






机器学习最重要的任务,是根据一些己观察到的证据(例如训练样本)来 对感兴趣的未知变量(例如类别标记)进行估计和推测。概率模型(probabilistic model)提供了一种描述框架?将学习任务归结于计算变量的概率分布.
直接利用概率求和规则消去变量 显然不可行,因为即便每个变量仅有两 种取值的简单问题,其复杂度己至少是 0(2IYI+IRI) 另一方面,属性变暨之间往 往存在复杂的联系,因此概率模型的学习,即基于训练样本来估计变量分布的 参数往往相当困难.为了便于研究高效的推断和学习算法,需有一套能简洁紧 凑地表达变量间关系的工具.
慨率围棋型(probabilistic graphical model) 是一类用图来表达变量相关关 系的概率模型.它以图为表示工具,最常见的是用一个结点表示一个或一组 随机变量,结点之间的边表示变量间的概率相关关系,即"变量关系图"根 据边的性质不间,概率图模型可大致分为两类:第一类是使用有向无环图表 示变量间的依赖关系,称为有向圈模型或贝叶斯网 (Bayesian network); 第二类 是使用无向国表示变量间的相关关系,称为无向图模型或马尔可夫网 (Markov network).
隐马尔可夫模型 (Hidden Markov Model ,简称 HMM) 是结构最筒单的动态 贝叶斯网 (dynamic Bayesian network) ,这是一种著名的有向图模型?主要用于 时序数据建模,在语音识别、自然语言处理等领域有广泛应用.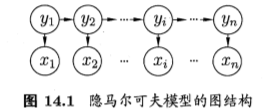
马尔可夫随机场(Markov Random Field ,简称 MRF)是典型的马尔可夫网, 这是一种著名的无向圈模型.圈中每个结点表示一个或一组变量,结点之间 的边表示两个变量之间的依赖关系.马尔可夫随机场有二组势函数(potential functions) ,亦称"因子" (factor) ,这是定义在变量子集上的非负实函数 主要 用于定义概率分布函数.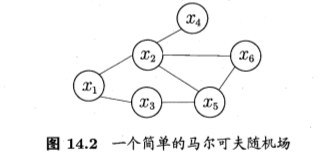
"全局马尔可夫性" (global Markov property): 给定两个变量子集的分 离集,则这两个变量子集条件独立.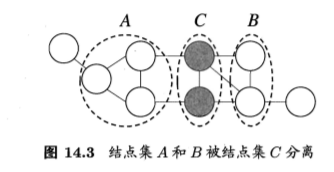
条件随机场(Conditional Random Field ,简称 CRF) 是一种判别式无向图 模型. 14.1 节提到过?生成式模型是直接对联合分布进行建模,丽判别式模型则 是对条件分布进行建模.前面介绍的隐马尔可夫模型和马尔可夫随机场都是生 成式模型,而条件随机场则是判别式模型.

条件随机场和马尔可夫随机场均使用团上 的势函数定义概率,两者在形式上没有显著区别;但条件随机场处理的是条件 概率.而马尔可夫随机场处理的是联合概率.
基于概率图模型定义的联合概率分布?我们能对目标变量的边际分 (marginal distribution) 或以某些可观测变量为条件的条件分布进行推断.条 件分布我们已经接触过很多,例如在隐马尔可夫模型中要估算观测序列 在给 定参数入下的条件概率分布.边际分布则是指对无关变量求和或积分后得到结 果,例如在马尔可夫网中,变量的联合分布被表示成极大团的势函数乘积,于 是,给是参数。求解某个变量 的分布,就变成对联合分布中其他无关变量进 行积分的过程,这称为"边际化" (marginalization).对概率图模型,还需确定具体分布的参数,这称为参数估计或参数学习问 题,通常使用极大似然估计或最大后验概率估计求解.但若将参数视为待推测 的变量,则参数估计过程和推断十分相似,可以"吸收"到推断问题中.因此, 下面我们只讨论概率图模型的推断方法.
信念传播(Belief Propagation)算法将变量消去法中的求和操作看作一个消 息传递过程,较好地解决了求解多个边际分布时的重复计算问题.具体来说,变 量消去法通过求和操作
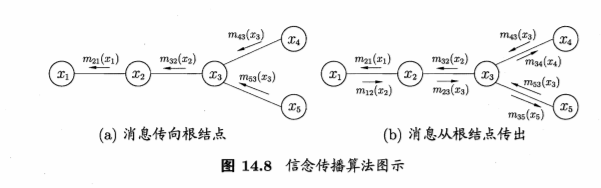
精确推断方法通常需要很大的计算开销,因此在现实应用中近似推断方法 更为常用.近似推断方法大致可分为两大类:第一类是采样(sampling) ,通过使 用随机化方法完成近似;第二类是使用确定性近似完成近似推断,典型代表为 变分推断(variational inference)
吉布斯采样(Gibbs sampling)有时被视为 MH 算法的特例,它也使用马尔 可夫链获取样本,而该马尔可夫链的平稳分布也是采样的目标分布 p(x). 具体 来说,假定 = {Xl X2 γ.. XN 目标分布为 p(x) 在初始化 的取值后,通过 循环执行以下步骤来完成采样:

变分推断通过使用己知简单分布来逼近需推断的复杂分布,并通过限制近 似分布的类型,从而得到 种局部最优、但具有确定解的近似后验分布.
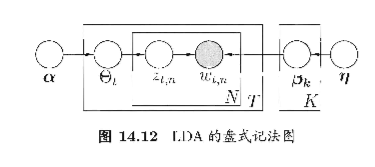
在图 14 10(b) 中,相互独立的、由相同机制生成的多个变量被放在一个方框(盘)内, 并在方框中标出类似变量重复出现的个数 N; 方框可以嵌套 通常用阴影标注 出已知的、能观察到的变量,如图 14 10 中的变 X. 很多 习任务中,对属 性变量使用盘式记法将使得图表示非常简洁.
在实践中使用变分法时,最重要的是考虑如何对隐变量进行拆解,以此假 设各变量子集服从何种分布,在此基础上套用式(14 .40) 的结论再结合 EM 算法 即可进行概率图模型的推断和参数估计.显然,若隐变量的拆解或变量子集的 分布假设不当,将会导致变分法效率低、效果差.
话题模型(topic model) 是一族生成式有向图模型,主要用于处理离散型的 数据(如文本集合) ,在信息检索、自然语言处理等领域有广泛应用.隐狄利克 雷分配模型(Latent Dirichlet Allocation ,简称 LDA) 是话题模型的典型代表. 我们先来了解一卡话题模型中的几个概念:词 (word) 、文档(document) 话题(topic). 具体来说,"词"是待处理数据的基本离散单元,例如在文本处理 任务中?一个词就是一个英文单词或有独立意义的中文词"文档"是待处理 的数据对象,它由一组词组成,这些词在文档中是不计顺序的,例如一篇论文、 一个网页都可看作一个文档;这样的表示方式称为"词袋" (bag-of-words). 据对象只要能用词袋描述,就可使用话题模型"话题"表示一个概念?具体表 示为一系列相关的词,以及它们在该概念下出现的概率.
















 6147
6147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









