









文本讲述并行技术是模型并行,即模型被分割并分布在一个设备阵列上,每一个设备只保存模型的一部分参数。
模型并行分为张量并行和流水线并行,张量并行为层内并行,对模型 Transformer 层内进行分割、流水线为层间并行,对模型不同的 Transformer 层间进行分割。

简介
所谓流水线并行,就是由于模型太大,无法将整个模型放置到单张GPU卡中;因此,将模型的不同层放置到不同的计算设备,降低单个计算设备的显存消耗,从而实现超大规模模型训练。
流水线并行PP(Pipeline Parallelism),是一种最常用的并行方式,也是最初Deepspeed和Megatron等大模型训练框架都支持的一种并行方式。
如下图所示,模型共包含四个模型层(如:Transformer层),被切分为三个部分,分别放置到三个不同的计算设备。
即第 1 层放置到设备 0,第 2 层和第三 3 层放置到设备 1,第 4 层放置到设备 2。
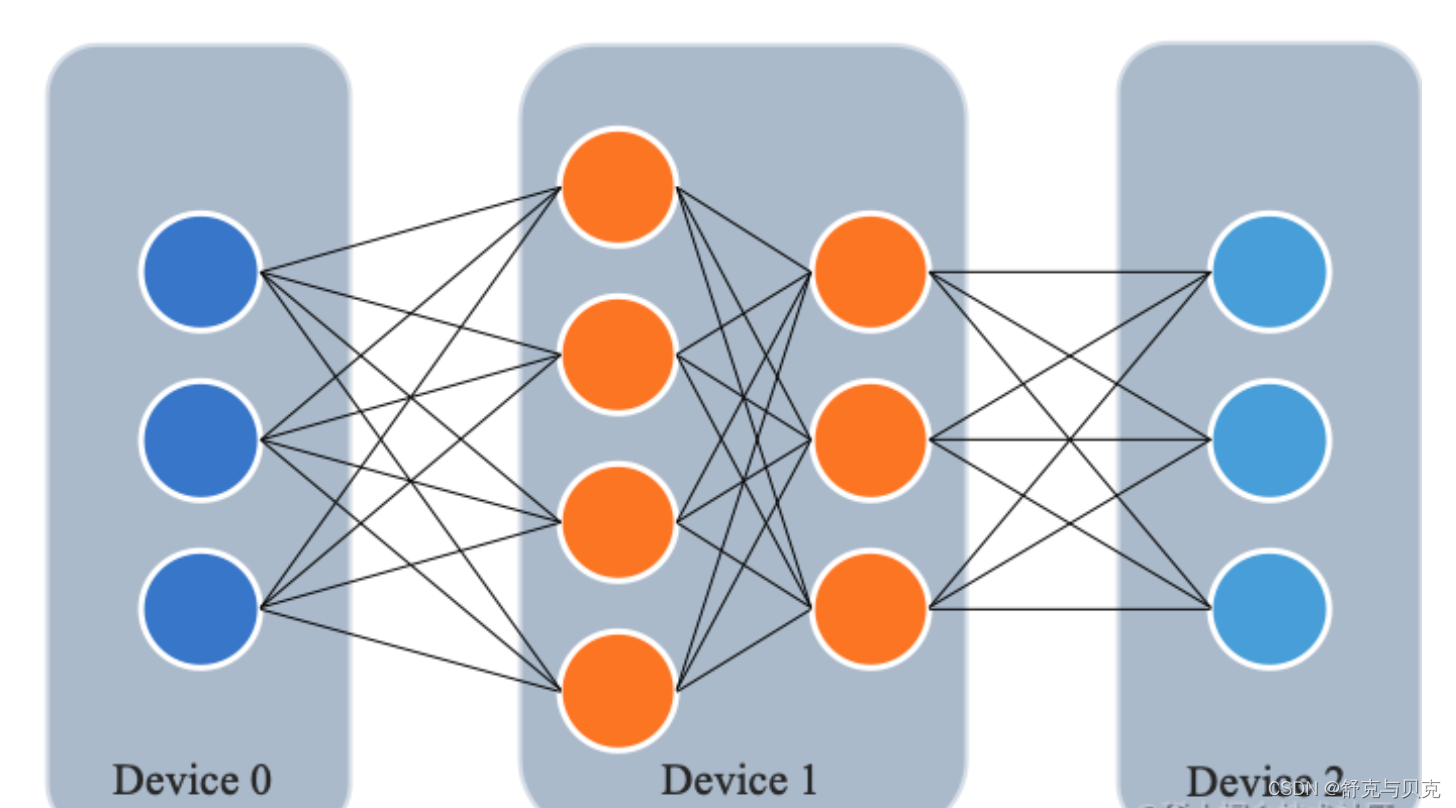
相邻设备间通过通信链路传输数据。
前向计算过程中,输入数据首先在设备 0 上通过第 1 层的计算得到中间结果,并将中间结果传输到设备 1,然后在设备 1 上计算得到第 2 层和第 3 层的输出,并将模型第 3 层的输出结果传输到设备 2,在设备 2 上经由最后一层的计算得到前向计算结果。反向传播过程类似。最后,各个设备上的网络层会使用反向传播过程计算得到的梯度更新参数。由于各个设备间传输的仅是相邻设备间的输出张量,而不是梯度信息,因此通信量较小。
通过这种方式,可以让原先无法装载大模型的单一GPU训练模式通过类似流水线扩展的方式,让更多的GPU显存来承载训练中的模型的各种参数,梯度,优化器,Activation等数据。
朴素流水线并行
朴素流水线并行是实现流水线并行训练的最直接的方法。我们将模型按照层间切分成多个部分(Stage),并将每个部分(Stage)分配给一个 GPU。然后,我们对小批量数据进行常规的训练,在模型切分成多个部分的边界处进行通信。
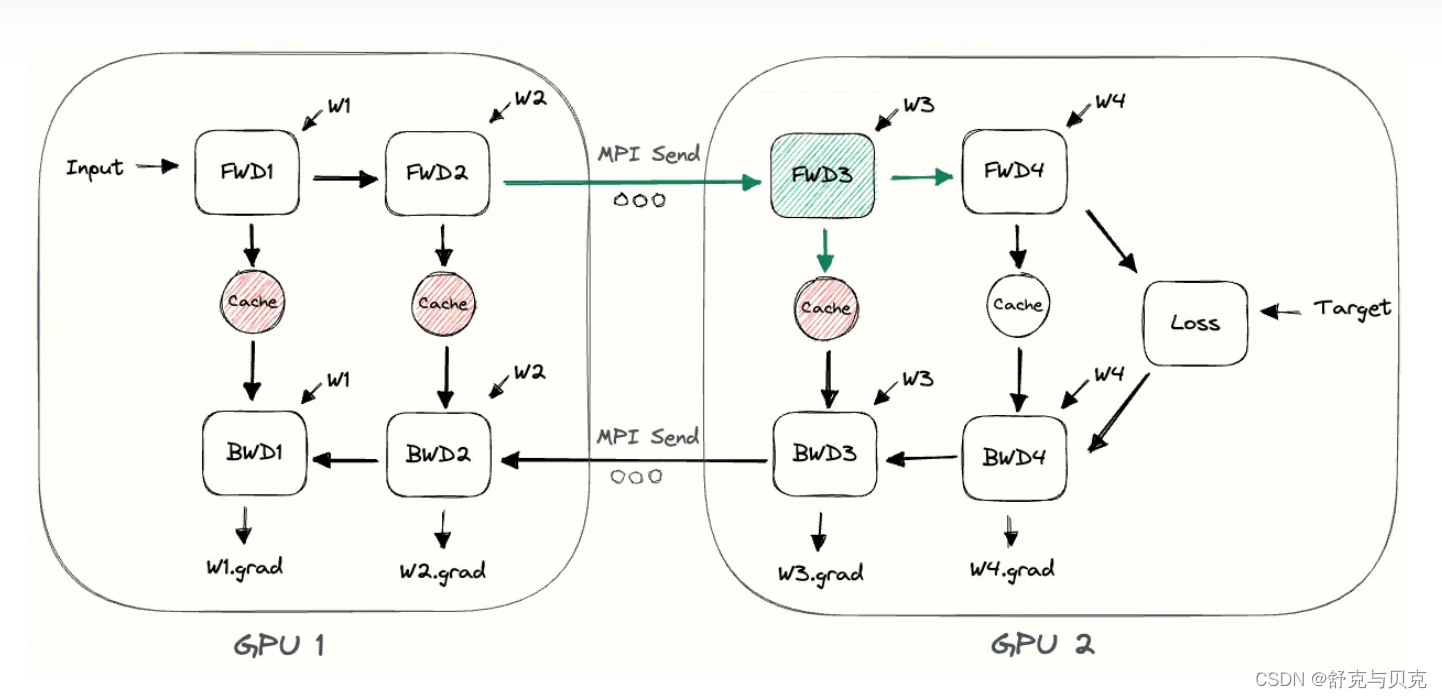
下面以 4 层顺序模型为例:
output=L4(L3(L2(L1(input))))
我们将计算分配给两个 GPU,如下所示:
- GPU1 computes:
intermediate=L2(L1(input)) - GPU2 computes:
output=L4(L3(intermediate))
为了完成前向传播,我们在 GPU1 上计算中间值并将结果张量传输到 GPU2。 然后, GPU2 计算模型的输出并开始进行反向传播。 对于反向传播,我们从 GPU2 到 GPU1 的中间发送梯度。 然后, GPU1 根据发送的梯度完成反向传播。 这样,流水线并行训练会产生与单节点训练相同的输出和梯度。 朴素流水线并行训练相当于顺序训练,这使得调试变得更加容易。
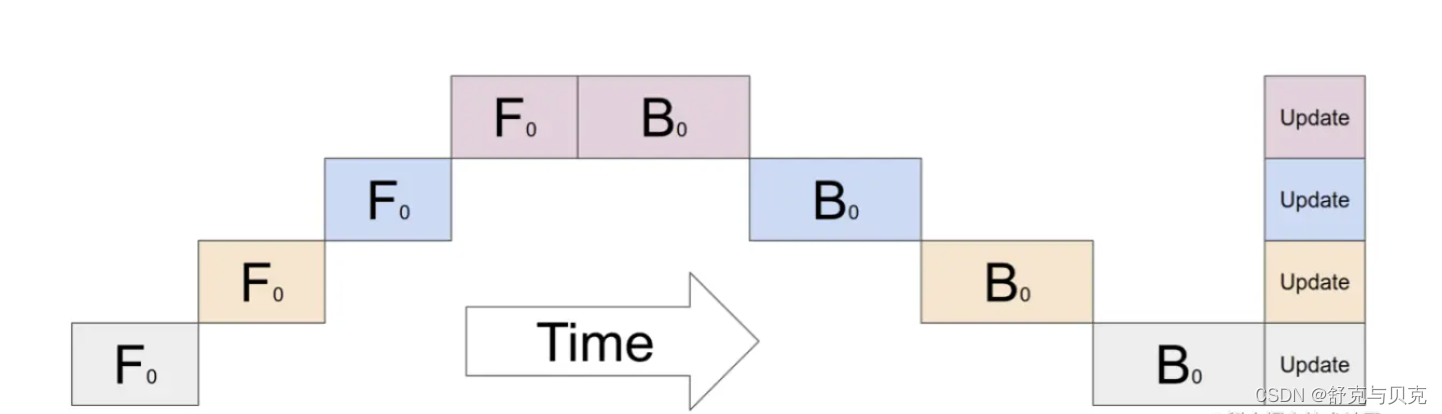
朴素流水线并行存在的问题:
那么该方法为什么被称为朴素流水线并行呢,它又有什么缺陷呢?
- 低GPU利用率。 在任意时刻,有且仅有一个GPU在工作,其他GPU都是空闲的。
- 计算和通信没有重叠。在发送前向传播的中间结果(FWD)或者反向传播的中间结果(BWD)时,GPU也是空闲的。
- 高显存占用。GPU1需要保存整个minibatch的所有激活,直至最后完成参数更新。如果batch size很大,这将对显存带来巨大的挑战。
主要是因为该方案在任意给定时刻,除了一个 GPU 之外的其他所有 GPU 都是空闲的。因此,如果使用 4 个 GPU,则几乎等同于将单个 GPU 的内存量增加四倍,而其他资源 (如计算) 相当于没用上。所以,朴素流水线存在很多的Bubble。朴素流水线的 Bubble 的时间为 𝑂(𝐾−1/𝐾),当K越大,即GPU的数量越多时,空置的比例接近1,即GPU的资源都被浪费掉了,因此,朴素的流水线并行将会导致GPU使用率过低。
另外,还需要加上在设备之间复制数据的通信开销;所以 4 张使用朴素流水线并行的 6GB 卡将能够容纳 1 张 24GB 卡相同大小的模型,而后者训练得更快;因为,它没有数据传输开销。
还有通信和计算没有交错的问题:当我们通过网络发送中间输出 (FWD) 和梯度 (BWD) 时,没有 GPU 执行任何操作。
除此之外,还存在高内存需求的问题:先执行前向传播的GPU(如:GPU1)将保留整个小批量缓存的所有激活,直到最后。如果批量大小很大,可能会产生内存问题。
MicroBatch流水线并行
微批次(MicroBatch)流水线并行与朴素流水线几乎相同,但它通过将传入的小批次(minibatch)分块为微批次(microbatch),并人为创建流水线来解决 GPU 空闲问题,从而允许不同的 GPU 同时参与计算过程,可以显著提升流水线并行设备利用率,减小设备空闲状态的时间。就是让那个每一次的前向计算/反向传播的链条尽可能的小,通过加快每一次计算的时间,来降低算力的浪费,那么这个思路就是Gpipe的原型。目前业界常见的流水线并行方法 GPipe 和 PipeDream 都采用微批次流水线并行方案。
Q:为什么不直接并发跑多个 batch,而要拆分当前 batch?
A:(1)最好是跑完一个 batch,得到梯度,更新完参数,再跑下一个,这样比较稳定;(2)多个 batch 同时跑的话,需要保存的中间结果多很多;
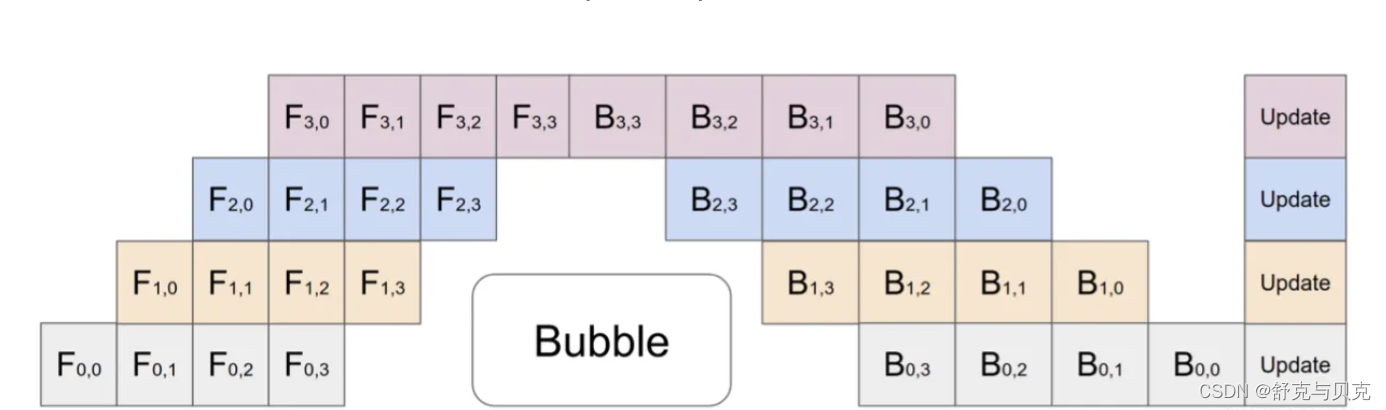
Gpipe流水线并行
Gpipe并行的原理就是把一个Mini-bacth,拆解成更小的Micro-batches,比如上图的把一个Mini-batch,拆成4个Micro-batches(F0-F3,B3-B0)。
这样做的好处是,当F1也就是前向计算的第一个Micro-batch1被GPU0计算完毕,它就会传递到模型的下一层GPU1,然后GPU0可以继续计算Micro-batch2,以此类推,在同一个计算时间内,尽可能的压榨算力获得更高的性能。
Gpipe 流水线并行主要用来解决这两个问题:
第一,提高模型训练的并行度。Gpipe 在朴素流水线并行的基础上,利用数据并行的思想,将 mini-batch 细分为多个更小的 micro-batch,送入GPU进行训练,来提高并行程度。
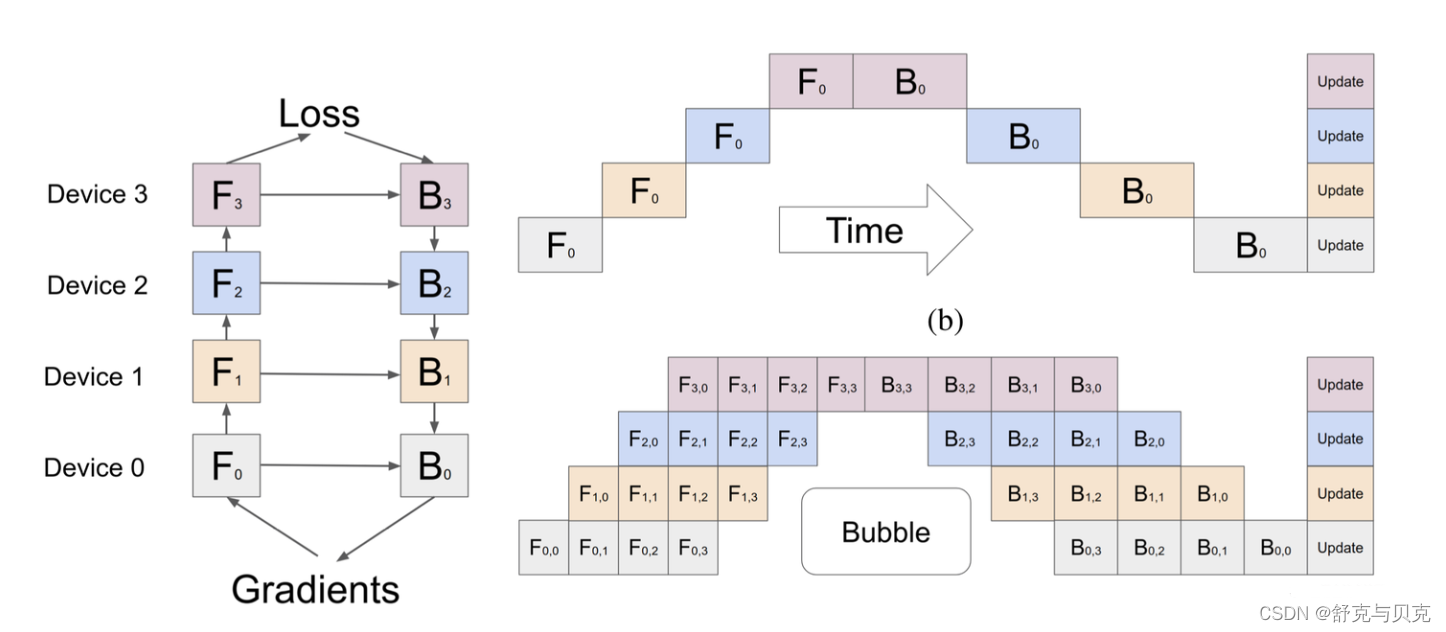
上图即为朴素流水线并行与 GPipe 微批次流水线并行对比,通过 GPipe 可以有效降低流水线并行bubble 空间的比例。其中,F的第一个下标表示 GPU 编号,F的第二个下标表示 micro-batch 编号。
假设我们将 mini-batch 划分为 M 个,则 GPipe 流水线并行下, GPipe 流水线 Bubble 时间为:
O((𝐾−1/(𝐾+𝑀−1))。其中,K为设备,M为将mini-batch切成多少个micro-batch。当M>>K的时候,这个时间可以忽略不计。
但这样做也有一个坏处,那就是把 batch 拆小了之后,对于那些需要统计量的层(如:Batch Normalization),就会导致计算变得麻烦,需要重新实现。在Gpipe中的方法是,在训练时计算和运用的是micro-batch里的均值和方差,同时持续追踪全部mini-batch的移动平均和方差,以便在测试阶段进行使用。这样 Layer Normalization 则不受影响.
简而言之,GPipe 通过纵向对模型进行切分解决了单个设备无法训练大模型的问题;同时,又通过微批量流水线增加了多设备上的并行程度.
上面讲述了 GPipe 流水线并行方案,接下来讲述一下 PipeDream 。讲述 PipeDream之前,我们先来看看流水线并行策略。
流水线并行策略
流水线并行根据执行的策略,可以分为 F-then-B 和 1F1B 两种模式。
之前讲述的朴素流水线并行以及GPipe都是F-then-B模型,而后续讲述的 PipeDream 则是 1F1B 模式。
F-then-B 策略
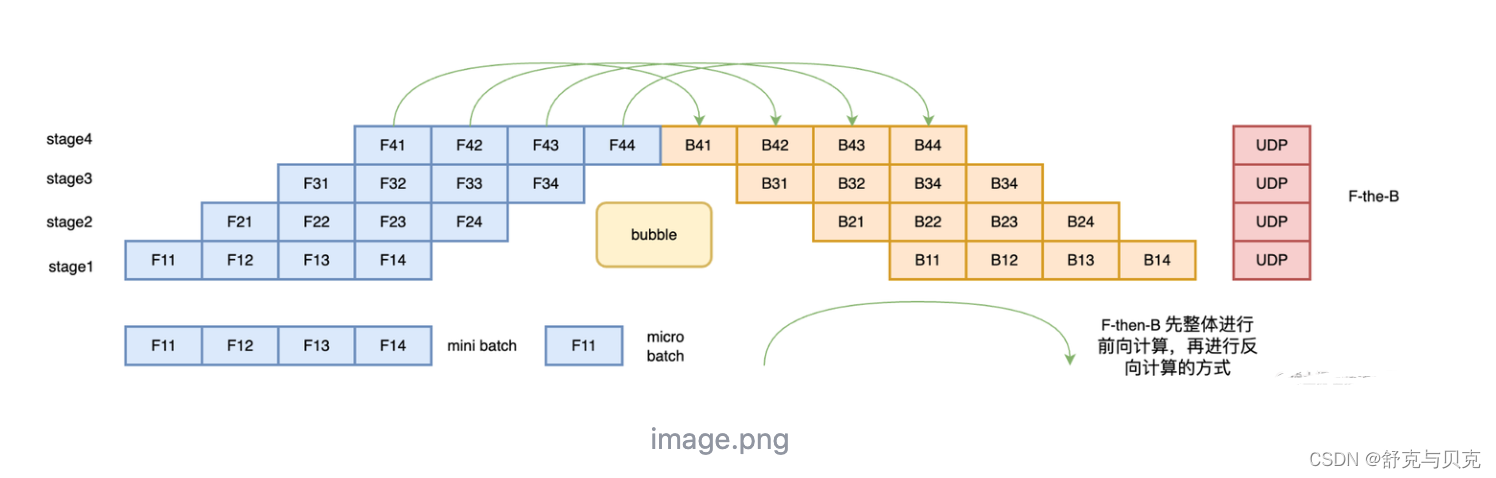
F-then-B 模式,先进行前向计算,再进行反向计算。
F-then-B 模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
1F1B 策略
1F1B(One Forward pass followed by One Backward pass)模式,一种前向计算和反向计算交叉进行的方式。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。
1F1B 示例如下图所示,以 stage4 的 F42(stage4 的第 2 个 micro-batch 的前向计算)为例,F42 在计算前,F41 的反向 B41(stage4 的第 1 个 micro-batch 的反向计算)已经计算结束,即可释放 F41 的中间变量,从而 F42 可以复用 F41 中间变量的显存。
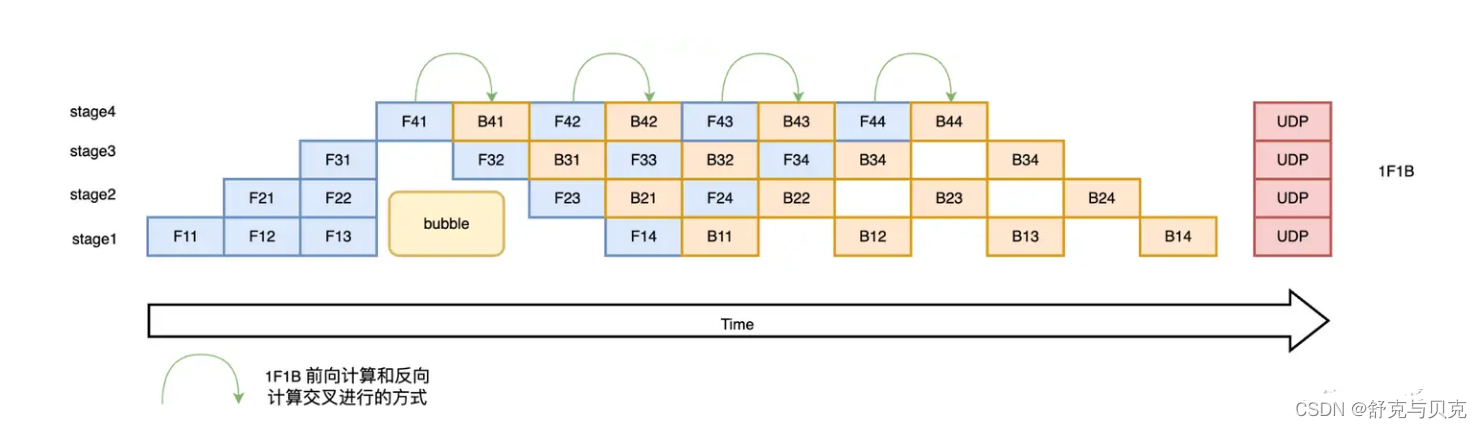
研究表明,1F1B 方式相比于 F-then-B 方式,峰值显存可以节省 37.5%,对比朴素流水线并行峰值显存明显下降,设备资源利用率显著提升。
PipeDream(非交错式1F1B)--- DeepSpeed
Gpipe 的流水线有以下几个问题:
- 将 mini-batch 切分成 m 份 micro-batch 后,将带来更频繁的流水线刷新(Pipeline flush),这降低了硬件效率,导致空闲时间的增加。
- 将 mini-batch 切分成 m 份 micro-batch 后, 需要缓存 m 份 activation,这将导致内存增加。原因是每个 micro-batch 前向计算的中间结果activation 都要被其后向计算所使用,所以需要在内存中缓存。即使使用了重计算技术,前向计算的 activation 也需要等到对应的后向计算完成之后才能释放。
而微软 DeepSpeed 提出的 PipeDream ,针对这些问题的改进方法就是 1F1B 策略。这种改进策略可以解决缓存 activation 的份数问题,使得 activation 的缓存数量只跟 stage 数相关,从而进一步节省显存,训练更大的模型。其解决思路就是努力减少每个 activation 的保存时间,即这就需要每个微批次数据尽可能早的完成后向计算,从而让每个 activation 尽可能早释放。
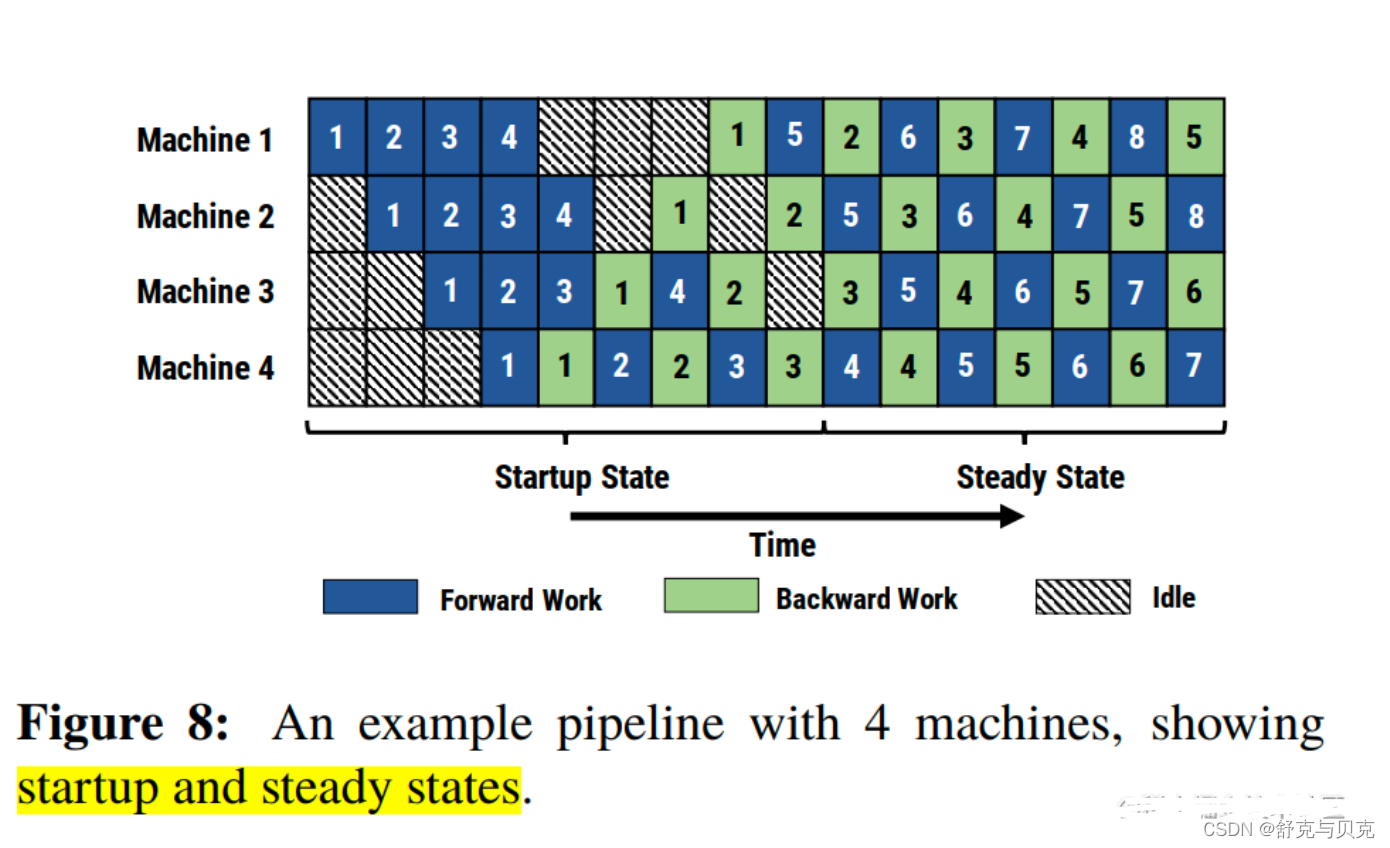
注意:微批次在 GPipe 中叫 micro-batch,而在 PipeDream 叫 mini-batch。为了避免干扰,本文统一使用 micro-batch。
PipeDream 具体方案如下:
- 一个阶段(stage)在做完一次 micro-batch 的前向传播之后,就立即进行 micro-batch 的后向传播,然后释放资源,那么就可以让其他 stage 尽可能早的开始计算,这就是 1F1B 策略。有点类似于把整体同步变成了众多小数据块上的异步,而且众多小数据块都是大家独立更新。
- 在 1F1B 的稳定状态(steady state,)下,会在每台机器上严格交替的进行前向计算/后向计算,这样使得每个GPU上都会有一个 micro-batch 数据正在处理,从而保证资源的高利用率(整个流水线比较均衡,没有流水线刷新(Pipeline Flush),这样就能确保以固定周期执行每个阶段上的参数更新。
- 面对流水线带来的异步性,1F1B 使用不同版本的权重来确保训练的有效性。
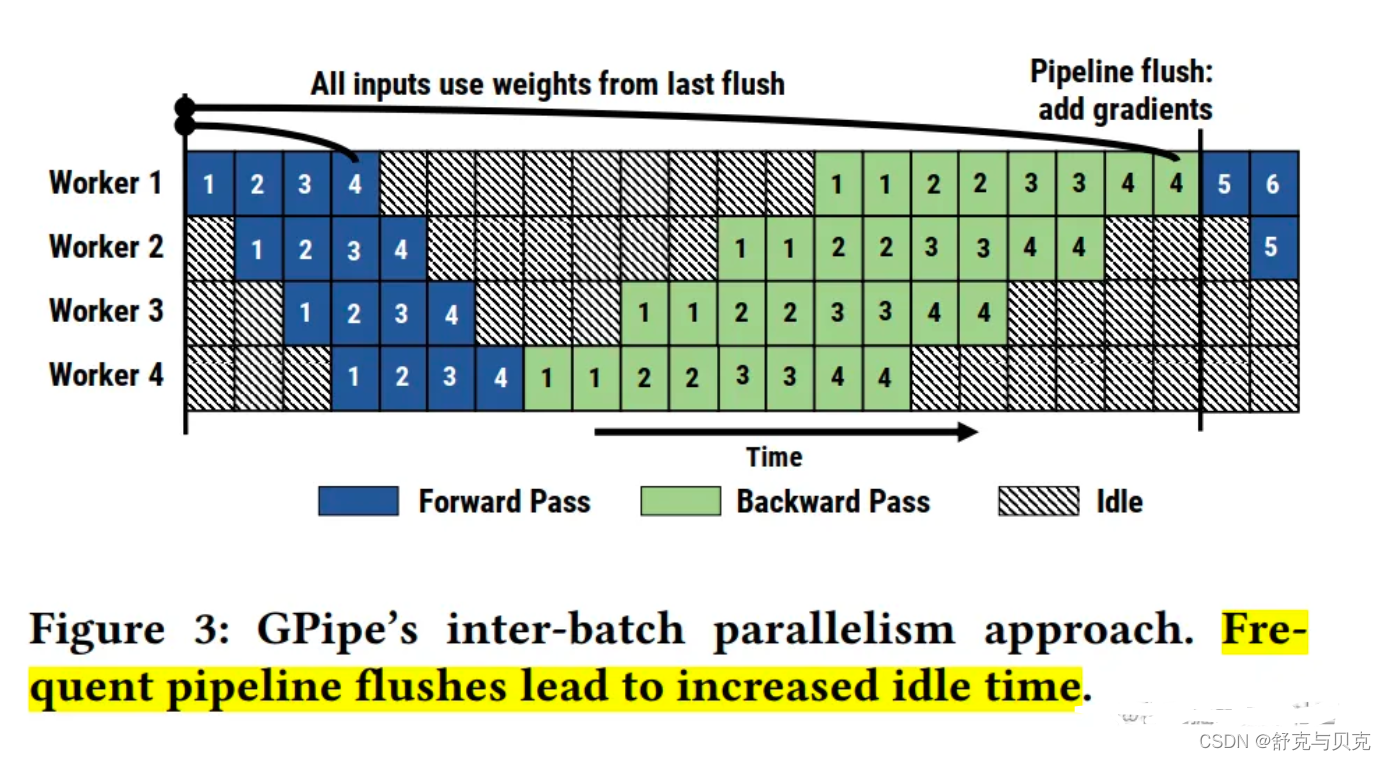
相比 GPipe,表面上看 PipeDream 在Bubble率上并没有优化,PipeDrea 流水线 Bubble 时间仍然为: 𝑂((𝐾−1)/(𝐾+𝑀−1))。但节省了显存之后,在设备显存一定的情况下,就可以通过增大 M 的值(增大micro-batch的个数)来降低Bubble率了。
但是这种算法也带来了一个比较大的问题,如上图所示,当前向传播的5号Micro-batch在Machine1上就开始传递的时候,实际上它使用的权重是Micro-batch 1做完了反向传播之后更新的权重,与此同时,FW2–4并没有完成梯度更新,所以这里存在了一个冲突,在Machine2上,它的FW5又是在Micro-batch1–2做完反向传播的情况下更新的,那么在这个时间段上,Machine1和Machine2的权重又起了冲突,这是第二个冲突。
为了解决这个冲突,在1F1B的基础上,PipeDream引入了Weight stashing和Vertical Sync两种技术来矫正权重的冲突和同步, 说白了就是多版本控制:
- Weight stashing : 为权重维护多版本,每个active micro-batch一个版本。每个stage 都用最新版本的权重进行前向计算,处理输入的Micro-batch。计算前向传播之后,会将这份参数保存下来用于同一个Micro-batch的后向计算。Weight stashing确保在一个阶段内,相同版本的模型参数被用于给定Micro-batch的向前和向后传播,但是不能保证跨阶段间Mini-batch使用模型参数的一致性。
- Vertical Sync : 每个Micro-batch进入pipeline时都使用输入stage最新版本的参数,并且参数的版本号会伴随该Micro-batch数据整个生命周期,在各个阶段都是用同一个版本的参数(而不是Weight stashing那样都使用最新版本的参数),从而实现了stage间的参数一致性。
问题1:同一个微批次数据,相同的device(相同stage),在前向计算和反向计算,采用不同版本的模型参数。
示例:
- Device 1 的微批次5数据,在前向传播使用了第1个版本模型(微批次1反向传播完成),
- Device 1 的微批次5数据,在反向传播使用了第4个版本模型(微批次1、2、3、4反向传播完成)

解决办法:Weight Stashing方法
每个device多备份几个不同版本的权重,确保同一个微批次数据,在前向计算和后向计算采用同一个版本的模型权重。计算前向传播之后,会将这份前向传播使用的权重保存下来,用于同一个 minibatch 的后向计算。
示例:
- Device 1 的 微批次5数据, 在前向传播使用了第1个版本模型(微批次1反向传播完成),
- Device 1 的 微批次5数据, 在反向传播使用了第1个版本模型(微批次1反向传播完成)
问题2:同一个微批次数据,相同的操作(都是前向或者都是反向),在不同的device上(不同stage),采用不同版本的模型参数。
示例:
- Device 1 的微批次5数据,在前向传播使用了第1个版本模型(微批次1反向传播完成)
- Device 2 的微批次5数据,在前向传播使用了第2个版本模型(微批次1、2反向传播完成)

解决方法:Vertical Sync 方法。
每个批次数据进入pipeline时都使用当前device(阶段)最新版本的参数,并且参数版本号会伴随该批次数据整个生命周期,从而实现了device(阶段)间的参数一致性。
示例:
- Device 1 的微批次5数据,在前向传播使用了第1个版本模型(微批次1反向传播完成)
- Device 2 的微批次5数据,在前向传播使用了第1个版本模型(微批次1反向传播完成)
1F1B 调度(schedule)模式
上面讲述了 PipeDream,在使用 1F1B 策略时,存在两种调度模式:非交错调度和交错式调度。具体如下图所示,上面的部分显示了默认的非交错式调度(non-interleaved schedule),底部显示的是交错式调度(interleaved schedule)。
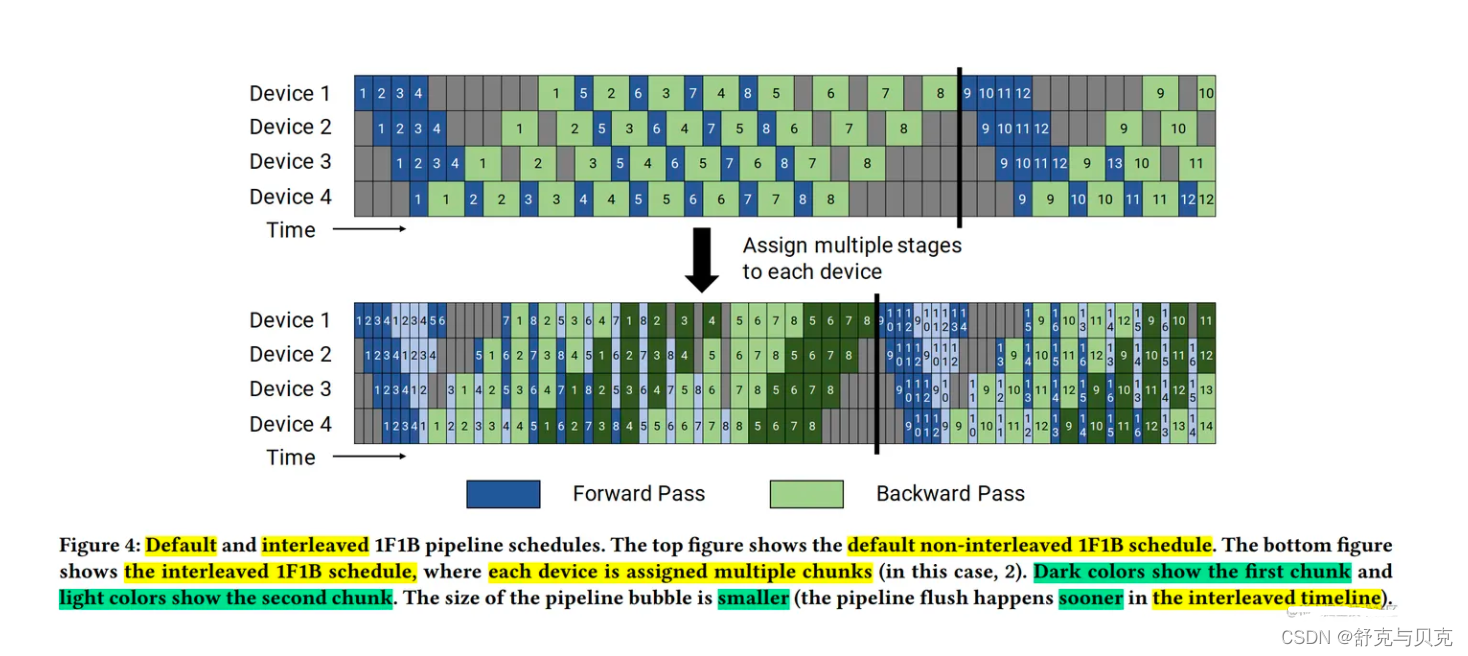
非交错式调度
非交错式调度可分为三个阶段。
第一阶段:启动热身阶段。微批次的前向传播,直到完成第1个小批次的前向传播。
第二阶段:稳定阶段。交替执行后续微批次的前向传播和反向传播。
第三阶段:结尾阶段。微批次的反向传播,对应着启动热身阶段的前向传播。
上面的讲到微软的 PipeDream 就是使用非交错式 1F1B 调度。虽然,这种调度模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
交错式调度
在交错式调度中,每个设备可以对多个层的子集(称为模型块)进行计算,而不是一个连续层的集合。
具体来看,在之前非交错式调度中,设备1拥有层1-4,设备2拥有层5-8,以此类推;但在交错式调度中,设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。在交错式调度模式下,流水线上的每个设备都被分配到多个流水线阶段(虚拟阶段,virtual stages),每个流水线阶段的计算量较少。
这种模式既节省内存又节省时间。但这个调度模式要求 micro-batch 的数量是流水线阶段(Stage)的整数倍。
大模型分布式训练并行技术(三)-流水线并行 - 知乎 (zhihu.com)
LLM分布式训练第三课-模型并行之流水线并行 - kevin zhou - Medium
图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例 - 知乎 (zhihu.com)
LLM训练06 流水线并行 - 知乎 (zhihu.com)

















 1861
1861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









