







Densely Connected Convolutional Networks
摘要:
最近的工作显示了,神经网络通过最近的层作为输入连接到后层,然后通过更深的层数,能够更有准确率,而且更有效率的收敛(即收敛更快),本文Densenet,就是通过前层的所有特征图作为后面每一层的输入,传统神经网络如果有L层就会有L层连接,但是Densenet会有L(L+1)/2个连接,Densenet会有几个
优点:1.减弱梯度消失2加强特征传播3鼓励特征重复利用4和持续的减少参数
成果:Densenet在目标识别的任务上(CIFAR-10,CIFAR-100, SVHN, and ImageNet),Densenet对于目前的大多数state of art的结果更进一步的提升,而且减少了参数量。
问题:1.为什么可以减弱梯度消失2加强特征传播和特征重复利用的作用在哪里
答:减弱梯度消失,是因为前面层直接跟后面Loss相连接(看一看什么是深度监督?)
代码:github:https://github.com/liuzhuang13/DenseNet.
介绍:
这篇文章的作者列出了这么几篇文章:ResNets [11] and Highway Networks [34],Stochastic depth [13],FractalNets [17],
作者总结出了一个规律:就是在这些文章都是用前层的特征作为输入给后层的shot connection的方式 (灵感来源:发现共性)
问题:
作者反直觉的感觉就是:1.Densenet参数比较少(为什么?)2.传统的卷积神经网络,从前层到后层,会有一些状态的改变,会保留下来一些信息,同时也会丢掉一些信息(不是很理解?)3.Resnet通过相加的方式保留了一些信息,但是Resnet会有很多冗余的信息(为什么冗余?),而且每一层都有自己的参数,所以参数量大(Densenet每层没有自己的参数吗?)4.Densenet直接区分加入到网络中的信息和需要保留的信息(怎么区分的?)5.Densenet非常的窄,加入一部分特征到收集网络,另一部分特征保持不变(收集网络是什么?,保持不变是什么意思?)
每层都可以直接访问损失函数和原始输入信号的梯度,从而导致隐含的深层监督(什么叫直接访问损失和原始输入信号梯度,深度监督是什么?)
相关工作:
highway network使用跳跃连接(bypass-ing paths)和门神经元使得训练深层网络不是很难(bypass-ing paths是训练深层网络的关键点)
resnet也是使用了bypass-ing paths
stochastic depth可以训练1202层神经网络:stochastic depth应该是随机停掉一些层的训练,(这个证明了并不是所有的层都是必要的)
resnet会有冗余(??)
我们的论文部分受到这一观察的启发。 具有预激活的ResNets还有助于训练具有> 1000层的最先进网络(什么叫预激活)
An orthogonal的使网络更深的方法是使用skip connection,增加网络的宽度可以提升网络的表现(使用更宽的宽度为什么可以增加深度?)
Densenet并不是用特别深或者特别宽的网络,而是,融合不同层的特征给后面的层,可以增加输入的不变性,(但是为什么可以提高训练的效率?)(Densenet与googlenet的区别在哪里)
介绍了一些现有的网络:NIN,深度监督(DSN),Ladder network, DFNs augmentation of networks with pathways
DenseNets
第一段主要是讲resnet的特点:
1.通过跳跃连接层来进行连接,ResNets的一个优点是梯度可以直接通过身份函数从后面的层流到更早的层(为什么后层梯度直接传到前层是一个优点?什么是身份函数)
2.然而,H`的标识函数和输出通过求和组合,这可能阻碍网络中的信息流。(求和为什么会阻碍网络中的信息流)
Dense connectivity.
这一段讲的是densenet的实施方法:
1.为了进一步的提升层间的信息流,将之前层的所有特征融合,作为下一层的输入,为了便于实现,我们融合了多个H(.)成为单一 的张量,H()表示经过卷积,池化,激活函数激活,或者BN等操作
Composite function.
受[12]激发,我们定义了H(.)作为composite function,它是由BN,relu,和3x3卷积组成的,([12]到底激发了作者什么?)
pooling layers
pooling层是必要的 ,由于特征的不同,所有使用了几块不同的denseblocks,然后中间接转换层,这个转换层是由bn层,接一个1x1的卷积层和一个2x2的池化层(为什么这么接?)
Growth rate
如果每个函数H`产生k个特征映射,则第i个层具有k 0 + k×(L- 1)(这个公式为什么这么算,没明白)输入feature-maps,其中k 0是输入层中的通道数。 DenseNet与现有网络架构之间的一个重要区别是,DenseNet可以具有非常窄的层,例如k = 12.我们将超参数k称为网络的增长率。 我们在第4节中表明,相对较小的增长率就足够可以获得the state of art的结果了(这个增长率指的是feature map的channel吗?较小增长率和较窄的网络宽度是这个densenet参数量少的原因吗?)
解释:
我们对此的解释是:可以将特征映射视为网络的全局状态(什么叫映射全局hangtag)。 每个层都将自己的k个特征映射添加到此状态。 增长率规定了每层为全局状态做出多少新信息。 一旦编写,全局状态可以从网络中的任何地方访问,并且与传统网络体系结构不同,不需要在层与层之间复制它。(这里的解释是完全没有懂)
Bottleneck layers
虽然每个层仅生成k个输出要素图,但它通常具有更多输入。 在[37,11]中已经注意到,在每个3×3卷积之前可以引入1×1卷积作为瓶颈层以减少输入特征图的数量,从而提高计算效率。 我们发现这种设计对DenseNet特别有效,我们称这个瓶颈层为网络,即BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)版本的H`, 作为DenseNet-B(版本A应该就是没有1x1的卷积)。 在我们的实验中,我们让每个1×1卷积产生4k特征映射。(主要思想是1x1卷积来减少参数量,是在dense block内部实施)
compression:
进一步压缩,在transition layer使用压缩因子
为了进一步提高模型的紧凑性,我们可以减少过渡层的特征图数量。 如果密集块包含m个特征映射,我们让下面的过渡层生成bθmc输出特征映射,其中0 <θ≤1被称为压缩因子。 当θ= 1时,跨过渡层的特征图的数量保持不变。 我们将DenseNet的θ<1称为DenseNet-C,我们在实验中设置θ= 0.5。当使用θ<1的瓶颈和过渡层时,我们将模型称为DenseNet-BC。(使用压缩因子的版本是版本c,压缩因子和conv1x1相结合是的版本BC)
Implementation Details.
1.实验了两种类型的Densenet:1.基本型 2.BC版本
2.结构:Imagenet数据集上:使用4个dense block
其他数据集:3个dense block
具体细节:
其他数据集:
1.在除ImageNet之外的所有数据集上,我们实验中使用的DenseNet有三个密集块,每个块具有相同数量的层。 在进入第一个密集块之前,对输入图像执行16(或DenseNet-BC生长速率的两倍)输出通道的卷积。 (这里生长速率还是不懂)
2.对于内核大小为3×3的卷积层,输入的每一侧都按零填充一个像素,以保持特征图大小固定。 我们使用1×1卷积,然后使用2×2平均池化作为两个连续密集块之间的过渡层。
3.在最后一个密集块的末尾,执行全局平均池化,然后附加softmax分类器。 三个密集块中的特征映射大小分别为32×32,16×16和8×8。 我们尝试了基本的DenseNet结构,配置{L = 40,k = 12},{L = 100,k = 12}和{L = 100,k = 24}。 对于DenseNet BC,评估具有配置{L = 100,k = 12},{L = 250,k = 24}和{L = 190,k = 40}的网络。
imagenet数据集:
在我们在ImageNet上的实验中,我们在224×224输入图像上使用具有4个密集块的DenseNet-BC结构。 初始卷积层包括尺寸为7×7的2k圈,步幅为2; 所有其他层中的特征图的数量也遵循设置k。 我们在ImageNet上使用的确切网络配置如表1所示。
Experiments:
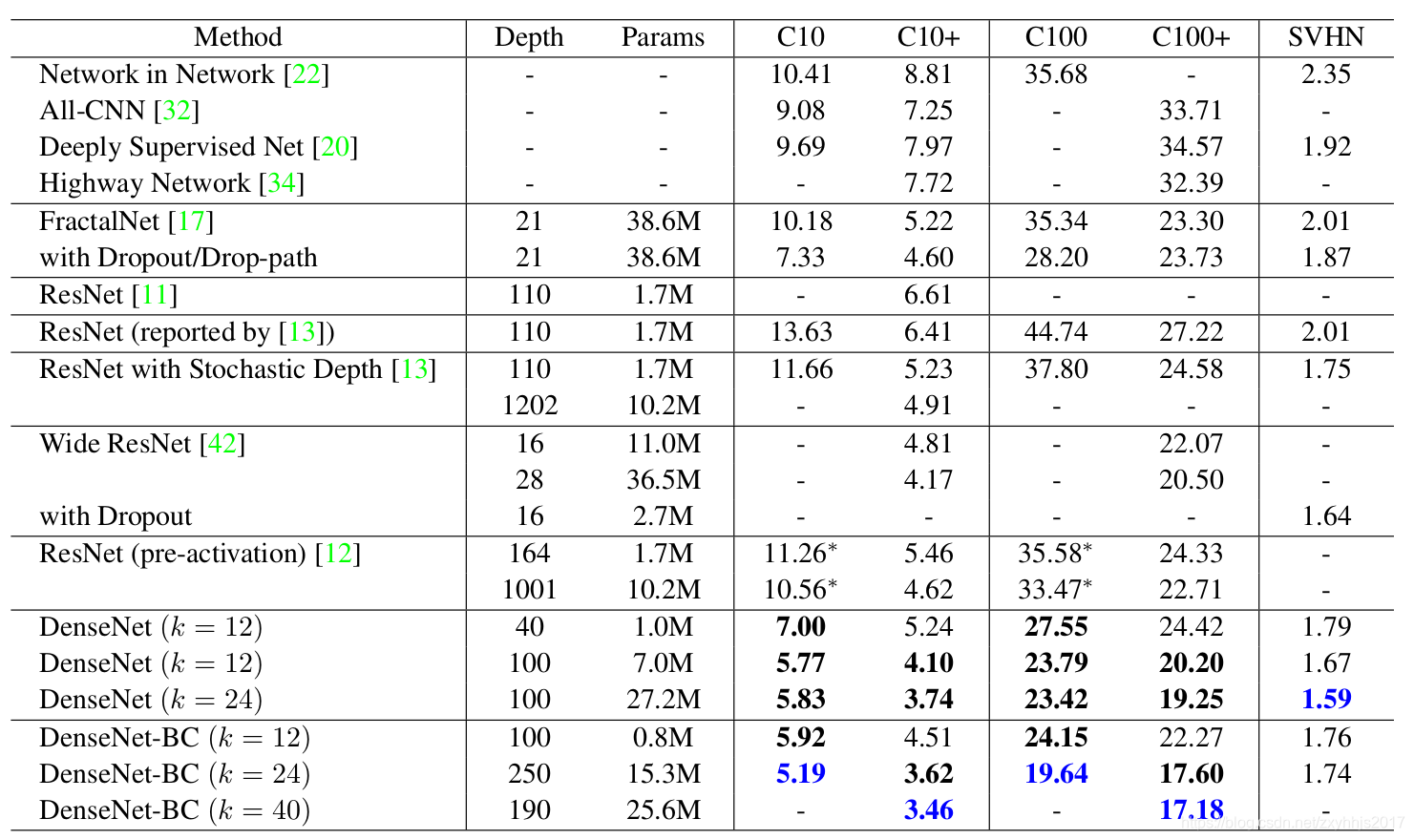
表2:CIFAR和SVHN数据集的错误率(%)。 k表示网络的增长率。 超过所有竞争方法的结果是粗体,总体最佳结果是蓝色。 “+”表示标准数据增强(翻译和/或镜像)。 *表示我们自己运行的结果。 使用Dropout获得没有数据增强(C10,C100,SVHN)的DenseNets的所有结果。 DenseNets使用比ResNet更少的参数,实现更低的错误率。 如果没有数据扩充,DenseNet的表现会更好。
4.1:
Datasets
cifar10
对于cifar10(32X32大小),用了5万张训练集里面的5000张作为验证集,用了[11, 13, 17, 22, 28, 20, 32, 34]数据增强的方法,使用减通道均值和标准方差的预处理方法(channel mean的作用?)
SVHN
(32X32size),选择验证集错误率较低的模型,并记录测试错误,然后使用了(0~255)的归一化(为什么上面是减均值,和标准方差,这里就是0~255归一化?)
Imagenet
ILSVRC 2012分类数据集[2]包含120万个用于训练的图像,以及50,000个用于验证的图像,来自1,000个类别。 我们采用与[8,11,12]中相同的数据增强方案来训练图像,并在测试时应用尺寸为224×224的singe-crop或10-crop(这两个名词是什么意思)。 在[11,12,13]之后,我们记录了验证集上的分类错误。
4.2
training
使用随机梯度下降(SGD)训练所有网络。 在CIFAR和SVHN上,我们分别使用批量大小64训练300和40个时期。 初始学习率设置为0.1,并且在训练时期总数的50%和75%处除以10。 在ImageNet上,我们训练90个时期的模型,批量大小为256.学习率最初设置为0.1,并且在30和60epoch下降10倍。注意,DenseNet的简单实现可能包含内存效率低下。 要减少GPU的内存消耗,请参阅我们关于DenseNets的内存高效实现的技术报告[26]。(它这些学习率的设置都是根据什么而来的?是否可以用到我的网络中,这些低消耗是什么意思?)
在[8]之后,我们使用10 -4的重量衰减和0.9的Nesterov动量[35]而没有抑制(这里的抑制在动量中指的是什么)。 我们采用[10]引入的权重初始化。 对于没有数据增强的三个数据集,即C10,C100,SVHN(权重的初始化还有权重的衰减对于网络会有什么影响?)随机失活设置为0.2在每一个卷积层后(除了第一层)
总结:在模型的框架基本都确定的情况下进行精调,争取调出更高的精度(比如学习率下降方法,随机失活,预处理方法,权重衰减)
4.3.
Classification Results on CIFAR and SVHN
Accuracy
可能最引人注目的趋势可能源自表2的底行,其表明L = 190和k = 40的DenseNet-BC在所有CIFAR数据集上始终优于现有最好的水平。 它在C10 +上的错误率为3.46%,在C100 +上的错误率为17.18%,显着低于更宽的ResNet架构所实现的错误率[42]。 我们在C10和C100上的最佳结果(没有数据增加)更令人鼓舞:两者都比具有下降路径正则化的FractalNet低近30%[17]。 在SVHN上,使用随机失活,L = 100和k = 24的DenseNet也超过了广泛的ResNet所取得的当前最佳结果。然而,250层DenseNet-BC并没有进一步提高其性能。 这可以解释为SVHN是相对容易的任务,并且极深的模型可能过度适应训练集。
总结:作者认为更深的网络可能对学习容易的任务并没有太多的帮助
Capacity
没有compression或denseblock,一般趋势是当L和k增加时,DenseNets表现更好。 我们将此归因于模型容量的相应增长。 C10 +和C100 +最能证明这一点。 在C10 +上,当参数数量从1.0M增加到7.0M到27.2M时,误差从5.24%下降到4.10%,最后变为3.74%。 在C100 +上,我们观察到类似的趋势。 这表明DenseNets可以利用更大更深层模型的增强的表征能力。 它还表明它们不会受到过度拟合或残留网络的优化困难[11]。
总结:增强参数量可以增强表征能力,而且不会像residual net那样受到过拟合或者优化困难的影响(residual net到底会有怎样的问题?)
Parameter Efficiency
表2中的结果表明,DenseNets比其他架构(特别是ResNets)更有效地利用参数。 具有dense block和transition layer 尺寸减小的DenseNet BC特别具有参数效率。 例如,我们的250层模型仅具有15.3M参数,但它始终优于其他模型,例如具有超过30M参数的FractalNet和Wide ResNets。 我们还强调,L = 100和k = 12的DenseNet-BC实现了相当的性能(例如,C10 +上的误差为4.51%vs 4.62%,C100 +上的误差为22.27%和22.71%),因为1001层预激活ResNet使用90% 参数更少。 图4(右图)显示了这两个网络在C10 +上的训练损失和测试错误。 1001层深度ResNet收敛到较低的训练损失值,但类似的测试误差。 我们将在下面更详细地分析这种效应。

图4:左:比较DenseNet更改结构的C10 +的参数效率。 中:比较DenseNet-BC和(预激活)ResNets之间的参数效率。 DenseNet-BC需要大约1/3的参数作为ResNet才能达到相当的精度。 右:具有超过10M参数的1001层预激活ResNet [12]和仅具有0.8M参数的100层DenseNet的训练和测试曲线
overfitting
更有效地使用参数的一个积极的影响是DenseNets不易过度拟合的趋势。 我们观察到,在没有数据增加的数据集上,DenseNet架构相对于先前工作的改进尤其明显。 在C10上,改进表示误差从7.33%到5.19%相对减少29%。 在C100上,从28.20%降至19.64%,降幅约为30%。 在我们的实验中,我们在单个设置中观察到潜在的过度拟合:在C10上,通过将k = 12增加到k = 24而产生的参数的4倍增长导致误差从5.77%适度增加到5.83%。 DenseNet-BC的dense block和compression似乎是应对这一趋势的有效方法。(densenet为什么相对于resnet不容易过拟合?)
总结:densenet不容易过拟合,但是唯一一个可以影响densenet过拟合的设置是densenet里的k设置。
4.4.
Classification Results on ImageNet
我们在表3中报告了ImageNet上DenseNets的单作物和10作物验证错误。图3显示了DenseNets和ResNets的单作物前1验证错误与参数数量(左)和FLOP的关系( 对)。 图中显示的结果表明,DenseNets的性能与最先进的ResNets相当,同时需要的参数和计算量要少得多,以达到相当的性能。 例如,具有20M参数模型的DenseNet-201产生与具有超过40M参数的101层ResNet类似的验证错误。 从右侧面板可以观察到类似的趋势,它将验证错误绘制为FLOP数量的函数:需要与ResNet-50一样多计算的DenseNet与ResNet-101相同,这需要两倍的时间计算。
总结:就是densenet能够使用个更少的参数达到与resnet表现相当的一个水平

图3:ImageNet验证数据集上的DenseNets和ResNets前1错误率(singe-crop-测试)的比较,作为学习参数(左)和测试时间(右)中的FLOP的函数。
值得注意的是,我们的实验设置意味着我们使用针对ResNets优化但不针对DenseNets的超参数设置。 可以想象,更广泛的超参数搜索可以进一步改善ImageNet上的DenseNet的性能。
总结:作者的超参优化,只是针对于resnet,并不针对于densenet,所以超参的优化能够使densenet训练结果更好(超参优化使网络结果更好,这是不可忽视的一点)
5.Disccusion
compactness
图4中的左侧两个图显示了一个实验结果,该实验旨在比较DenseNets的所有变体(左)和类似的ResNet架构(中间)的参数效率。 我们在C10 +上训练多个不同深度的小型网络,并将其测试精度绘制为网络参数的函数。 与其他流行的网络架构(如AlexNet [16]或VGG-net [29])相比,具有预激活的ResNets使用更少的参数,同时通常可以获得更好的结果[12]。 因此,我们将DenseNet(k = 12)与此架构进行比较。 DenseNet的训练设置与上一节中的保持一致。
总结:densenet与预激活的resnet进行比较,因为预激活的resnet比alexnet和vgg-net的参数量还要少
Implicit Deep Supervision
densenet执行了一种深度监督(什么叫深度监督?)
DenseNets以隐式方式执行类似的深度监督:网络顶部的单个分类器通过最多两个或三个过渡层为所有层提供直接监督。 然而,DenseNets的损失函数和梯度基本上不那么复杂,因为在所有层之间共享相同的损失函数。(具体监督是怎么监督的,过度层?为什么损失函数不复杂?)
Stochastic vs. deterministic connection.
stochastic depth regularization of residual networks 随机的选取某些层不用,因为pooling层永远不会不被使用,所以这个一定程度上跟densenet有点相似,
Feature reuse:
完全没看懂
6.conclusion
1.densenet 没有优化困难(为什么?)
2.densenet随着参数量的增加,表现提高,而且不会过拟合
3.densenet在很多数据集上达到了the state of art的表现
4.densenet需要更少的参数量,就可以达到the state of art的表现
5.densenet的超参数还可以优化,因为文章里的densenet超参数只是针对resnet来设置的
在遵循简单的连接规则的同时,DenseNets自然地整合了身份映射(identity mappings这是什么?),深度监督和多样化深度的属性。 它们允许在整个网络中重用特征,因此可以学习更紧凑(为什么重用特征,就可以更紧凑难道不是用一些技巧吗?),并且根据我们的实验,可以获得更准确的模型。 由于其紧凑的内部表示和减少的特征冗余(为什么特征不冗余),DenseNets可能是基于卷积特征的各种计算机视觉任务的良好特征提取器,例如[4,5]。 我们计划在未来的工作中使用DenseNets研究这种特征转移。
幕布的总结:
- Densenet
- 特点
1.减弱梯度消失2.加强特征传播3.鼓励特征重复利用,增加输入不变性(什么是不变性?)4.和持续的减少参数 5.densenet很窄:(为什么?,这里的窄是指什么?) - 与现有网络的共性
深度监督:类似于深度监督的方式更容易收敛(阅读理解深度监督)highway network:跳跃连接,门神经元stochastic depth:随机停掉一些网络层,使得跳跃连接成为可能增加网络宽度:可以提升网络表现。不容易出现退化现象(即跳跃连接层)灵感:作者总结出了一个规律:就是在这些文章都是用前层的特征作为输入给后层的shot connection的方式 (灵感来源:发现共性) - 与现有网络的区别
介绍了一些现有的网络:NIN,深度监督(DSN),Ladder network, DFNs augmentation of networks with pathwaysresnet和传统的卷积神经网络:容易产生有冗余的信息(需要去读resnet???)Densenet直接区分加入到网络中的信息和需要保留的信息:如何区分的??resnet:是通过相加的一些方式,来得到输出,densenet是使用concate(相加会阻碍网络中的信息流) - 结构

growth rate:就是每个卷积层(这里的卷积是指下面的卷积结构)后,产生k个feature maps卷积结构:BN,relu,3x3conv(为什么这么接)转换层结构:这个转换层是由bn层,接一个1x1的卷积层和一个2x2的池化层(因为pool尺寸不同,你无法将不同的pool后的特征进行融合)实际上就是:卷积层-转换层-卷积层-转换层......这种类似的结构 - 精调方法:
1比如dropout,学习率是如何下降的,等等,当需要精调网络的时候可以回过头来看这部分笔记 - 总结
1.densenet利用在3x3卷积前加入1x1卷积和使用transition layer可以有效的减少参数量防止过拟合2.densenet仅仅需要较低的参数量就可以达到跟很多网络相娉美的地位3.随着网络参数增强能够提高模型表现4.充分利用了特征,减轻梯度消失问题,加强了特征层与层之间的传递
- 特点

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









