






目录
3.如果以上使用方法仍不起作用,可以尝试修改虚拟机网络模式。
1.在使用systemctl status dhcpd启动命令时报错编辑
获取ip后,使用vi打开/etc/dhcp/dhcpd.conf
2.在虚拟网络编辑器中的更改设置中,关闭VMnet1网卡中的DHCP服务
前言
在麒麟操作系统中部署dhcp服务中,难免会遇到错误,错误可能导致服务无法部署。本篇将分析在部署dhcp过程中可能会遇到的错误并给出部分解决方式。
具体安装方法请参考
https://blog.csdn.net/m0_69493559/article/details/137754821
一.在安装dhcp服务中出现的网络问题

在初次安装使用yum命令安装DHCP服务时,可能会遇到一些网络错误。
1.查看虚拟机是否连接网络
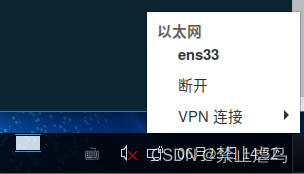
2.在主机控制面板中查看虚拟网卡是否禁用
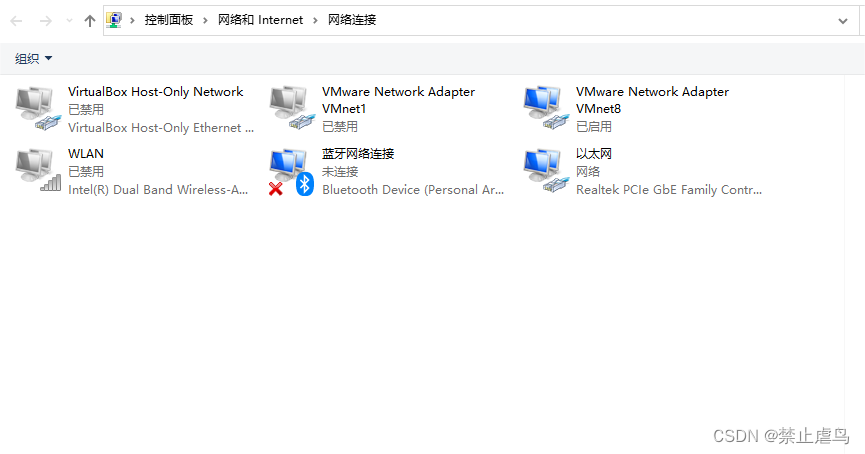
3.如果以上使用方法仍不起作用,可以尝试修改虚拟机网络模式。
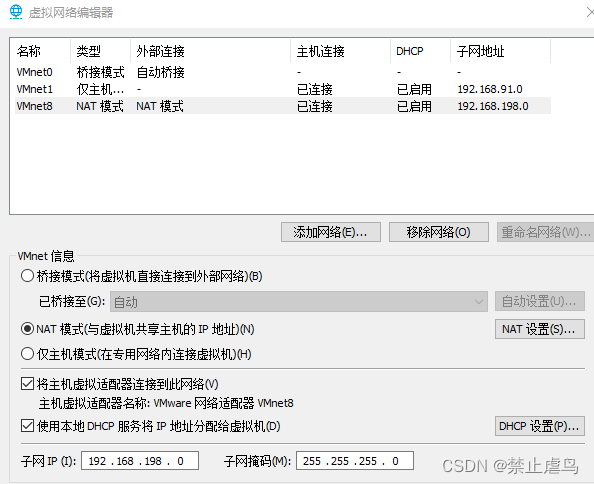
二.dhcp系统启动报错失败
1.在使用systemctl status dhcpd启动命令时报错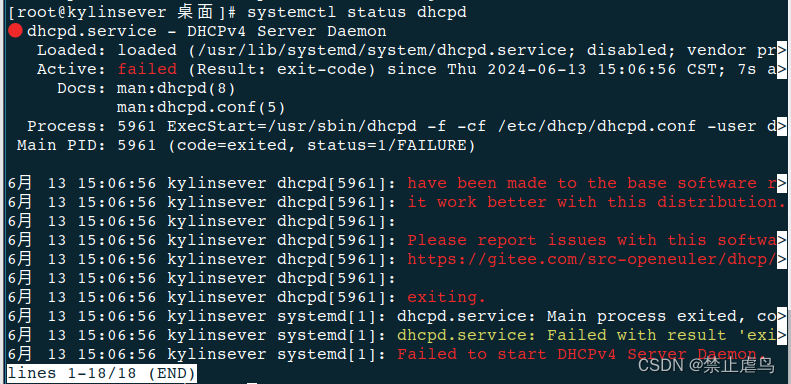
使用ifconfig命令查看一下自己主机的物理地址
如果没有ip则先布置静态ip
静态ip布置方法
nmcli connection modify ens33 ipv4.addresses 192.168.1.1/24 ipv4.method manual
nmcli connection up ens33
ip address show ens33
获取ip后,使用vi打开/etc/dhcp/dhcpd.conf
[root@kylin 桌面]# vim /etc/dhcp/dhcpd.conf
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp-server/dhcpd.conf.example
# see dhcpd.conf(5) man page#
制作配置文件,分配的IP地址段为192.168.1.0,可分配的IP地址为192.168.1.10-192.168.1.200,默认的租约时间(default-lease-time)为24小时,最大的租约时间(max-lease-time)为48小时,时间单位为秒。在/etc/dhcp/dhcpd.conf配置文件尾部添加下列代码,其中地址请按照自己物理机网段配置修改。
subnet 192.168.1.0 netmask 255.255.255.0{
range 192.168.1.10 192.168.1.200;
default-lease-time 86400;
max-lease-time 172800;
}
再次启用dhcp服务
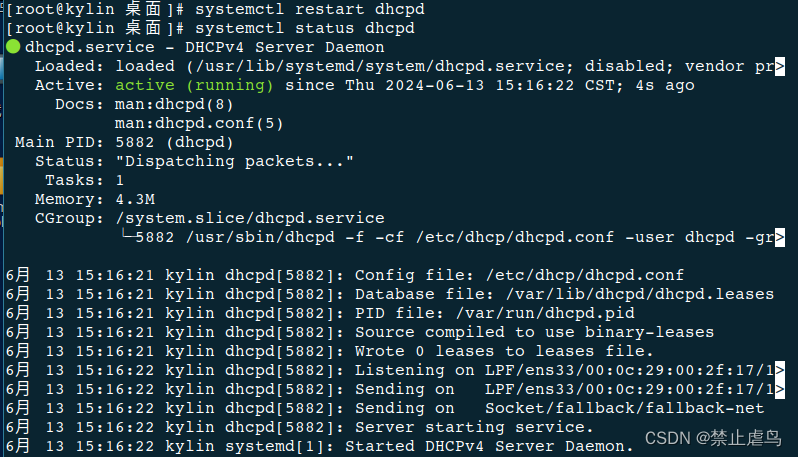
三.客户机无法获取服务器地址
1.放行dhcp服务机中的防火墙
firewall-cmd --permanent --add-service=dhcp
firewall-cmd --reload
firewall-cmd --list-all
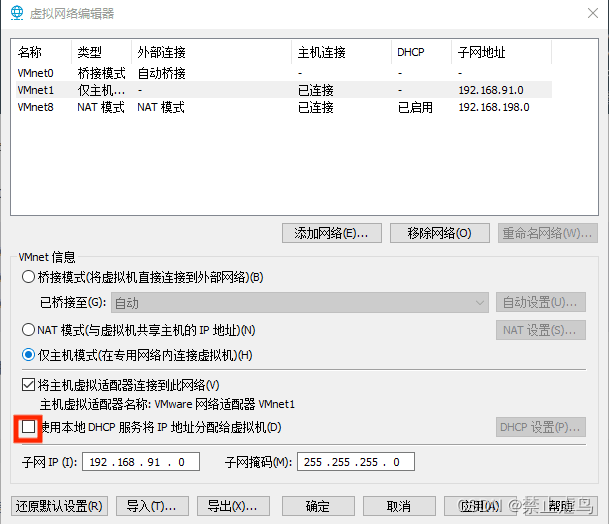
2.在虚拟网络编辑器中的更改设置中,关闭VMnet1网卡中的DHCP服务
总结
在麒麟操作系统部署各种服务时,难免会遇到各种问题。这时候需要我们了解问题信息,并且通过各方面的渠道获取解决问题的方法并且努力尝试,不断学习积累经验和培养解决问题的能力。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









