







一、基础环境
1、环境介绍
操作系统:centos 7.9
jdk版本:8u291
hadoop版本:2.10.1
spark版本:2.4.8 (因为自建了hadoop 所以使用without-hadoop包)
spark下载地址:https://archive.apache.org/dist/spark/spark-2.4.8/
2、hadoop配置
https://blog.csdn.net/zyj81092211/article/details/118248361
3、上传软件包到服务器并解压重名为spark

二、spark on yarn
1、配置spark-env.sh
配置文件目录:/home/hadoop/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加如下:
export JAVA_HOME=/usr/local/java
export HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop/bin/hadoop classpath)
2、给文件添加执行权限
chmod +x bin/*
chmod +x sbin/*

3、配置hadoop hadoop yarn-site.xml

vi yarn-site.xml
添加如下:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
4、复制spark-2.4.8-yarn-shuffle.jar到yarn下
cp /home/hadoop/spark/yarn/spark-2.4.8-yarn-shuffle.jar /home/hadoop/hadoop/share/hadoop/yarn/lib/
5、重启hadoop集群
stop-all.sh
start-all.sh
6、测试
cd /home/hadoop/spark
client模式:
./bin/spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.8.jar 10
cluster模式:
./bin/spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.8.jar 10
三、spark standalone
1、修改spark-env.sh
vi /home/hadoop/spark/conf/spark-env.sh
添加如下:
export SPARK_MASTER_HOST=10.99.99.200
2、修改slaves文件
cp /home/hadoop/spark/conf/slaves.template /home/hadoop/spark/conf/slaves
vi /home/hadoop/spark/conf/slaves
添加如下:
10.99.99.200
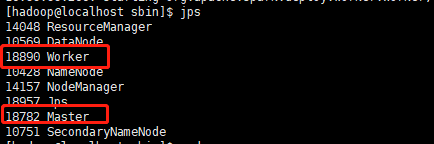
3、启动spark standalone集群
/home/hadoop/spark/sbin/start-all.sh















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









