






记录自己使用YOLOv8进行模型训练
第一步:下载YOLOv8框架
下载链接:项目首页 - ultralytics - GitCode
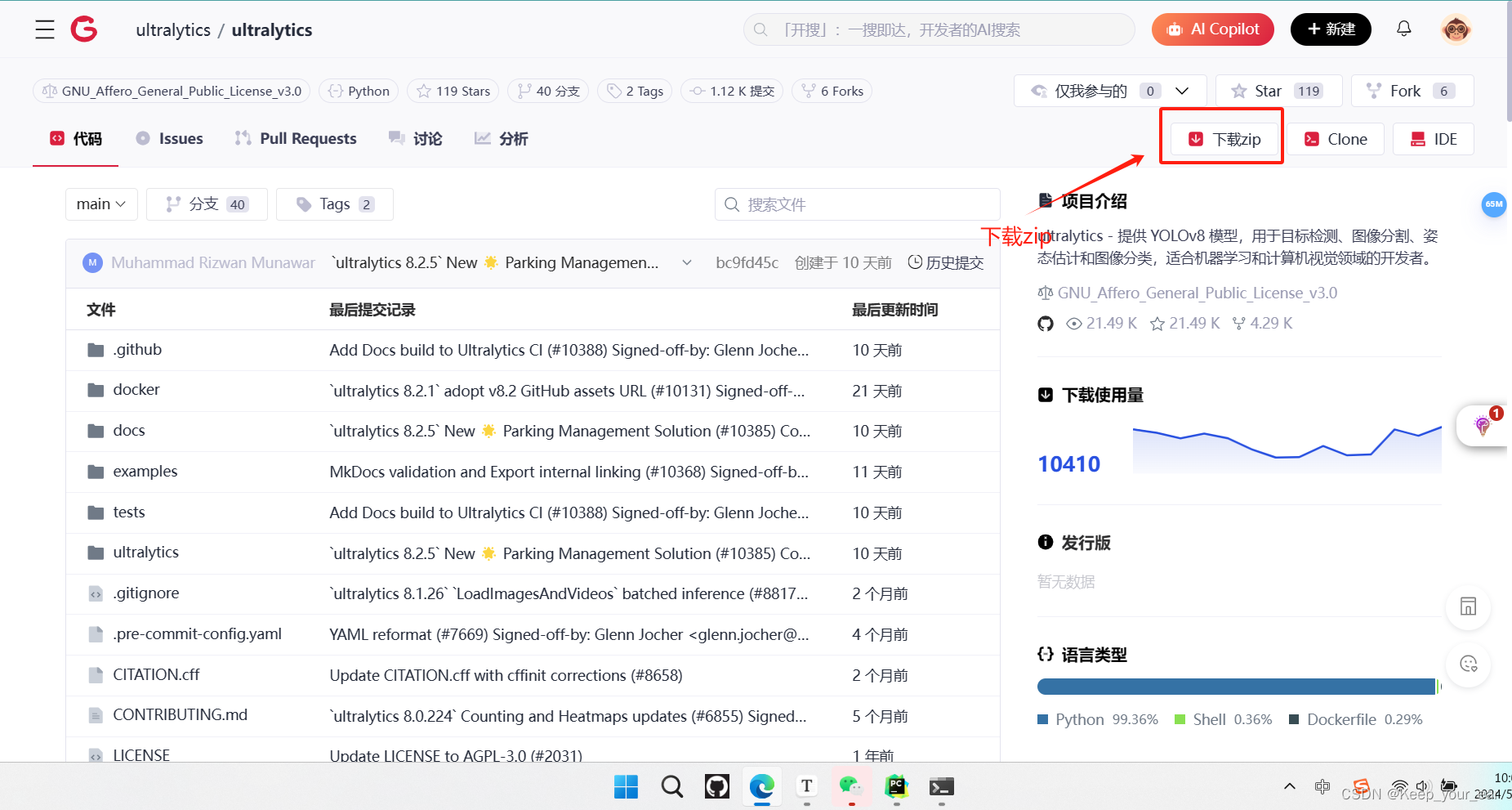
测试YOLOv8框架:
环境要求Python>=3.8,anaconda3或miniconda3
conda环境安装
其实有很多方法可以安装,但是我这边推荐用conda安装,毕竟每个环境可以自行管理,我个人用着还是比较舒服的
创建conda环境
conda create -n yolov8 python==3.8
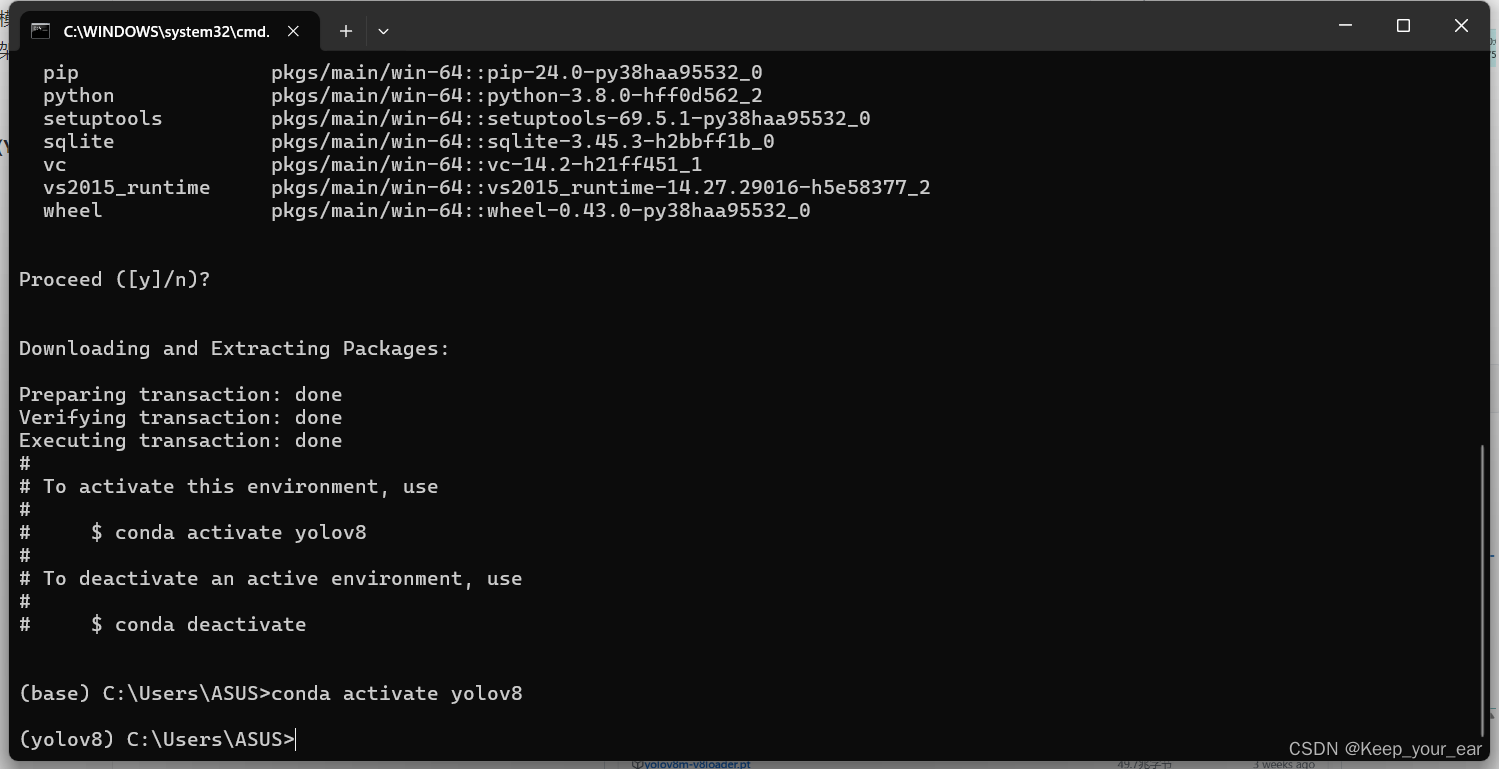
创建后记得激活,然后我们就可以在这个里面下载我们想要下载的东西啦!
安装Ultralytics(YOLOV8)
Ultralytics提供了多种安装方法,包括pip、conda和Docker。通过ultralyticspip包安装最新稳定版的YOLOv8,或者克隆Ultralytics GitHub仓库以获取最新版本。Docker可用于在隔离容器中执行包,避免本地安装。
# 从PyPI安装ultralytics包
pip install ultralytics
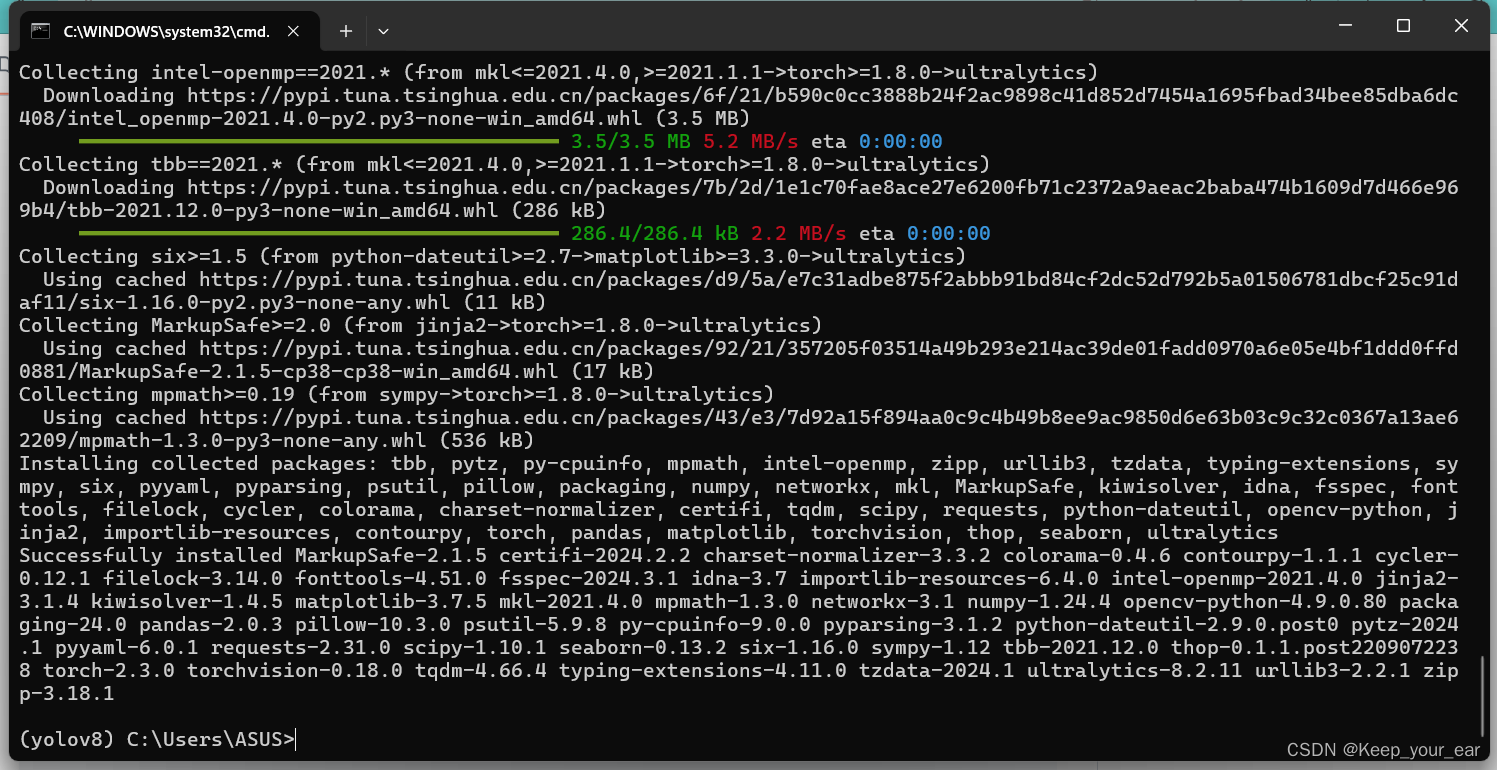
安装好以后就是这样
安装其余环境依赖
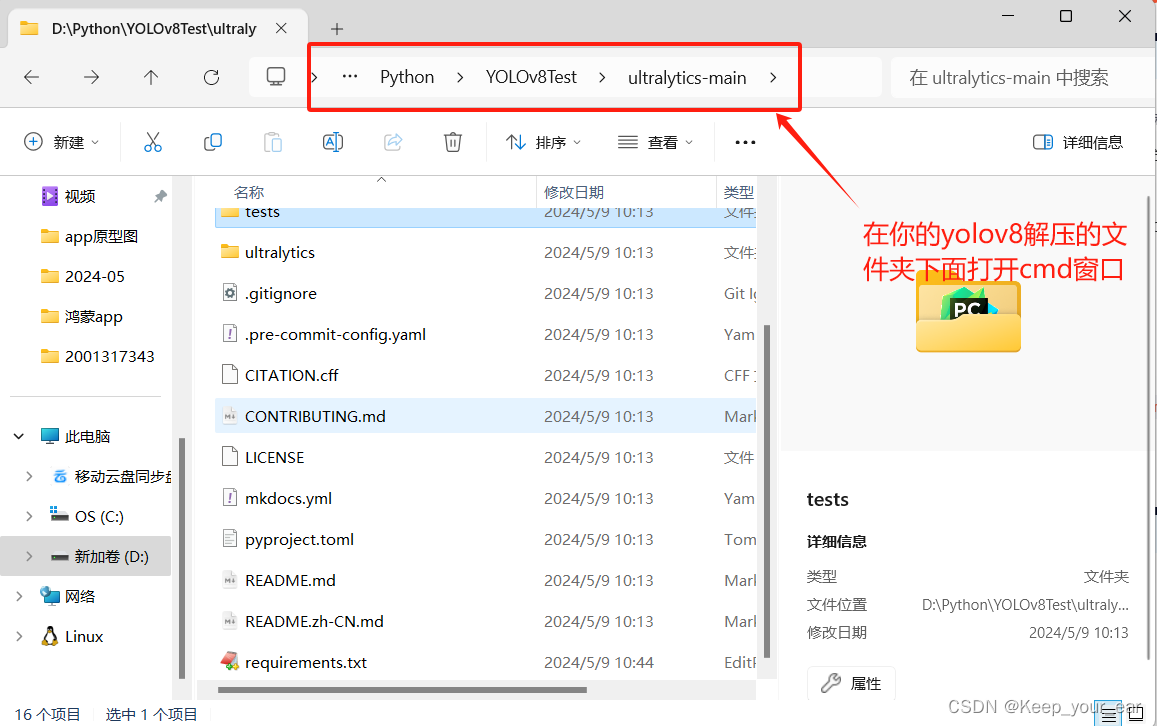
可以看到有一个requirements.txt文件,该文件下面有所有的环境依赖,我们使用pip读取的方式安装
pip install -r requirements.txt
安装之前可以先用dir命名看看,该文件路径下面有没有/requirements.txt/文件

看到是有的,之后就可以进行安装了
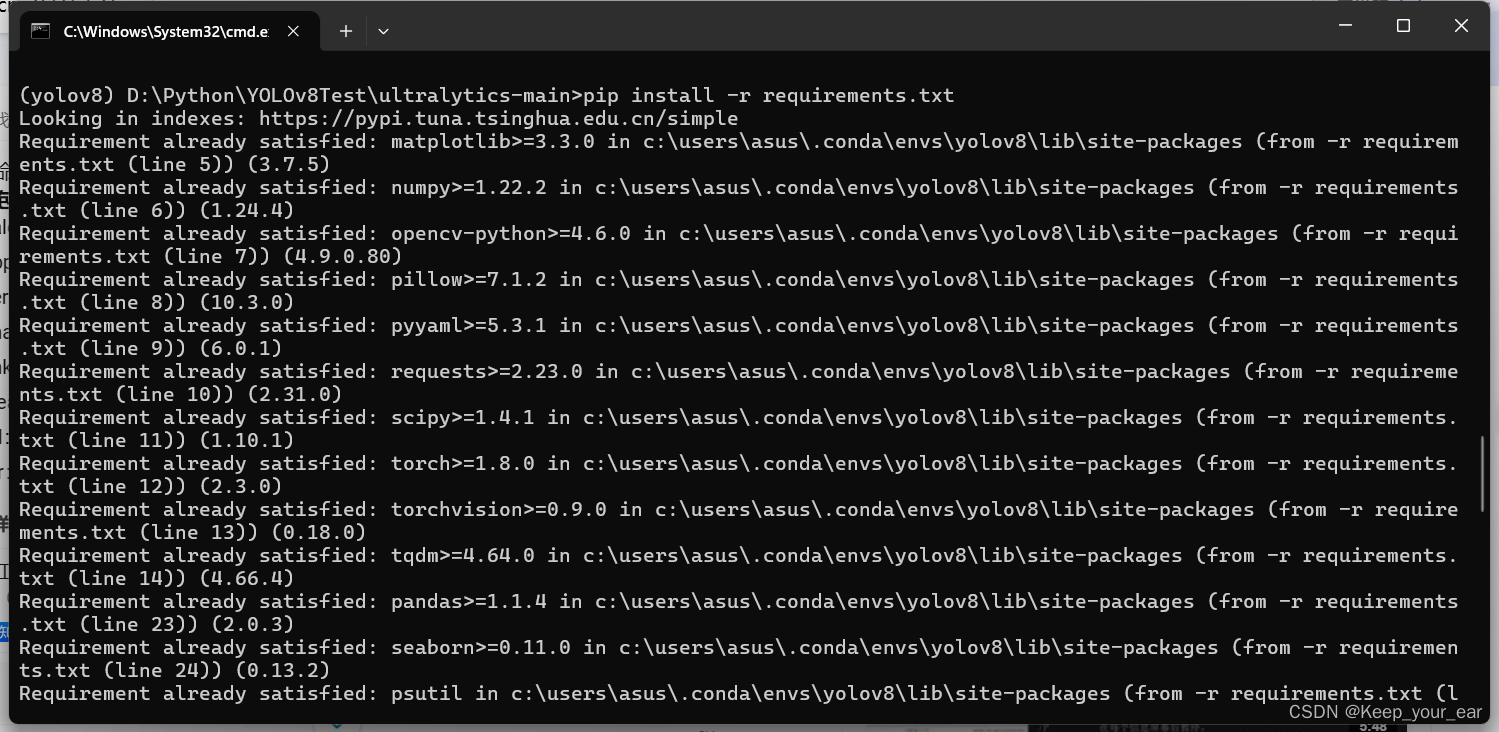
环境安装完成以后就可以进行测试了
YOLOv8测试
# 在命令行中执行以下命令测试项目是否正常安装成功
yolo predict model=yolov8n.pt imgsz=640 conf=0.25
直接输入以上代码在命令框内你就能得到
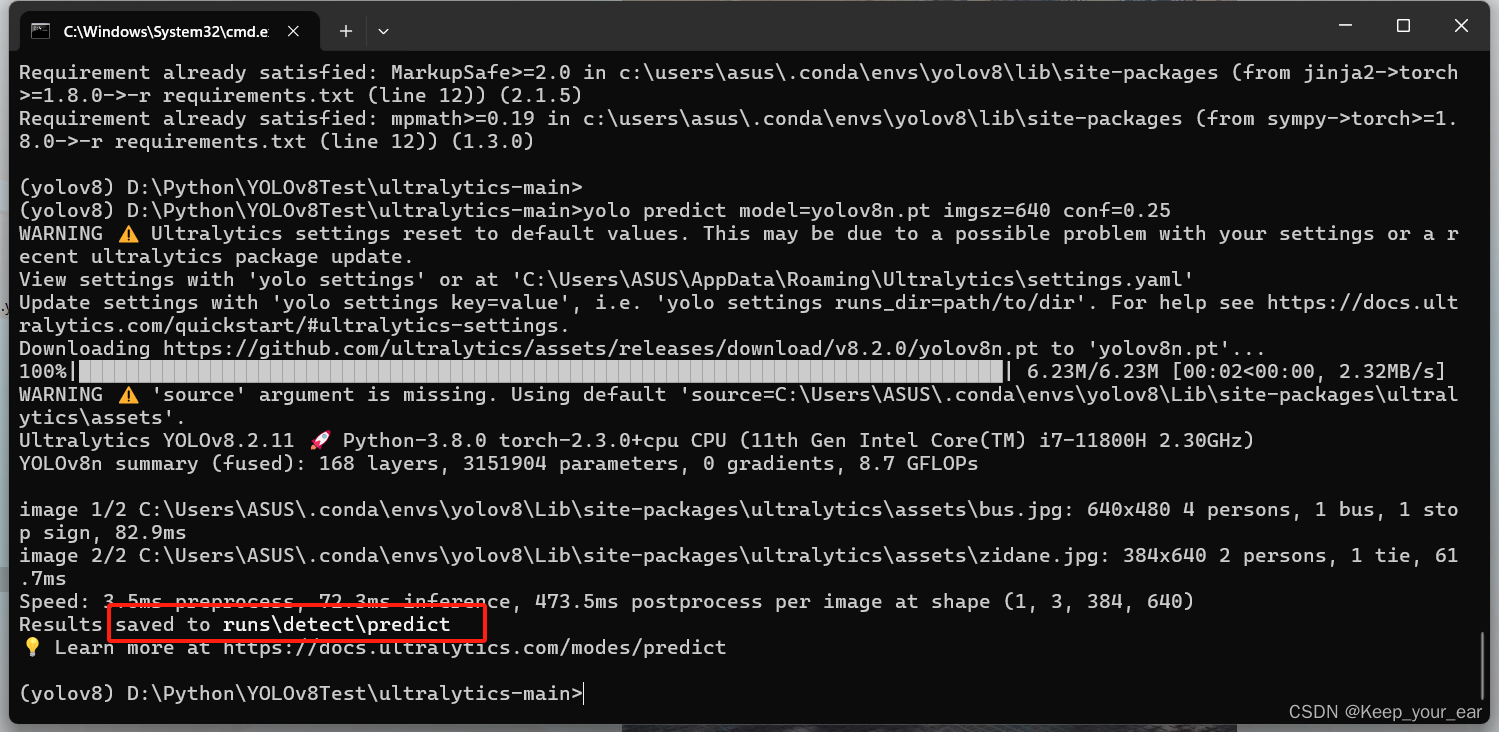
以上路径就是测试过后的图片存放位置,我这个是他自动去寻找没有yolov8n.pt权重文件他自己的去下载了
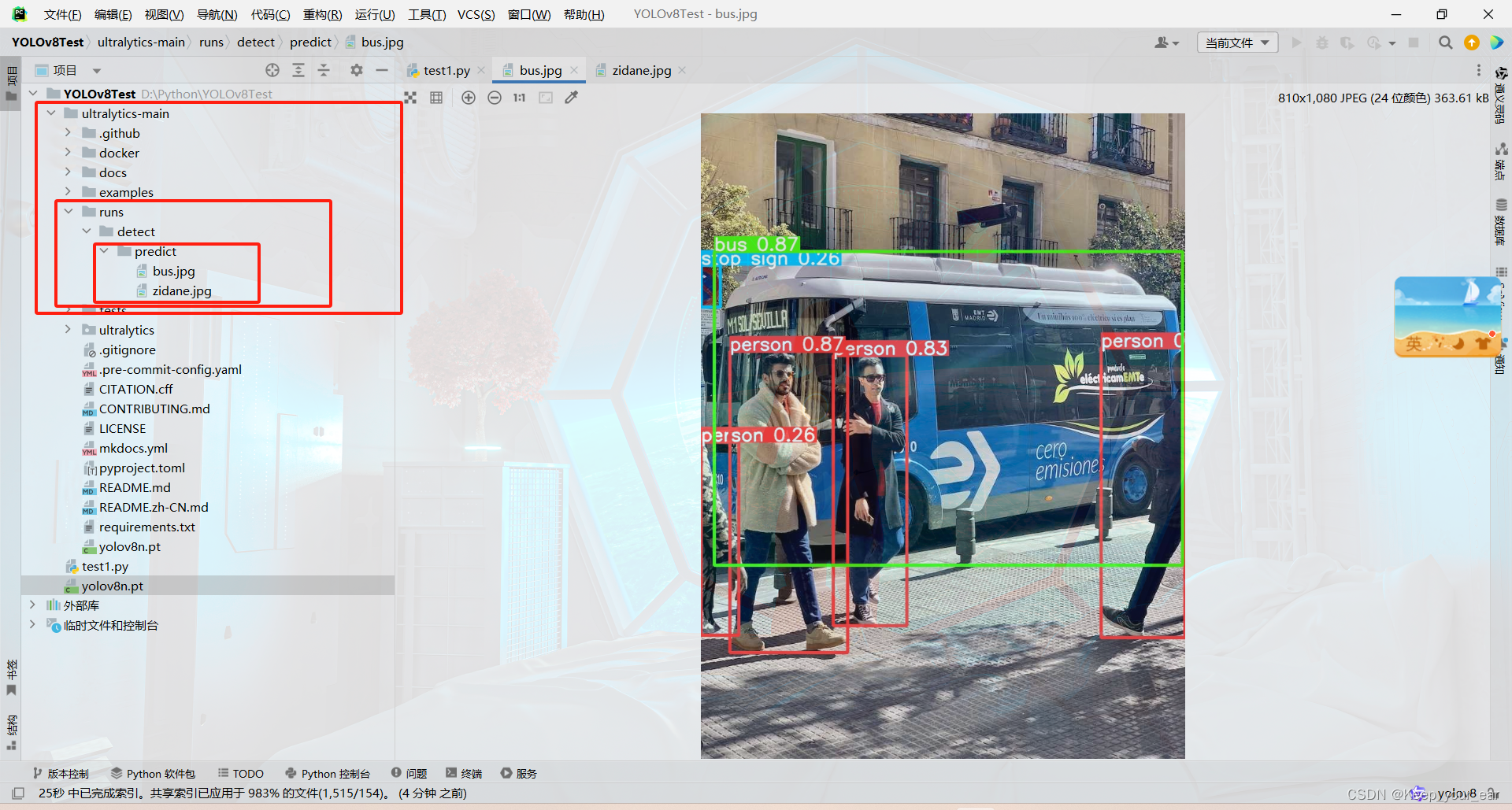
最后你在文件夹下面就可以得到这两张图片就表示你的环境没问题了
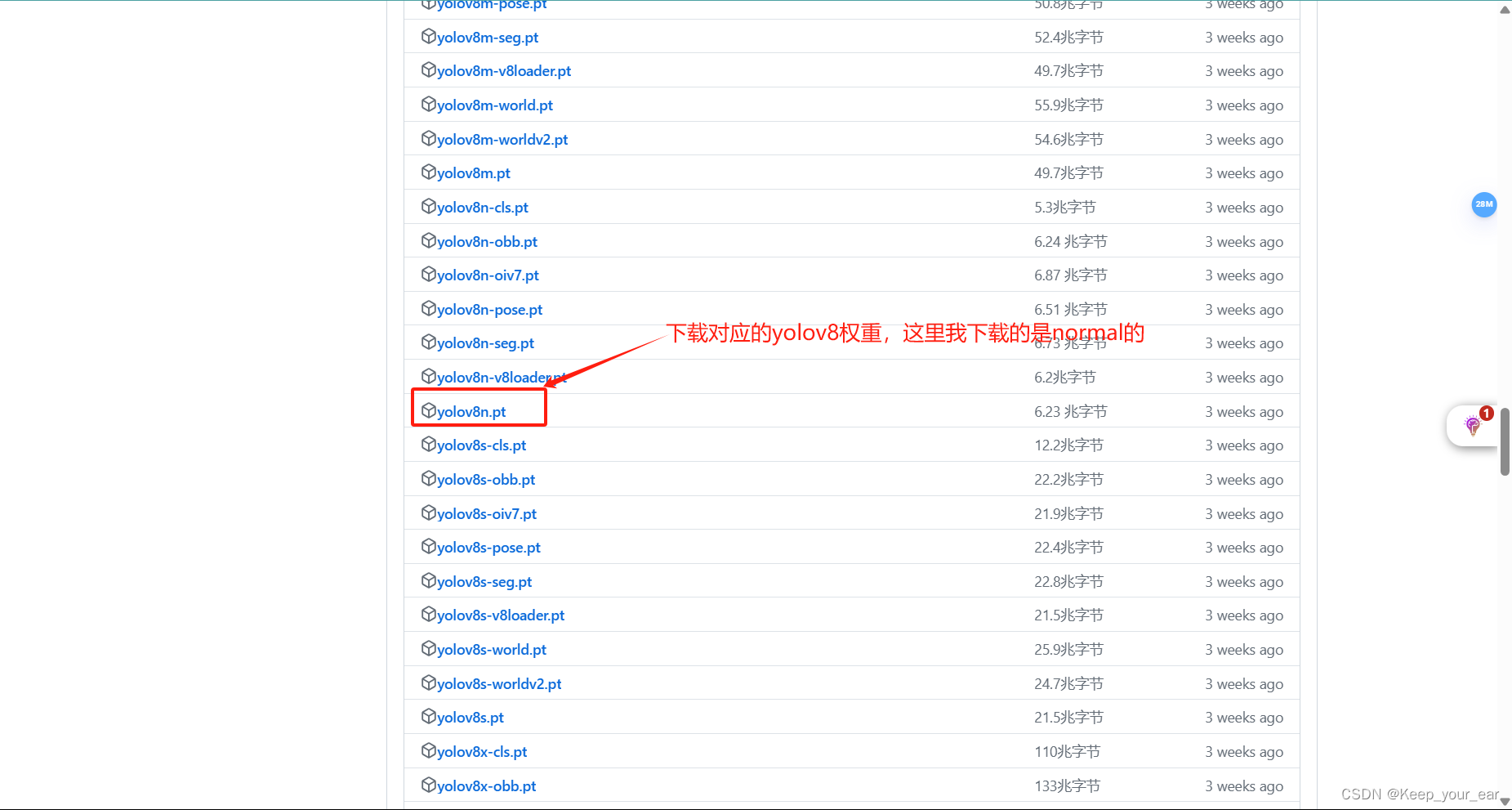
当然你可以选择下载其他的权重文件如下:
下载权重链接:发布 ·Ultralytics/资产 (github.com)
第二步:打开pycharm构建运行脚本
打开pycharm->新建项目
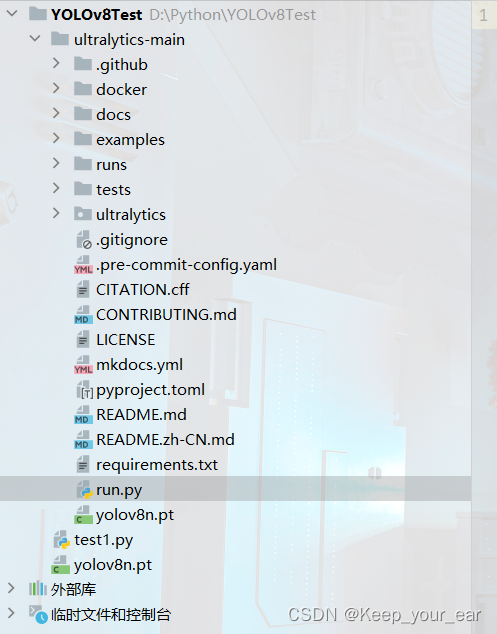
新建一个run.py文件,我们会在这里面进行运行脚本的编写
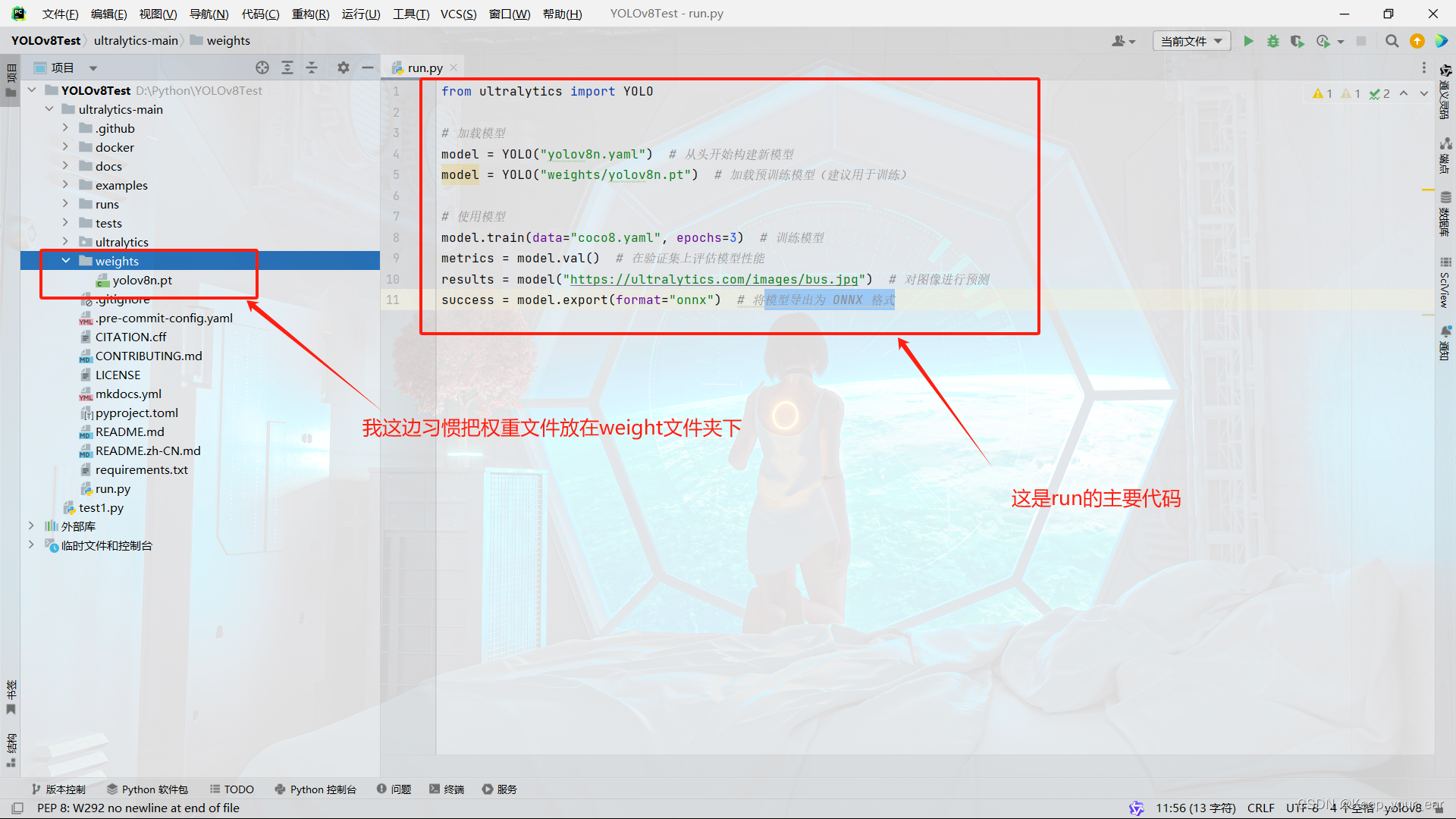
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("weights/yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
model.train(data="coco8.yaml", epochs=3) # 训练模型
metrics = model.val() # 在验证集上评估模型性能
results = model("ultralytics/assets/bus.jpg") # 对图像进行预测
success = model.export(format="onnx") # 将模型导出为 ONNX 格式
进行gpu或者cpu测试,这一步通过每个人自身来定,你的电脑支持cpu还是gpu
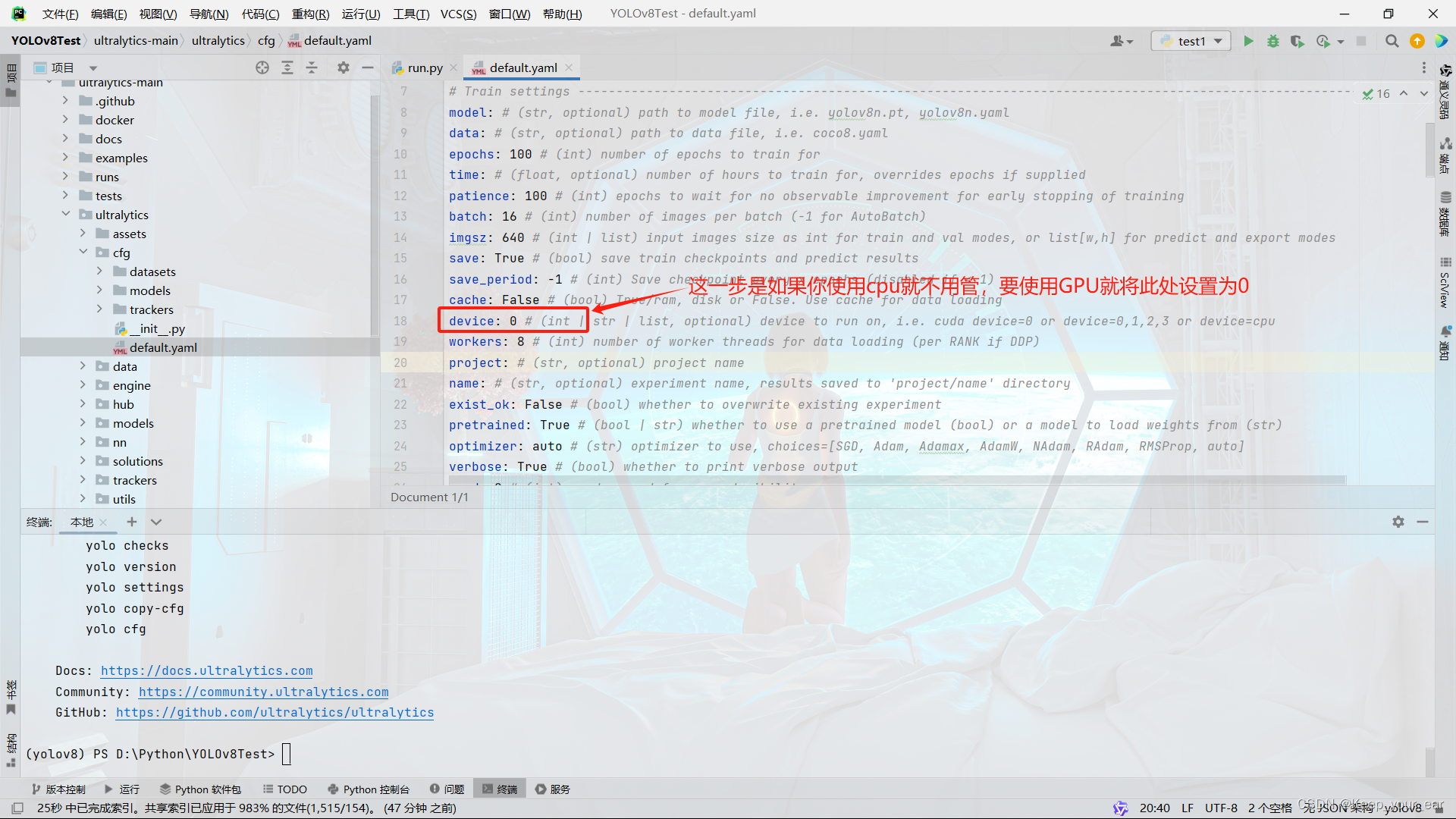
我个人使用的是gpu版本,要使用gpu版本需要你先去下载GPU对应版本的CUDA和CUDNN,注意:如果使用GPU,pyTorch版本也要更改,这个时候就需要去官网下载自己对应的pyTorch版本,传送门如下:
下一步直接到run.py进行运行,注意!!这一步非常吃电脑配置,如果你的电脑c盘内存不足或者性能不好,建议你关闭其他软件进行!
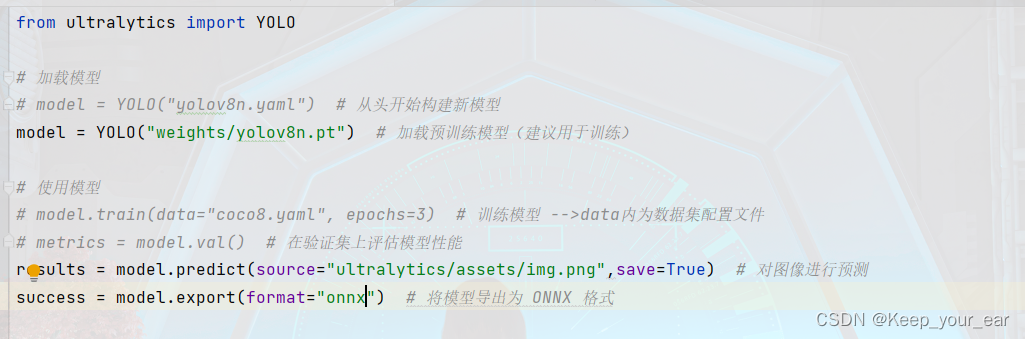
如果没问题运行出来的就是这个。
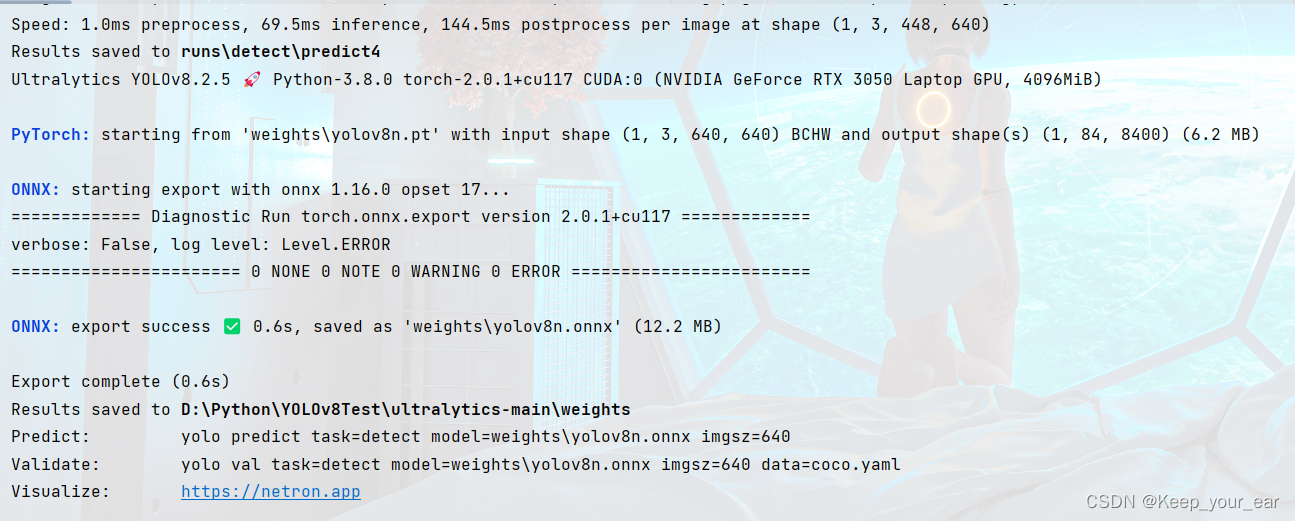
我这里是直接将yolov8n.pt转成onnx了,期间还做了一个图像预测的操作。
预测出来的图片在runs文件夹下,权重文件就在weight文件夹下啦

搞定,yolov8流畅跑起来了
第三步:进行数据预处理
下载包PyQt5:
pip install PyQt5
pip install pyqt5-tools
直接在终端下载,下载到对应环境内
数据标注
下载数据标注工具:labelimg
pip install labelimg
下载之后直接打开
直接在终端输入labelimg,就可以打开啦
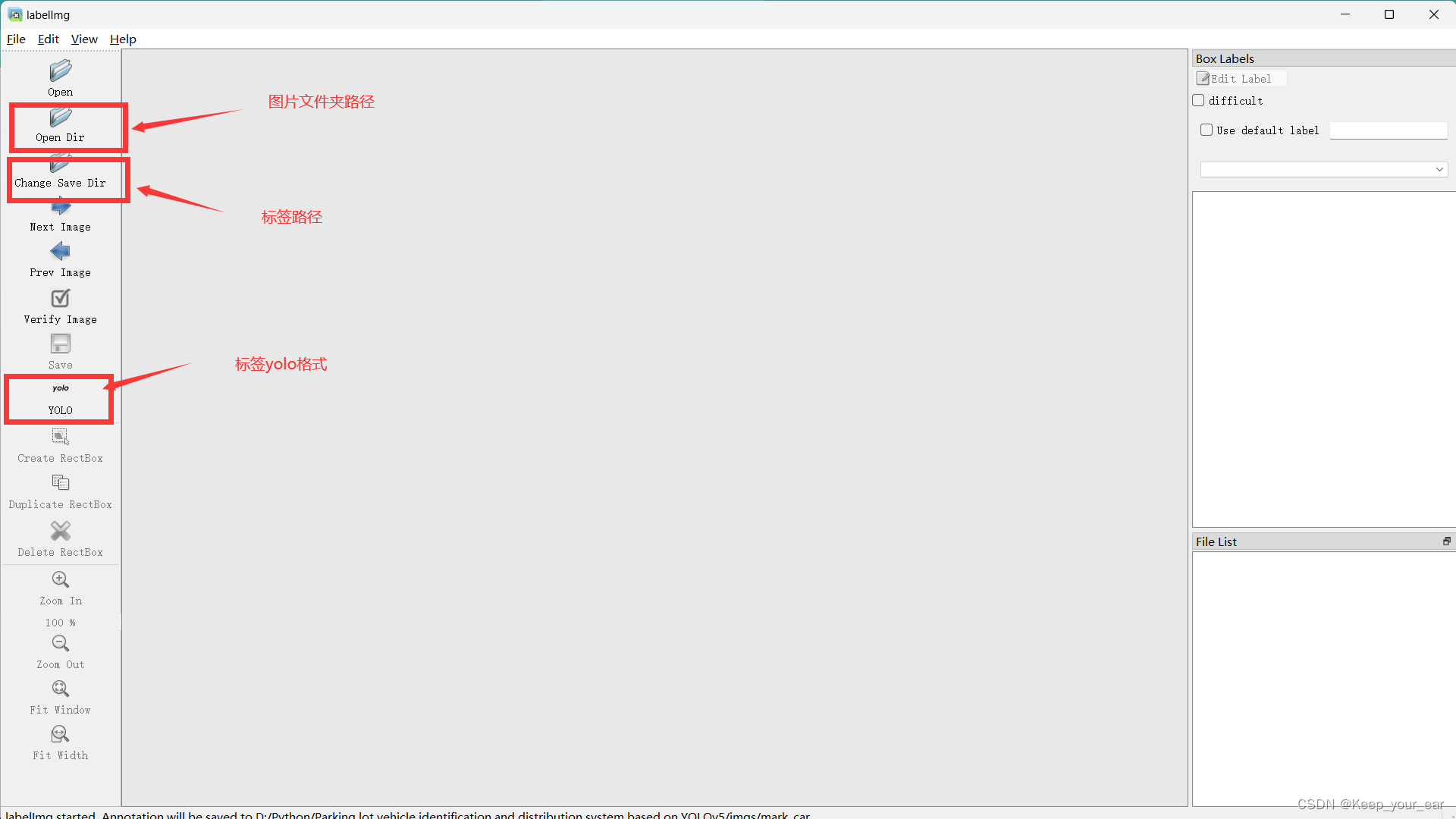
导入之后就可以挨个打标签了

标注完成后就可以关闭了,我这里只使用了10张照片做训练集,4张做测试集,在一个项目中,照片的数量都是几百张起步的,我这里只是为了跑通代码。
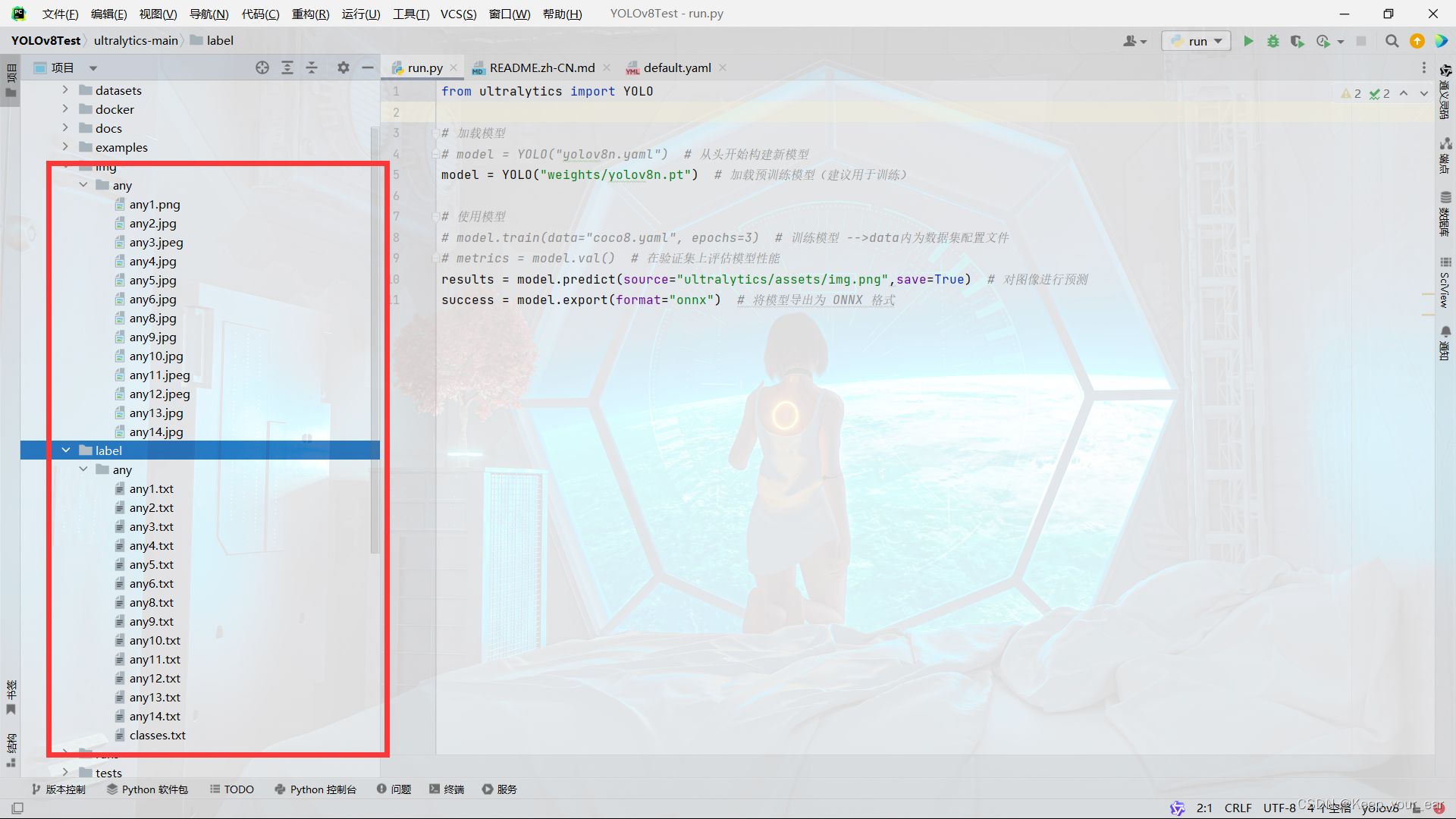
现在就算是标注完成了的
划分数据集
因为数量比较小,我们就进行手动划分,需要在datasets文件夹下新建这样一套文件夹
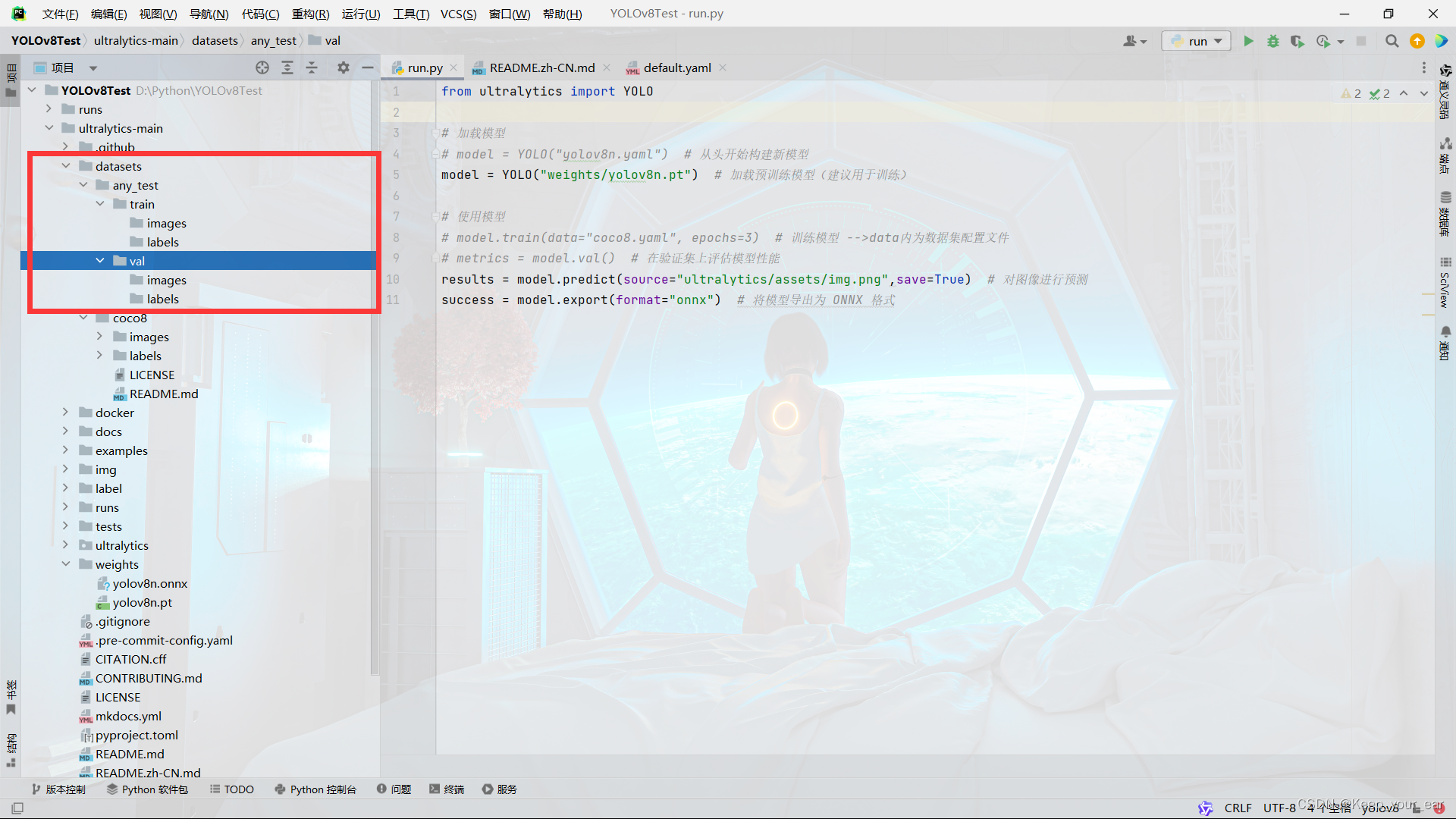
train里面是训练集,val是测试集
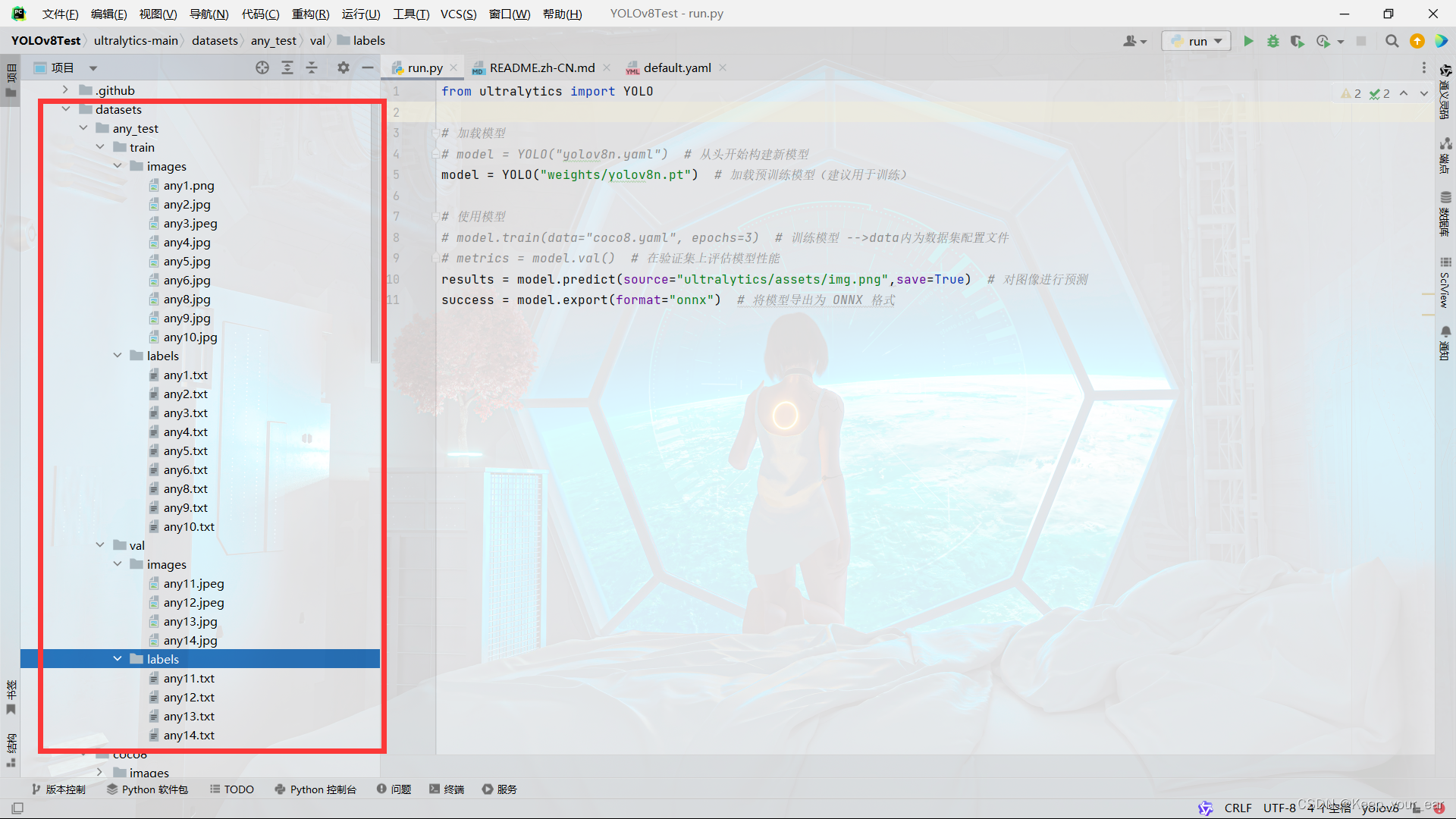
将对应图片复制粘贴过来,不用剪切
创建训练数据
现在需要在文件下面创建yaml数据,找到这个文件夹
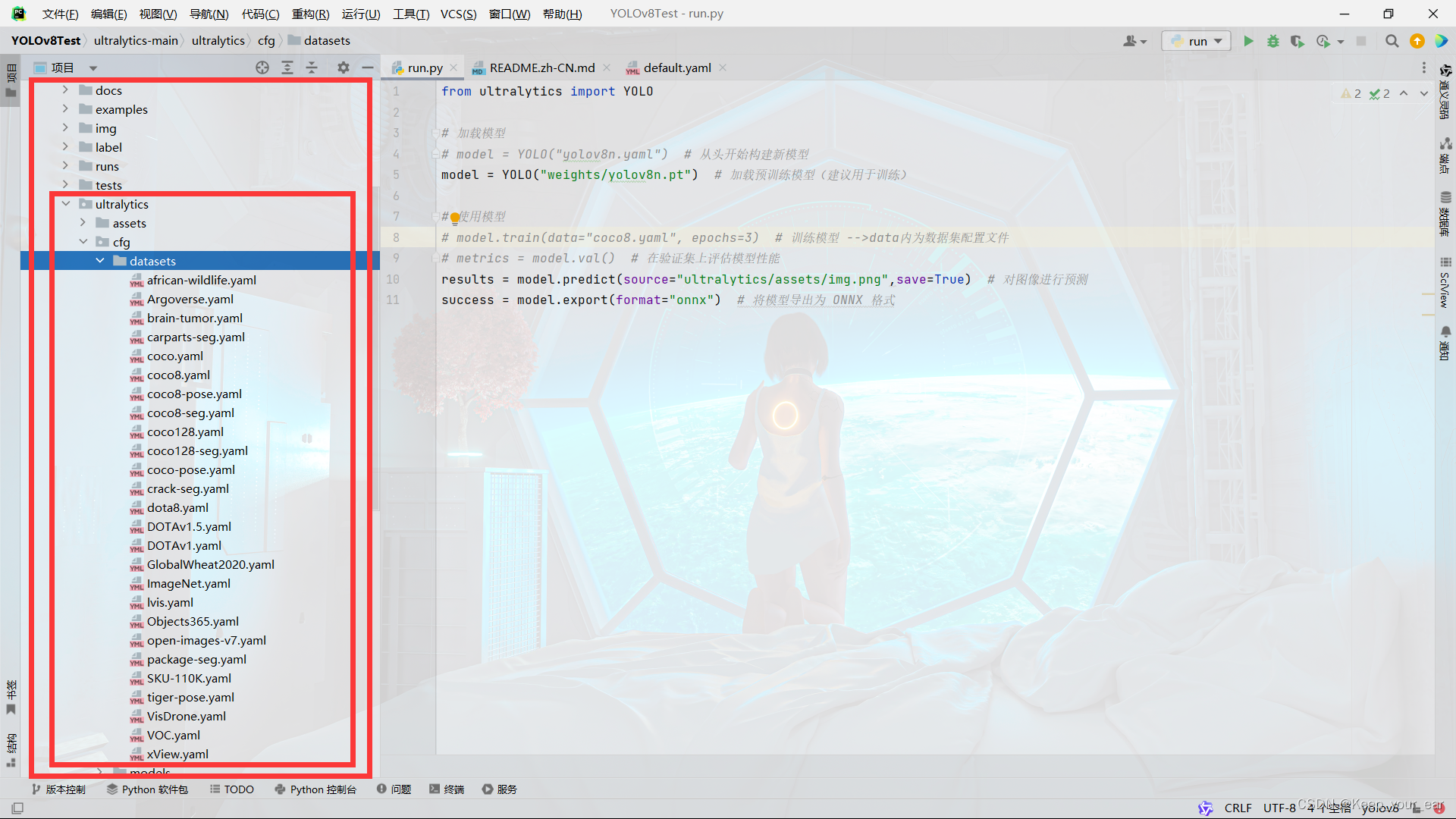
新建any_test.yaml文件
在数据标注的时候,我们用阿尼亚的图片进行标注的,所以这里的类只有any,文件里面内容为:
path: datasets/any_test # 训练数据的路径
train: train/images # 训练集
val: val/images # 验证集
# Classes
names:
0: any
第四步:进行模型训练
现在打开run.py文件,将新建好的yaml文件导入其中
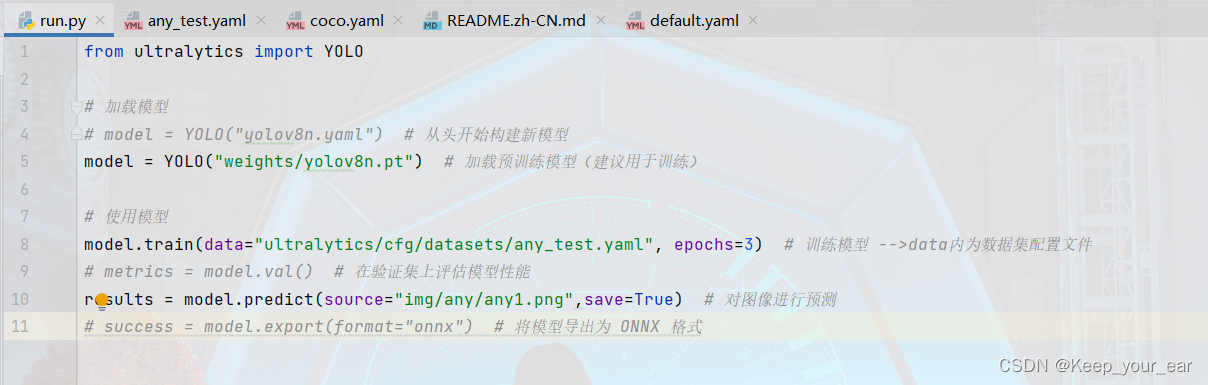
意味着这就是训练三轮,workers默认为8,即同时进行8条线程,最后如果训练报错,可以尝试将yaml文件里面的path路径改成绝对路径,如果还报错并且报错内容为
RuntimeError: DataLoader worker (pid(s) xxxx) exited unexpectedly
这种问题有两种解决方案
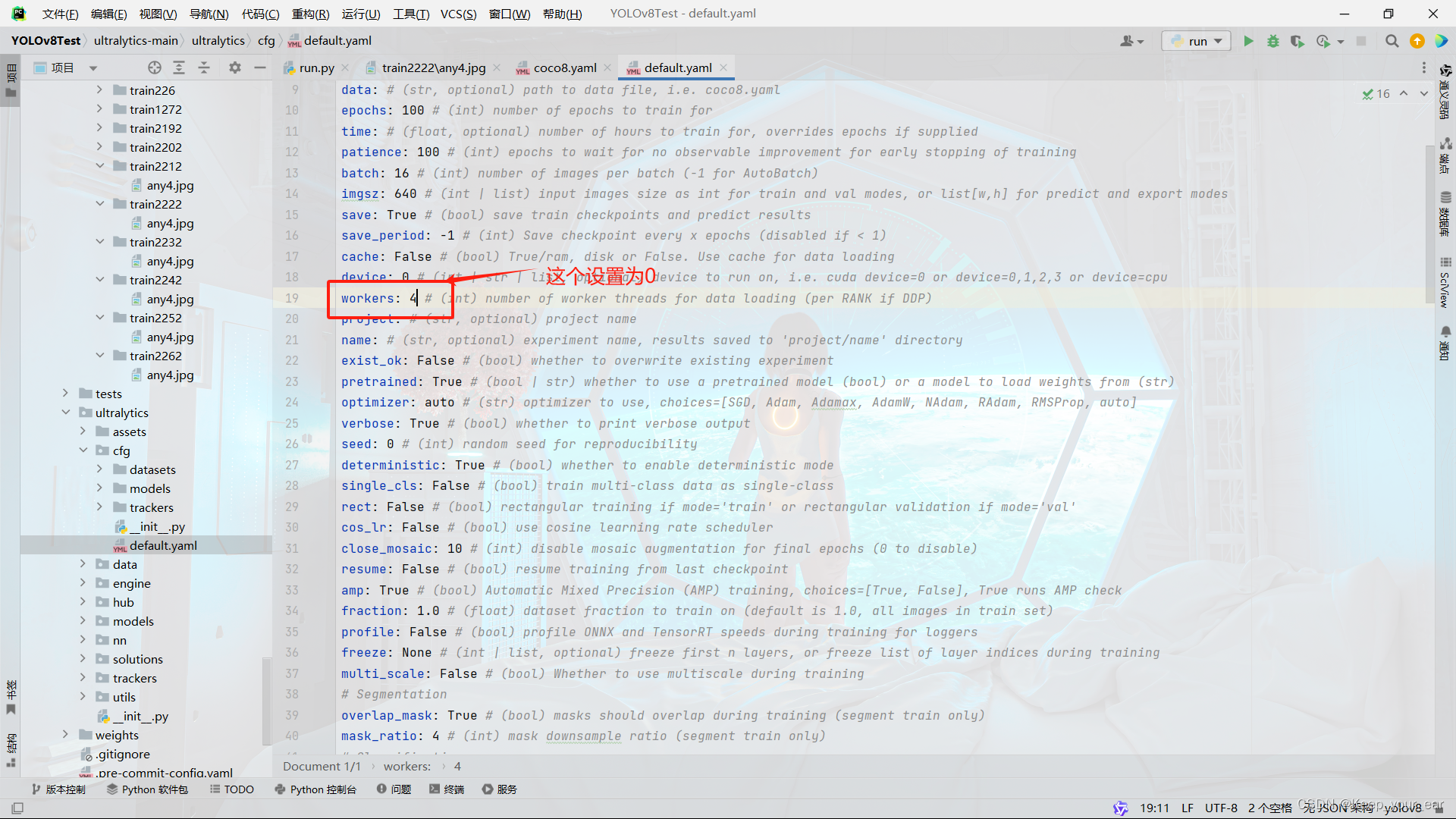
方案一:自废武功,不用多线程,将workers设为0
方案二:在run.py文件内加入main主函数入口,将代码都放入main函数内
就是这样
第五步:进行图像预测
如果你的代码在三轮的轮数能够正常跑起来,那么就可以尝试添加训练集数量以及轮数,我这里演示所用的数据集很小,但是我跑了130轮,最后得出来的图像预测准确度也不高
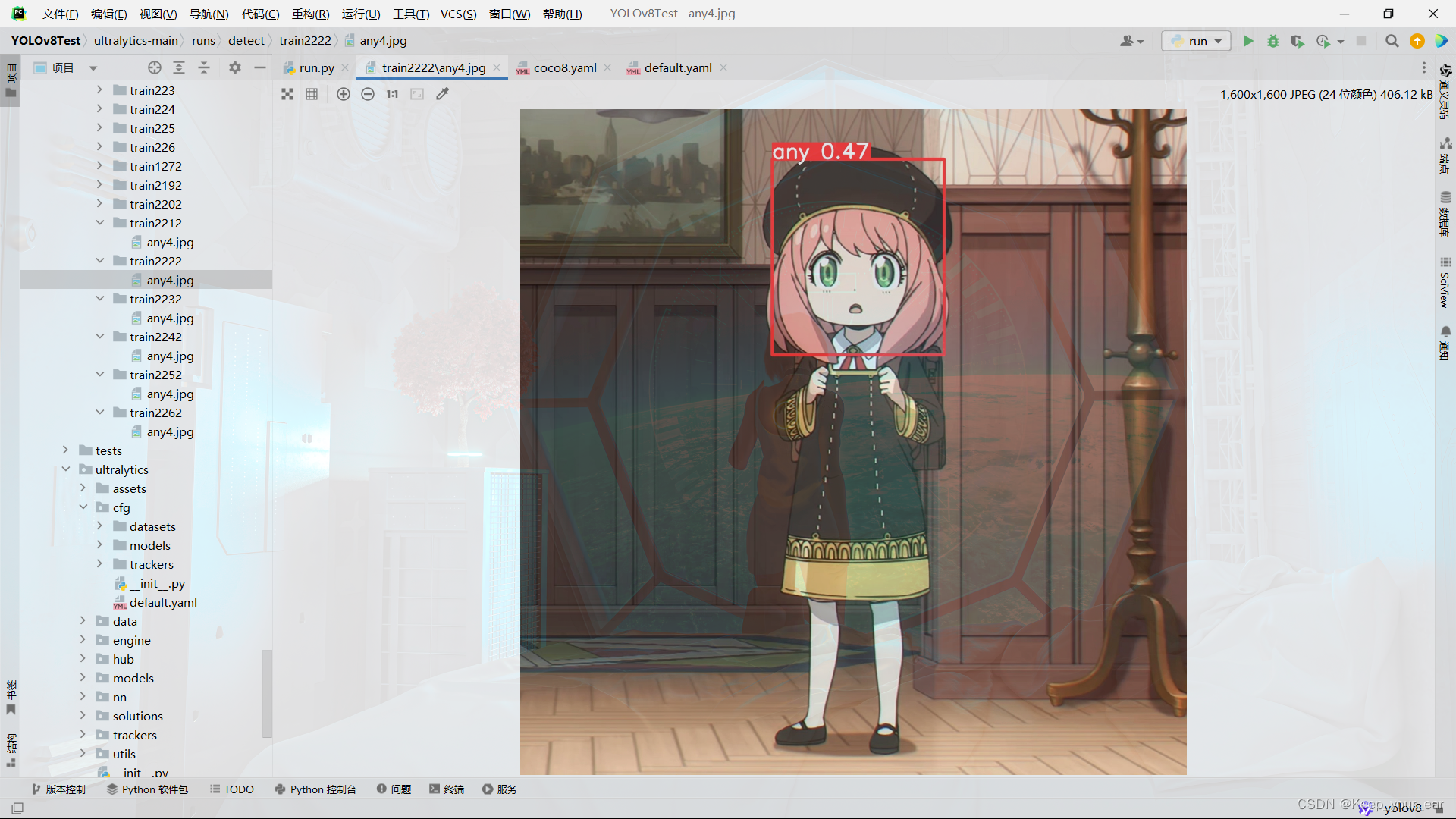
到此,你已经会训练自己的模型了,可喜可贺
这是我人生中第一次写博客,对我自己也是一种学习,如果有哪些地方做的不妥,欢迎指正。
参考来源:【yolov8】新电脑从零开始的yolov8搭建系列_哔哩哔哩_bilibili
SgpQZXn-1715398708577)]















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









