






引言
人在学习某个操作时,不知道内部精确的动作,却可以学会操作,而且也不需要大量的示例,却可以学习的很好。
LFD:从状态和动作中学习。现实中,动作收集是很昂贵的操作。
如果Agent和环境交互产生动作,有延迟,有安全风险。
如果直接通过环境得到下一时刻的执行动作,不需要与环境交互,延迟风险小。
行为克隆可以通过直接从环境中推断下一个时刻的动作,不需要与环境交互。但是他需要大量的状态—动作对。
如何从现实中大量的没有动作的演示中进行行为克隆,即解决了数据来源的问题,也降低了延迟的风险。
BCO
BCO是基于模型的模仿学习,定义了两个模型:逆动力学模型和行为克隆策略。
逆动力学模型:从示教者的演示状态推断出执行的动作的模型。
行为克隆策略:通过状态—动作对训练一个模型,然后基于新状态得到需要执行的动作。
BCO也是一个学习的学习模型,有样本利用率高、学习到的模型可以跨任务转移。
模型架构
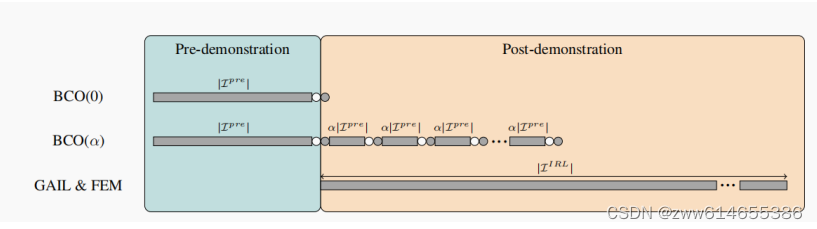
α=0
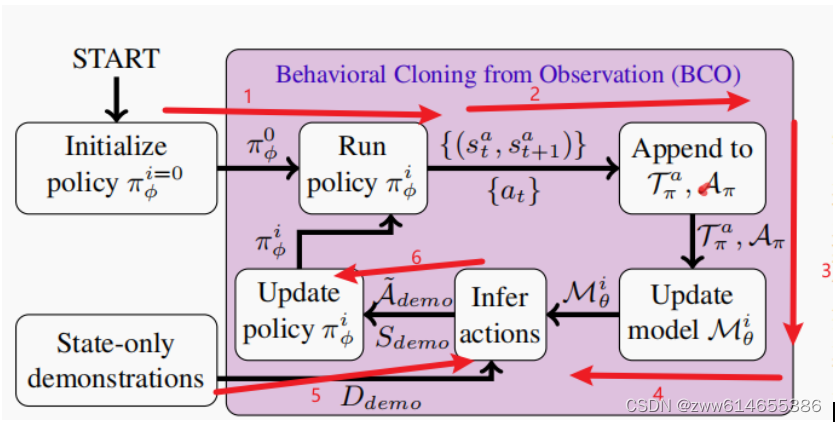
1训练时,按照随机策略,采集数据
2和3状态和动作对齐,放到Tπ和Aπ
4更新逆动力学模型
5抽取状态(st,st+1),逆动力学模型推断A~
6更新BC
α>0
在α=0的生成策略之后,按照确定策略(从BC生成的策略)继续与环境交互采集数据,优化M和π
pre-demostration是从演示轨迹中推算,post-demostration是在人工示教后还可以收集数据训练,按照正常的训练,状态来自于图像,而动作来自于行为克隆预测
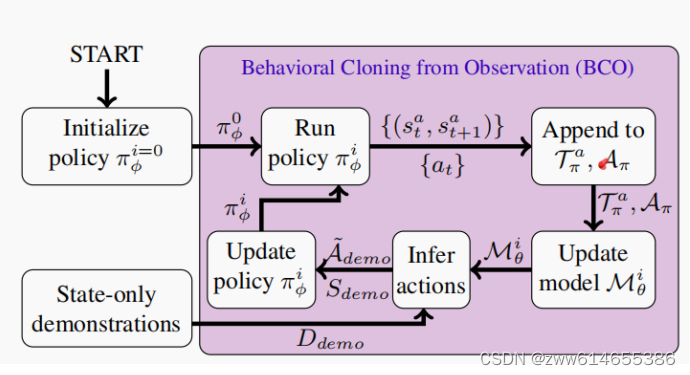
其中需要设计和训练的有两个模型:π(行为克隆模型)和M(逆动力学模型)
分布函数介绍
M:
假定操作空间是连续的且遵循高斯分布(正态分布),使用最大似然数估计获得模型参数θ
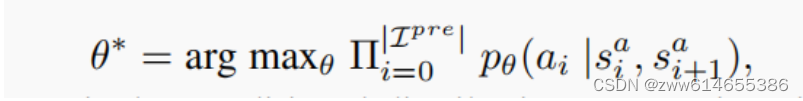
训练阶段:
输入:状态—动作对,训练模型
收敛判断方法;随机梯度的Adam变体
测试阶段:
输入:状态
输出:动作(这里的动作是网络输出的多个动作经过sofrmax计算概率后取最大的动作)
Π:
同样采取最大似然数估计参数
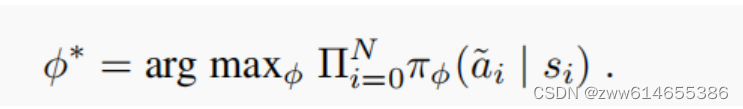
训练阶段:
输入一个任务的操作过程((s0,a0),(s1,a1),...,(sn,an)),经过训练得到一个模型。
测试阶段:
输入:状态(论文只是个方法论,没有说明是输入数据类型,数据集没法说)
输出:动作(动作维度,是gym中智能体的维度,代码也没说明是几维的)(softmax)

α是用于演示后控制迭代,与环境交互的数量
训练过程
BCO(α)70%的数据用于训练,30%的用于验证。当验证数据误差开始增加,就终止训练
其他的方法,所有数据都用于训练
不同任务模型:
CartPole:线性模型,1000次交互训练行为克隆策略和逆动力学模型
MountainCar:神经网络(两个隐含层,每个隐含层8个节点,LReLu激活函数),2000次交互训练
Reacher:神经网络(两个隐含层,100个LReLU节点的逆动力学模型;32个LReLU的行为克隆策略),5000次交互训练
Ant:神经网络与Reacher类似,交互数量为50万。
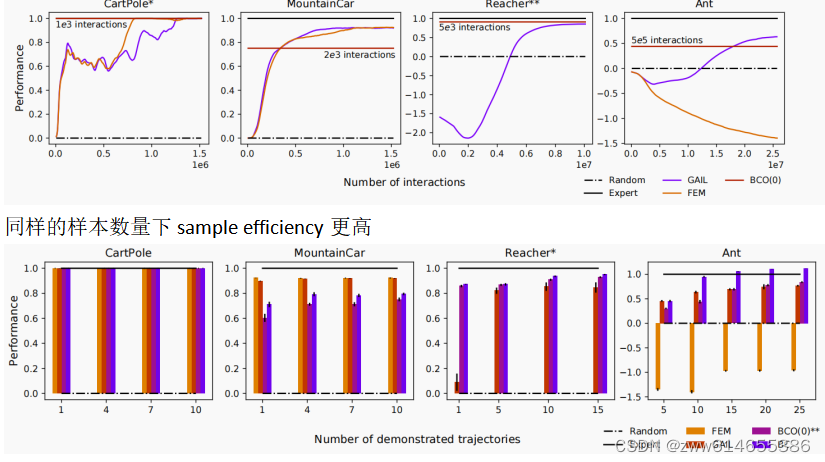
同样的样本数量下sample efficiency更高
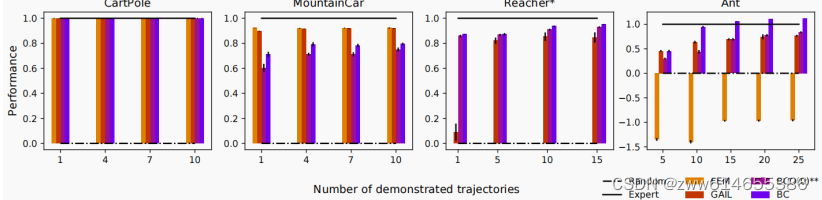
相比GAIL和BC,BCO在准确度上相差不大,但是BCO后期不需要Action,只需要状态即可
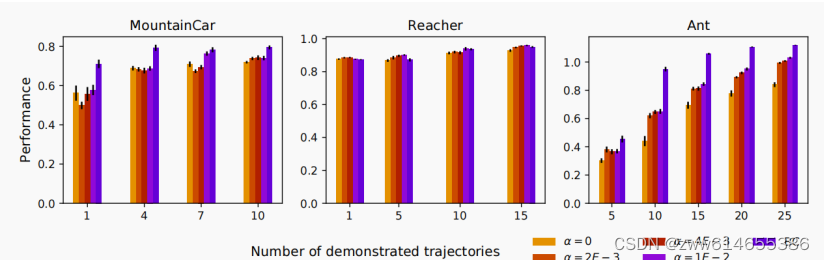
轨迹多,模仿学习效果好;轨迹采样点越多,模仿学习越好
BCO:提出了逆动力学模型,用与根据状态判断动作,测试中,判断动作的还是行为克隆。
结论:
BCO既不需要访问演示者动作,也不需要与演示后的换进交互,与其他技术相比,需要更少的演示后环境交互,能够以更少的延迟将合理的模仿策略执行。















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









