






 本文记录了作者在2023年使用yolov8进行深度学习模型训练的过程,包括模型下载、环境配置(如Anaconda和PyTorch)、数据集获取、注意力机制的添加以及遇到的问题和解决方案。最终目标是提升模型性能并准备发表论文。
本文记录了作者在2023年使用yolov8进行深度学习模型训练的过程,包括模型下载、环境配置(如Anaconda和PyTorch)、数据集获取、注意力机制的添加以及遇到的问题和解决方案。最终目标是提升模型性能并准备发表论文。
写在前面:
现在是2023年10月24日,研二的第一学期,我正在用yolov8n训练自己方向的公用数据集。今天开始记录我的学习进度,一方面希望记录下来自己在学习过程中遇到的问题和解决方法,见证小白前进之路,另一方面也希望能够催促自己加快学习进度,起到自我监督的作用。如果有做的不对的步骤,还希望各位前辈不吝赐教,斧正我的错误。
2023.10.24
先对前期的准备工作做一个总结。在进行模型训练之前要解决的两个比较关键的问题,一是训练模型怎么找、环境如何配置,二是数据集怎么找。
一、yolov8训练文件
yolov8的文件并不是以yolov8命名的,而是以ultralytics命名。 训练模型在github下载。网址:rzmxGitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite。
训练模型在如下文件中:
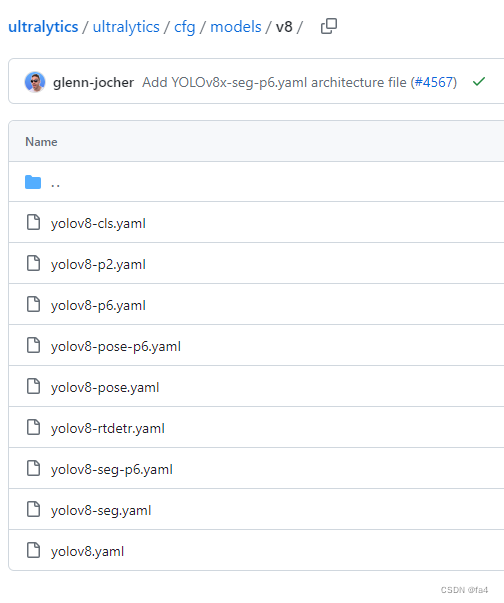
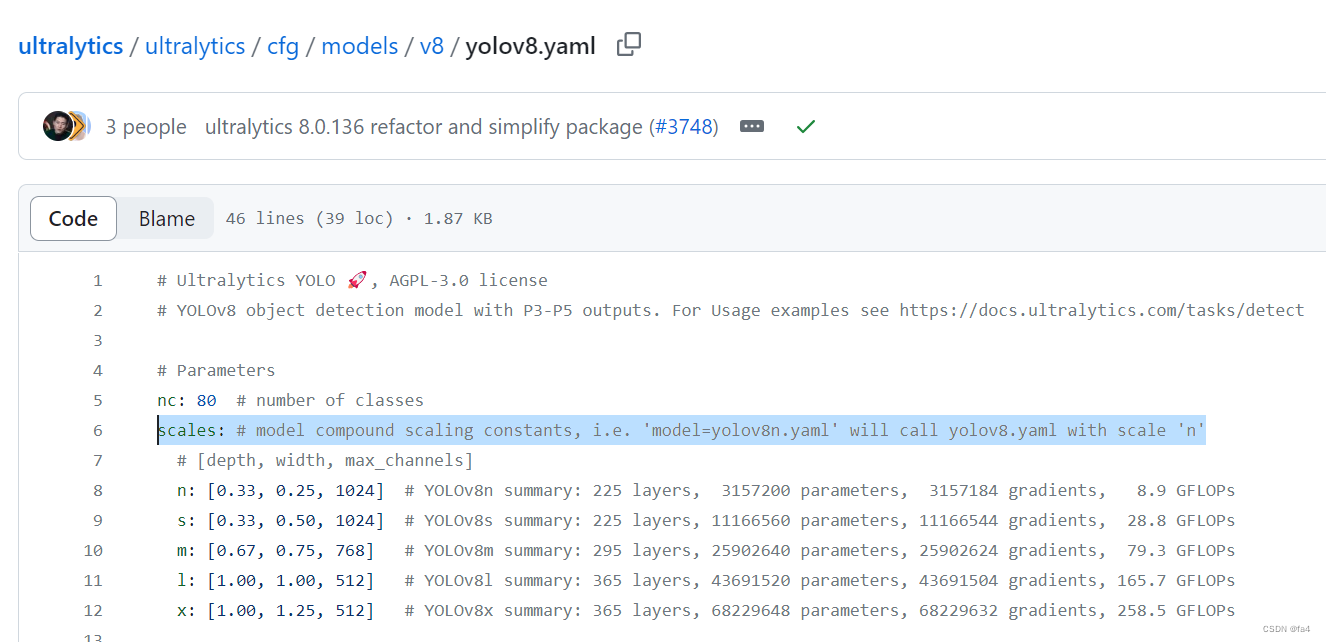
对于上一个版本的修改后,yolov8n/s/m/l/x全部都放在了yolov8.yaml中,如果要使用yolov8n模型可以直接使用语句“model=yolov8n.yaml”。
二、数据集获取
推荐神网:https://datasetsearch.research.google.com/。输入关键字,检索数据集,可以检索到其他网站的数据集。有一部分是注册就能下载,如果需要花钱开会员下载的策略是淘宝找一找有没有代下载。
三、ultralytics环境配置
接下来就是让人头痛一亿年的环境配置。我确实在环境配置上不活过很多次。下面把我做的大致过程列出来,但是可能过程会遇到各种问题,祝你幸运。此部分参考b站视频:YOLOV8环境安装教程._哔哩哔哩_bilibili
1.下载Anaconda作为python基础环境(略)
2.创建环境
关掉代理,以管理员身份运行Anaconda Prompt,输入:
conda create -n yolov8 python=3.8 anaconda其中,“yolov8”为环境名,可以修改;“python=3.8”为python版本;“anaconda”输入进去后会创建一些包,使用更方便。看到如下代码,证明创建成功。如果创建不成功可能是网络问题,可以开热点重新运行以上命令。

激活环境,代码如下:
activate yolov83.安装pytorch
在命令行输入nvidia-sim,查看自己的CUDA版本号,进入pytorch官网Start Locally | PyTorch,查看能否支持最新的CUDA版本(自己的CUDA版本一定大于pytorch的CUDA版本),如果不能就使用pytorch其他版本。
nvidia-smi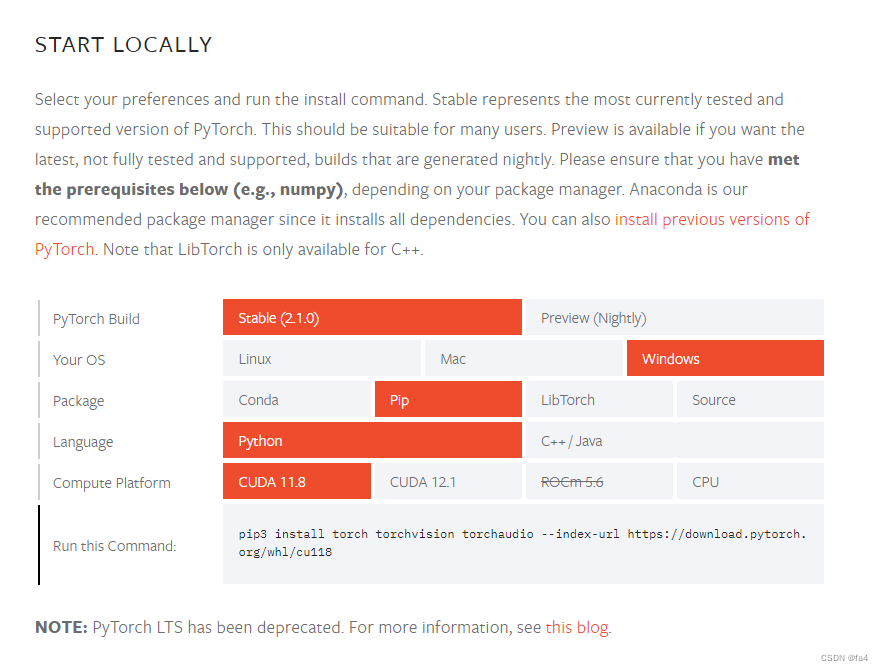
复制“Run this Command”后面的代码,把pip3改成pip,运行安装。
4.安装库
用pytorch打开代码,数据集拉进来。更改环境,在“File-Settings-Python Interpreter”选择“yolov8”。新建Terminal,输入:
python setup.py install如果出现网络问题,重新运行。出现“Finish processing dependencies for ultralytics==8.0.5”证明安装成功。
四、修改配置文件,开始训练
找到“default.yaml”文件,位置如下:
找不到可以双击键盘shift搜索文件。
修改model:ultralytics/models/v8/yolov8.yaml(改为yolov8.yaml的地址);date:date.yaml;workers:4。随即输入代码:
yolo cfg=ultralytics\yolo\cfg\default.yaml #cfg=后面接你的default.yaml路径至此,yolov8模型可以开始训练了【撒花✿✿ヽ(°▽°)ノ✿】。
2023.11.1
添加注意力机制
尝试的第一次“炼丹”是添加注意力机制,即插即用的类型非常方便替换。有一位B站UP主在Github上总结了二十几个常见的注意力机制的代码,非常方便,在这挂出这位UP主在B站教添加注意力机制的视频,视频中讲了添加有通道和无通道的注意力机制的方法,讲解非常清楚,照着一步一步做,基本上不会遇到什么困难。Github网址也附上。
B站视频: YOLOV8改进-添加注意力机制_哔哩哔哩_bilibili
Github网址: yolov8注意力机制
我尝试了如下几种常见的注意力机制,对比的yolov8n原模型的训练效果,终于在添加EMA的时候涨点了。

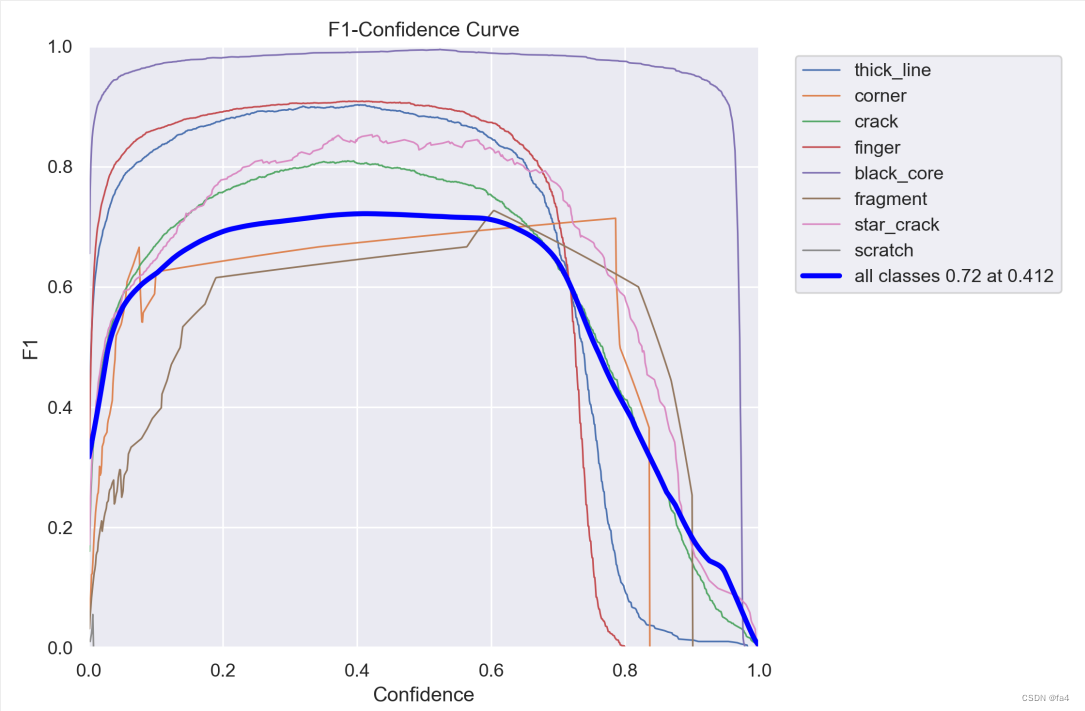 | 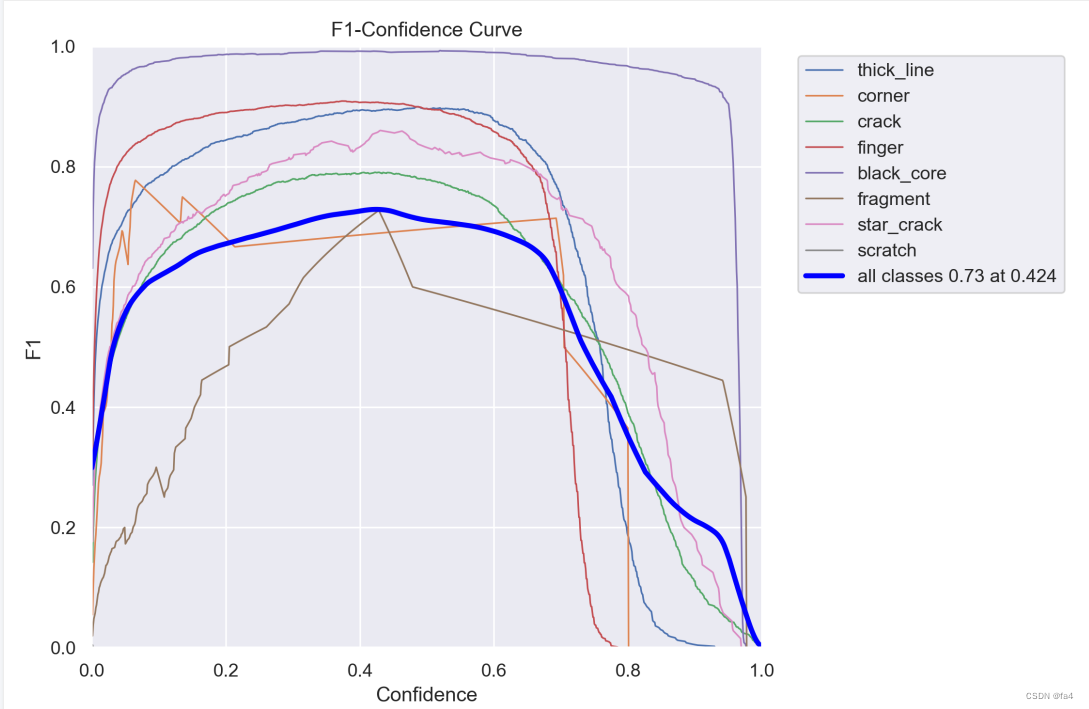 |
| yolov8n F1曲线 | yolov8n+EMA F1曲线 |
在此要特别感谢一位CSDN博主:迪菲赫尔曼。偶然看到迪导的yolov8改进实战专栏,文章质量非常高,就付费订阅了专栏。专栏文章大部分都手把手改进,除去专栏内容不说,迪导的技术非常牛,在训练过程中遇到的问题请教,迪导会及时给出指导,帮助我度过了很多难关。
目前还有一个小问题,就是我设置的epochs设置的是100轮,但是结果并没有完全收敛,现在正在做300轮训练再看效果。我的数据集有3700张图片,显卡是NVIDIA4060,训练一次需要大概30个小时。训练完成后准备更改激活函数,再碰碰运气.
———————————————————————————————————————————
续:由于某个数据的样本量较少,训练图像出现“大跳水”的情况。在进行训练前一定要找好健康监测过的数据集,避免数据集不合适来回替换。推荐查找数据集网站:Roboflow Universe: Open Source Computer Vision Community,可以直观地看到数据集健康情况。
2024.1.11
2023年11月20号左右,我的实验结果终于比较好了。改进点有三处,一个是更换主干网络,一个是添加注意力机制,最后替换非极大值抑制,实验结果已经达到了可以发论文的程度。我给导师看了结果,就开始写论文了。到今天为止,论文已经基本完成了,再做几组对比实验就可以了。
画图网站:hiplot.cn
今天想介绍的是一个画图网站,可以在线生成图片,下面展示几种基本类型的图片(我也不明白都是什么图)。
但是现在我也不是很研究的明白,贴个B站教学在这里。Hiplot 超强在线绘图工具介绍(论文绘图再也不用愁)_哔哩哔哩_bilibili

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









