







0. 概览
数据并行(Data Parallelism):在不同的GPU上运行同一批数据的不同子集;
流水并行(Pipeline Parallelism):在不同的GPU上运行模型的不同层;
模型并行(Model Parallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
流水线并行(Pipeline Parallelism)是一种在分布式计算环境中实现模型并行的技术,主要用于深度学习领域,特别是在处理大规模神经网络模型时。通过将模型的不同部分(如神经网络的层)分配到不同的计算节点上,流水线并行能够在不牺牲训练效率的情况下,利用集群中的多台机器共同完成模型训练。
数据并行参考:
《训练中的数据并行DP详细讲解》
1. 简单流水并行
我们将模型拆分成多个部分,并将每个部分分配给一个 GPU。然后,我们在小批量上进行常规训练,在拆分模型的边界处插入通信步骤。
我们以 4 层顺序模型为例:
o
u
t
p
u
t
=
L
4
(
L
3
(
L
2
(
L
1
(
i
n
p
u
t
)
)
)
)
output=L_4(L_3(L_2(L_1(input))))
output=L4(L3(L2(L1(input))))
我们将计算划分到两个 GPU 上,如下所示:
- GPU1 计算:
i n t e r m e d i a t e = L 2 ( L 1 ( i n p u t ) ) intermediate = L_2(L_1(input)) intermediate=L2(L1(input))
- GPU2 计算:
o u t p u t = L 4 ( L 3 ( i n t e r m e d i a t e ) ) output=L_4(L_3(intermediate)) output=L4(L3(intermediate))
前向传递,itermediate 在 GPU1 上进行计算并将结果张量传输到 GPU2。然后,GPU2 计算模型的输出并开始反向传递。
反向传递,intermediateGPU2 的梯度发送到 GPU1。然后,GPU1 根据发送的梯度完成反向传递。
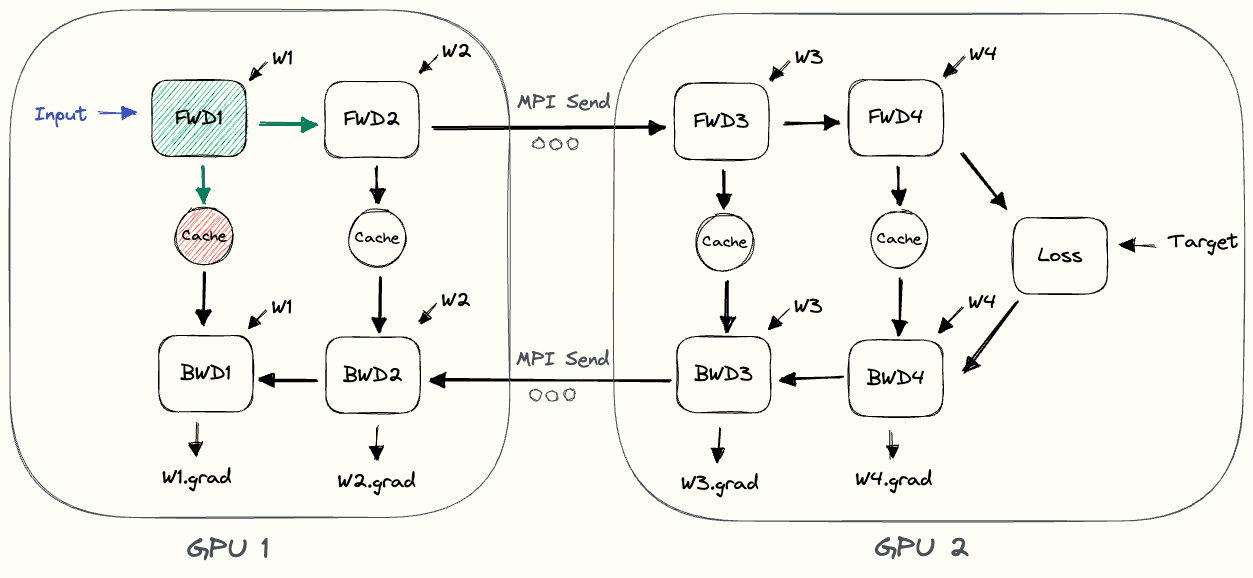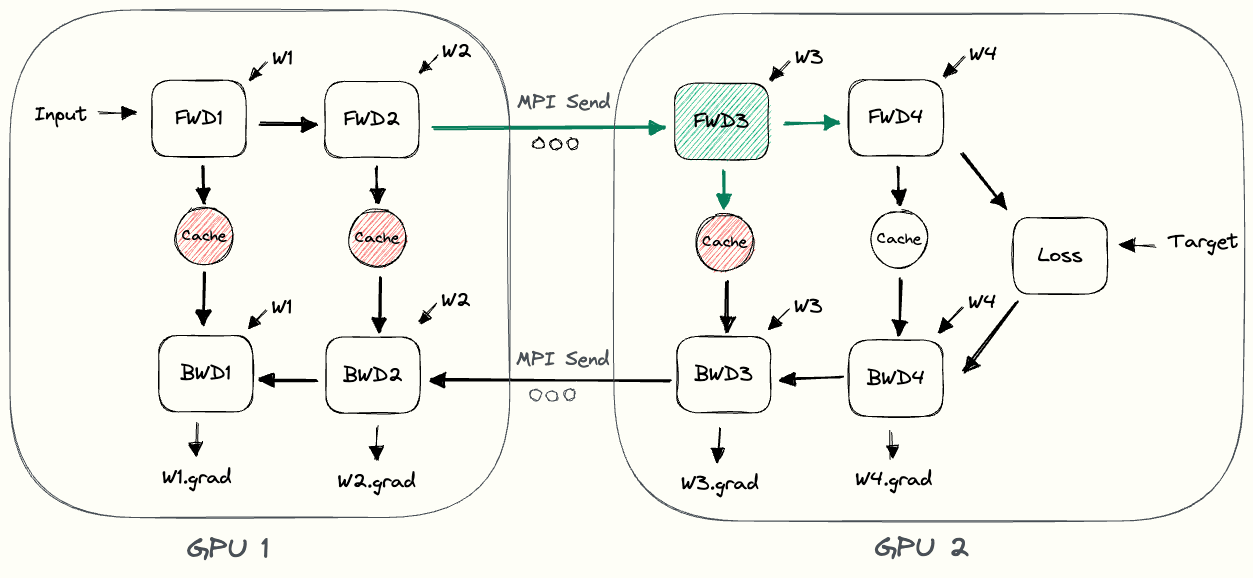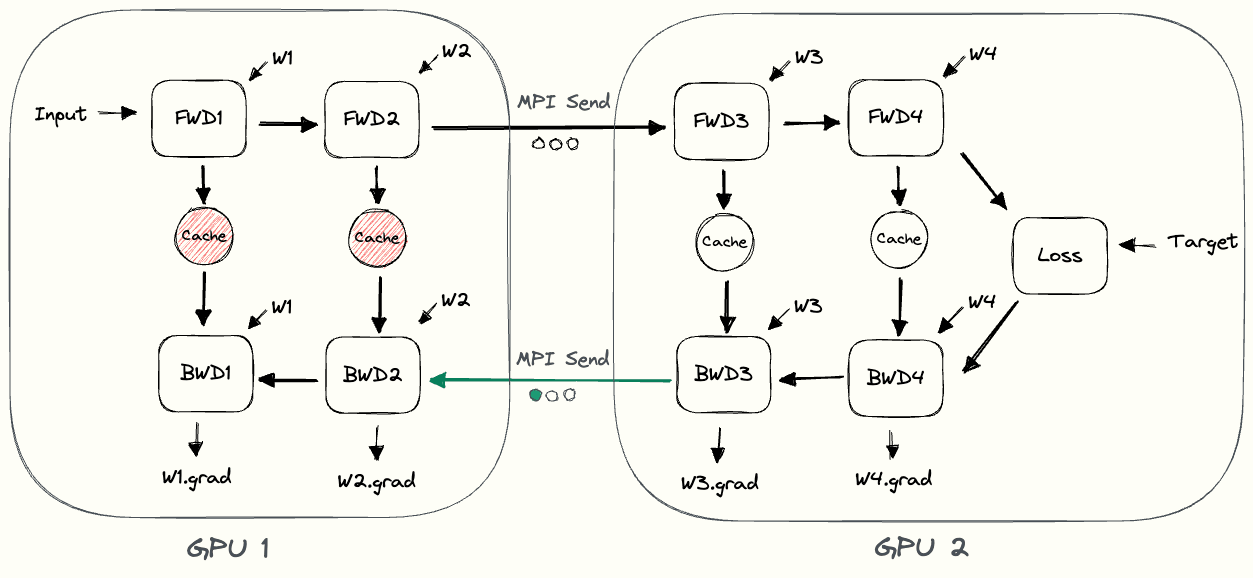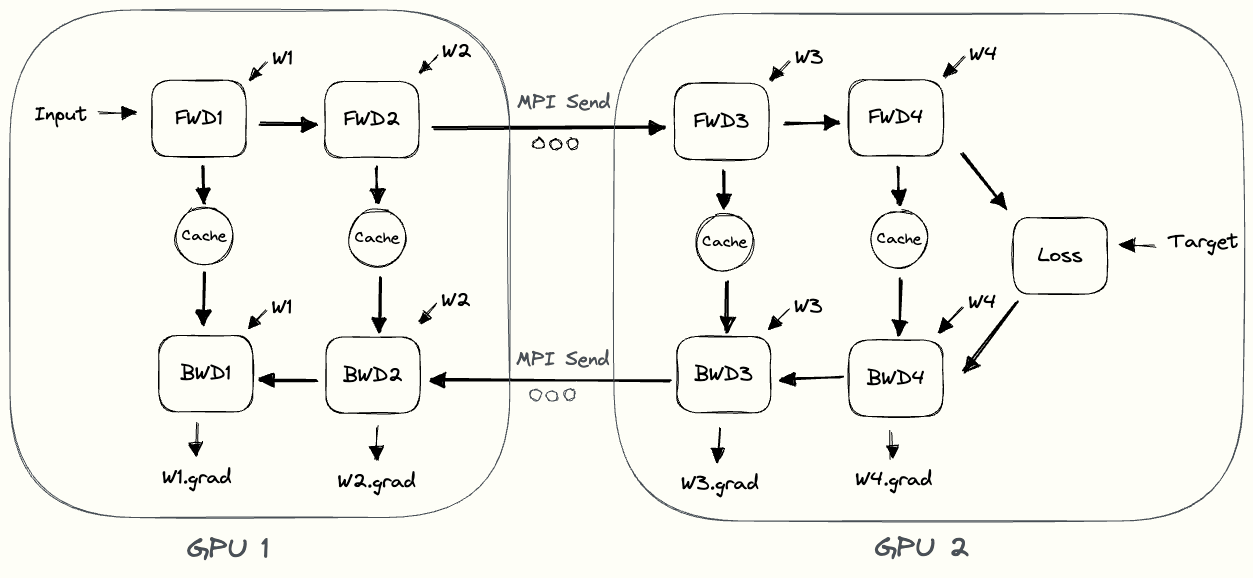
在上图中,我们可以观察到一些简单模型并行的低效率。
- GPU 利用率低:在任何给定时间,只有一个 GPU 处于繁忙状态,而另一个 GPU 处于空闲状态。低利用率表明可以通过将有用的工作分配给当前处于空闲状态的 GPU 来加快训练速度。
- 通信和计算不交错:当我们通过网络发送中间输出 (FWD) 和梯度 (BWD) 时,没有 GPU 执行任何操作。
- 高内存需求:GPU1 一直到最后都需要缓存整个批次的激活状态。如果批量很大,这可能会产生内存问题。
下面介绍 GPipe 算法,与简单流水并行算法相比,该算法的 GPU 利用率要高得多。
2. GPipe 算法
GPipe 通过将每个 minibatch 分割成更小、大小相等的 microbatches 来提高效率。我们可以为每个 microbatches 独立计算前向和反向传递。如果我们将每个 microbatches 的梯度相加,我们就会得到整个批次的梯度。该过程称为梯度积累。
由于每一层只存在于一个 GPU 上,因此 microbatches 梯度的累加可以在本地执行,无需任何通信。
让我们考虑一个跨 4 个 GPU 划分的模型。对于简单的管道并行性,最终的调度将如下所示:
| Timestep | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| GPU3 | FWD | BWD | ||||||
| GPU2 | FWD | BWD | ||||||
| GPU1 | FWD | BWD | ||||||
| GPU0 | FWD | BWD |
在任何给定时间点,只有一个 GPU 处于繁忙状态。此外,每个时间步骤都会花费相当长的时间,因为 GPU 必须为整个小批量运行前向传递。
使用 GPipe,我们现在将 minibatch 分成多个 microbatches,假设有 4 个。
| Timestep | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPU3 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU2 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU1 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 | ||||||
| GPU0 | F1 | F2 | F3 | F4 | B4 | B3 | B2 | B1 |
这里的 F1 意思是使用当前 GPU 上存储的层分区执行 microbatches 1 的前向传递。
由于模型各个层之间的依赖关系,流水线中还是存在没有进行任何有用工作的点,称为气泡,图中圈出来的部分。
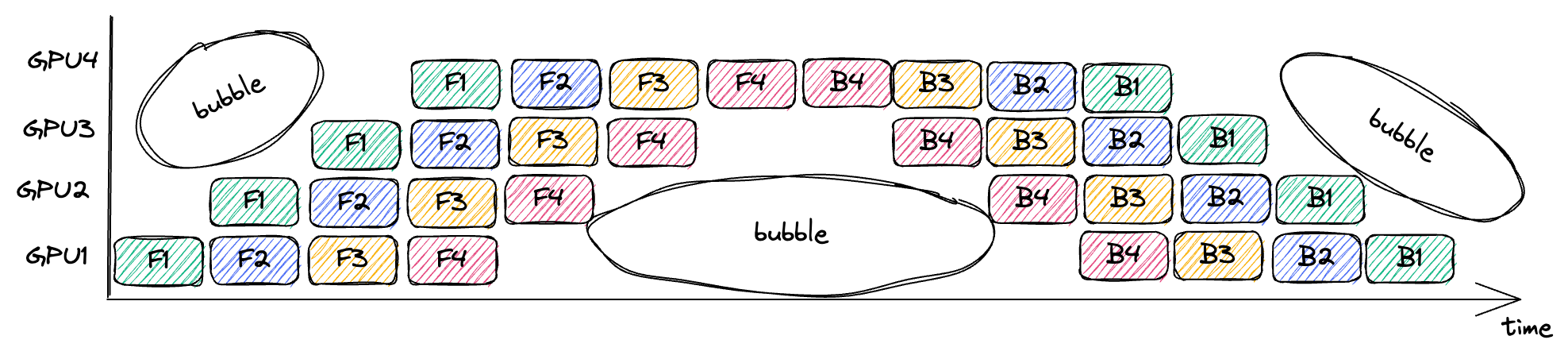
浪费在气泡上的时间比例取决于管道深度 n 和 microbatches 数量 m,其实就是计算图中气泡的面积占整体的比例:
1
−
2
n
m
2
n
(
m
+
n
−
1
)
=
1
−
m
m
+
n
−
1
1-\frac{2nm}{2n(m+n-1)}=1-\frac{m}{m+n-1}
1−2n(m+n−1)2nm=1−m+n−1m
因此,增加 m,即 microbatches 数量可以降低气泡的占比。
3. GPipe 空间复杂度
增加批量大小会线性增加缓存激活的内存需求,在 GPipe 论文中,作者利用 gradient checkpointing 来降低内存需求。在 gradient checkpointing 中,我们不会缓存计算梯度所需的所有激活,而是在反向传递过程中动态重新计算激活,这降低了内存需求但增加了计算成本。
假设所有层的大小大致相同,如果不执行 gradient checkpointing ,则缓存激活的空间复杂度为:
O
(
b
a
t
c
h
s
i
z
e
⋅
L
a
y
e
r
s
G
P
U
s
)
O(batchsize ⋅ \frac{Layers}{GPUs})
O(batchsize⋅GPUsLayers)
相反,执行 gradient checkpointing 只缓存层边界上的输入(即缓存从前一个 GPU 发送给我们的张量),这可以降低每个GPU的显存峰值需求,空间复杂度:
O
(
b
a
t
c
h
s
i
z
e
+
L
a
y
e
r
s
G
P
U
s
b
a
t
c
h
s
i
z
e
m
i
c
r
o
b
a
t
c
h
e
s
)
O(batchsize+ \frac{Layers}{GPUs}\frac{batchsize}{microbatches})
O(batchsize+GPUsLayersmicrobatchesbatchsize)

4. PipeDream 算法
PipeDream 在最终管道阶段完成相应的前向传递后立即开始 microbatches 的反向传递。我们可以在执行相应的反向传递后立即丢弃第 m 个 microbatches 的缓存激活。使用 PipeDream,此反向传递比在 GPipe 中发生得更早,从而减少了内存需求。
下面是 PipeDream 时间表的图,有 4 个 GPU 和 8 个 microbatches。蓝色框表示前向传递,以其 microbatches ID 进行编号,而反向传递则为绿色。
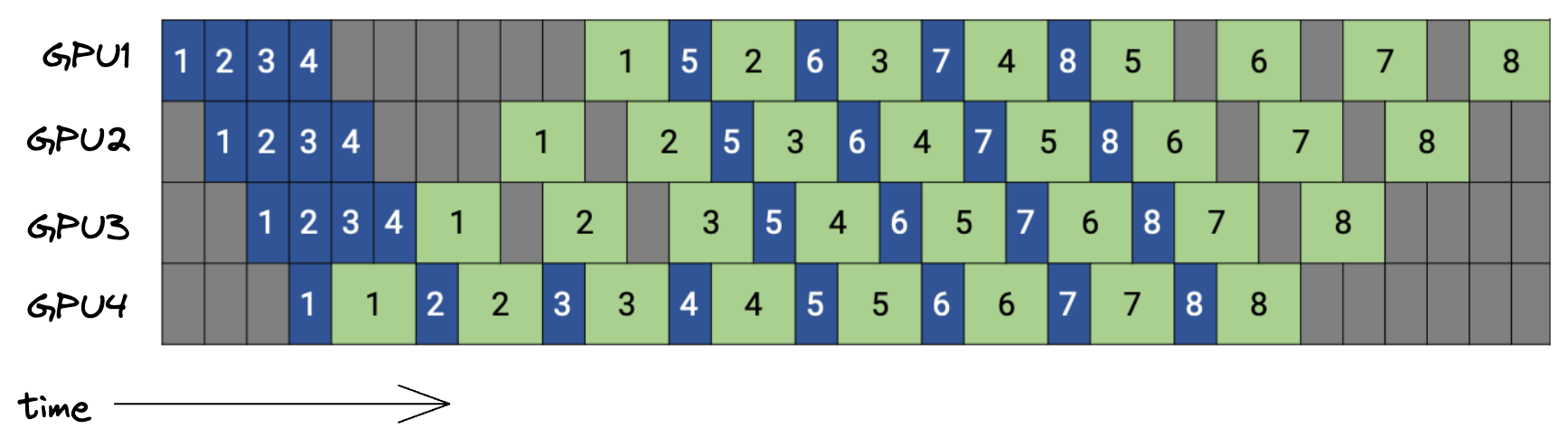
对于 GPipe 和 PipeDream,缓存激活的空间复杂度可以形式化为(无 gradient checkpointing):
O
(
max microbatches in flight
⋅
microbatch-size
⋅
L
a
y
e
r
s
G
P
U
s
O(\text{max microbatches in flight}⋅\text{microbatch-size}⋅\frac{Layers}{GPUs}
O(max microbatches in flight⋅microbatch-size⋅GPUsLayers
就气泡比例而言,PipeDream 和 GPipe 之间没有区别,由于 PipeDream 释放显存的时间更早,因此会降低对显存的需求。
5. 总结
流水线并行特别适用于那些层与层之间可以清晰划分的模型,例如由多个 Transformer 层组成的语言模型。这种方法已经被成功应用于训练大规模的预训练模型,如 BERT、GPT 系列等。
优点
- 内存优化:通过将模型分割成多个阶段并在不同的设备上处理,可以显著降低单个设备的内存需求,使得能够训练更大的模型。
- 计算效率:利用多个设备并行处理不同阶段的任务,可以大大提高计算效率。
- 扩展性:理论上可以无限扩展,只要设备足够,就能处理更大的模型。
缺点
- 通信开销:不同阶段之间的数据交换需要额外的通信开销,这可能会成为性能瓶颈。
- 负载均衡:如果各个阶段的计算复杂度不一致,可能会导致某些设备空闲而其他设备忙于计算,造成负载不平衡。
- 同步问题:需要精确控制各个阶段的同步,以确保数据正确传递,这增加了实现难度。
参考
[1] https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-intro-v2.html
[2] https://siboehm.com/articles/22/pipeline-parallel-training
[3] https://pytorch.org/tutorials/intermediate/TP_tutorial.html
[4] https://huggingface.co/docs/transformers/v4.15.0/parallelism
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤



















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











