮挡图序列,因此这里使用3D-UNET,而不是常见的2D-UNET
- 这里使用BERT模型来编码文本类别条件编码成文本嵌入,但是需要注意这里只做到了文本类别,还没有做到stable diffusion那种文本描述级别,也就是这里文本约束更多的是举手,微笑这些动作类别,而不是他举起手了这种句子描述,然后理论上如果只是类别类型条件可以使用one-hot的编码来表示,但是这里作者认为one-hot编码不能够很好地表示这种文本类别的动作间的相互关系,因此作者这里用BERT模型来对文本类别进行编码。
- 这个扩散模型的训练过程如下:首先使用阶段一中训练好的流预测模型从源图像和目标图像序列中预测出流图序列和遮挡图序列作为ground-truth,然后对ground-truth进行加噪处理得到噪声图,然后使用unet模型在给定的条件下预测噪声,然对噪声图去噪还原出ground-truth。
*** 通过阶段一和阶段二这两种解耦训练方式,使得模型可以分别对空间外观和时间动态进行建模,避免模型在时空耦合这种复杂空间进行建模,降低模型学习的难度,同时面对未知主体,只需要对第一阶段的编码器进行微调就可以很好对未知主体的外观进行生成,提高模型的迁移能力,同时相较laten diifusion这类在图像潜空间的扩散模型,流的潜空间不包含复杂的纹理和色彩信息,只包含动作和形状特征,因此更加简单,使得模型的学习更加简单,计算量也有所减低***
实验
数据集
MUG:面部表情视频数据集,共7类表情:愤怒,厌恶,恐惧,高兴,中性,悲伤,惊讶
MHAD:人体动作数据集,包含27种动作
NATOPS:人体动作数据集,包含24种手部和身体数据集
评价指标
FVD:与FID类似,不过是由于评价的视频数据,所以用的I3D模型来进行的特征提取。
同时为了衡量的生成视频的与给定的源图像之间的空间外观一致性和给定动作条件的时间动态一致性;作者提出了cFVD和sFVD这两个FVD的变体,
cFVD计算方式就将生成的伪造视频和相同动作条件下的真实视频进行计算FVD,sFVD的计算方式就将生成的伪造视频和相同主体的真实视频之间进行计算FVD。
与其他方法比较

条件生成(使用条件y)
同其他方法的比较可以,本文提出的方法在各项指标上都取了最好的成绩。
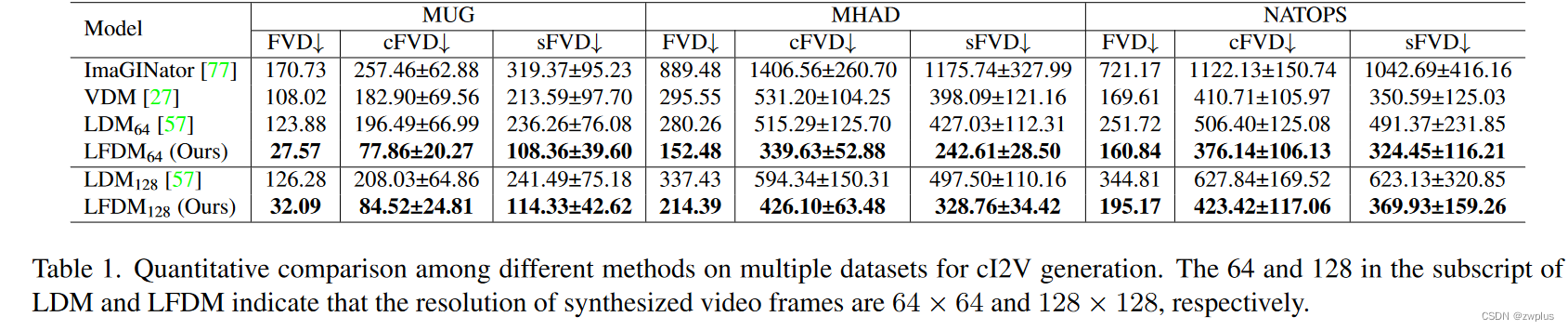
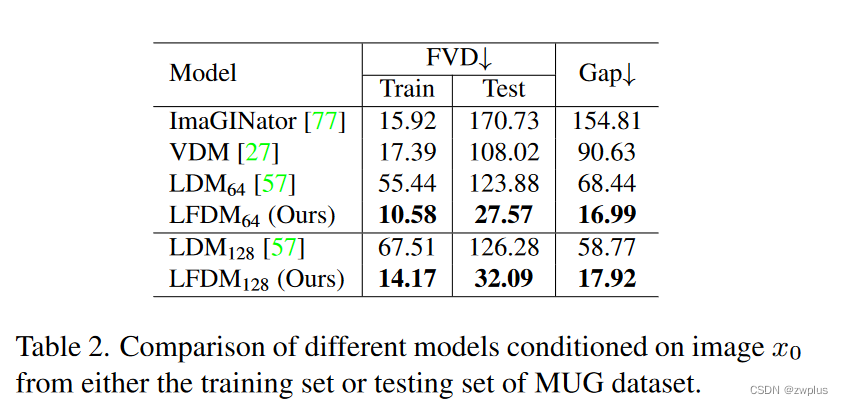
为了进一步分析,各个模型在性能上的差异,作者分别使用训练集中的人物主体和测试集中的人物主体作为源图像来生成视频,并分别与真实视频计算FVD,可以看到本文的方法在训练集和测试集上的差异最小,作者认为这可以归功于基于扭曲变化设计能够充分利用源图像的已有信息并和原图像保持一致,同时两阶段的解耦训练的设计,使得模型可以在不同阶段专注于解决不同问题,这有利模型的学习。
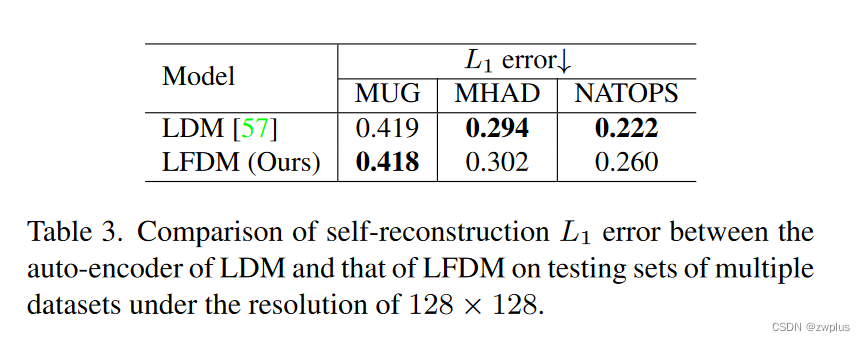
这里的LDM 就是laten diffusion的视频版本,就是原本laten diffusion中的2D-unet换成了3D-UNET。
作者这里比较了一下LDM中的自编码器和LFDM中的自编码器再重建图像时的性能,发现LDM的自编码器的重建性能甚至好于本文的模型,但是在最终的生成视频的指标上要明显差于本文提出模型,作者认为是LDM的3D-UNET不能很好地在潜空间中同时对时间和空间信息进行建模,而本文通过空间和时间解耦的方式,使得本文方法中的3D-UNET只需要负责对流空间进行建模,其只包含动作信息和形状信息,因此取得了更好的效果。
无条件生成(不使用条件y)
作者也比较在不使用文本类别描述作为约束条件时模型的生成能力
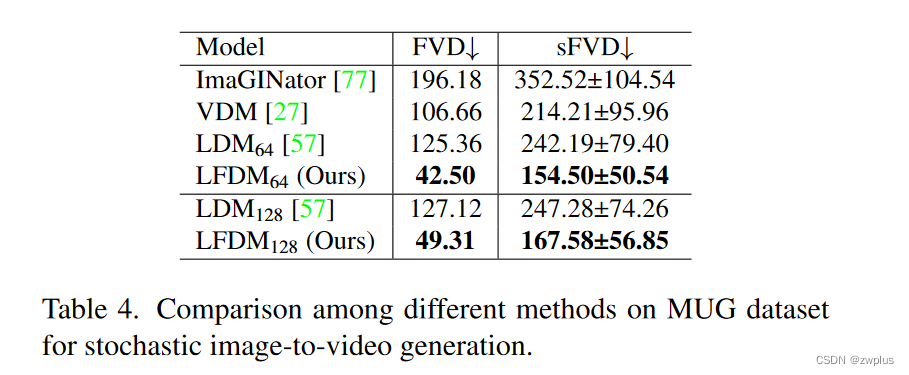
泛化能力
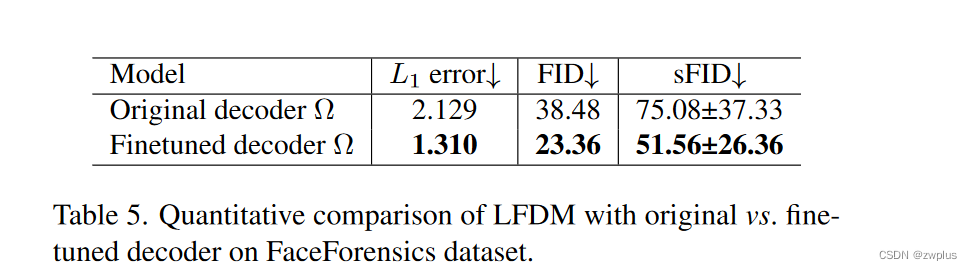
作者比较本文提出模型迁移到新的人脸域中的生成效果,作者这里使用两种迁移方式:
- 微调整个模型
- 只微调解码器模型
可以本文的方法只需要是对解码器进行微调就可以取得很好的迁移效果,这也说明了本文这种两阶段训练方式的灵活性。

消融实验
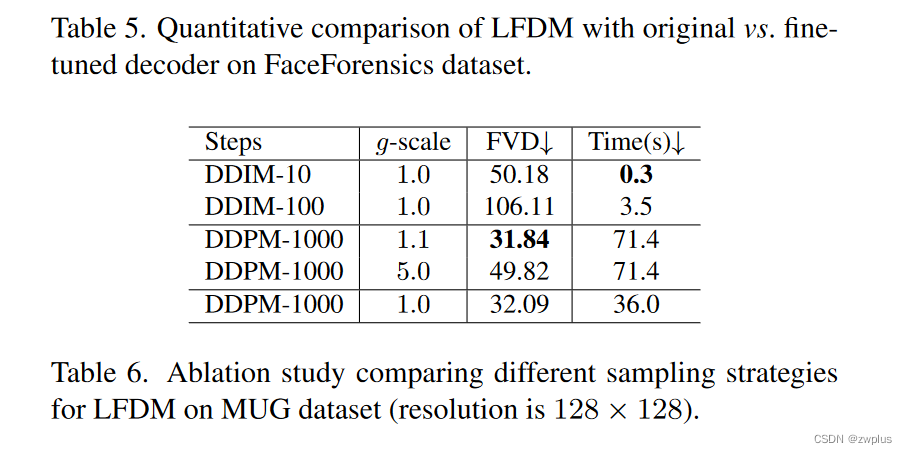
作者这里的消融实验比较了使用不同去噪算法和去噪步数和条件约束尺度之间在生成效果和时间上的区别,一个不太符合常理的是在使用DDIM时更多的去噪步数的效果反而变差了,这里作者也没有解释原因。















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









