







© 2022 Uriel Singer et al (Meta AI)
© 2023 Conmajia
本文基于论文 Make-A-Video: Text-to-Video Generation without Text-Video Data(2209.14792)。
本文已获论文第一作者 Uriel Singer 授权。

摘要 我们提出了 Make-A-Video(造啊视频),一种直接将最近在文生图(T2I)方面取得的巨大进展转化为文生视频(T2V)的方法。我们的方式很简单:从配对的文字图片数据中了解世界的样子以及它是如何被描述的,从无监督的视频片段中了解世界是如何运动的。Make-A-video 有三个优点:(1) 它加快了 T2V 模型的训练过程(无需从头学习视觉和多模态表示);(2) 它不需要配对的文字视频数据;(3) 生成的视频继承了当今图片生成模型的广博性(美学多样性,幻想描绘等)。我们设计了一种简单而有效的方法,在 T2I 模型上建立了新颖有效的时空模块。首先,我们分解全时间 U-Net 张量和注意力张量,并在空间和时间上逼近它们。其次,我们设计了一个时空管道来生成高分辨率和帧率视频,其中包含一个视频解码器、插值模型和两个超分辨率模型,可以支持包括 T2V 在内的各种应用。在空间和时间分辨率、文字符合度和视频质量等方面进行定性和定量的测量之后,我们相信 Make-A-Video 足以称为目前最先进的文生视频技术。
以下为正文。
1 简介
互联网使人们拥有了从 HTML 页面中收集数以十亿计的如 [替换文字,图片] 这样成对数据的能力,使得最近在文字转图片(T2I,文生图)建模方面取得了长足进步。然而对视频而言,要想(通过成对数据)复制这种成功其收益是有限的,因为迄今还没有办法可以轻松收集相似规模的 [文字,视频] 这种数据集。当市面上已经存在可以生成图片的模型时,从头训练文字转视频(T2V,文生视频)模型不啻为一种浪费。此外,运用无监督学习(即采用无标签的数据)可使网络从更多的数据中学习。大量的数据对于学习微妙的、不常见的概念表达非常重要。长期以来,无监督学习在推动自然语言处理(NLP)领域取得了巨大成功。以这种方式预训练的模型比以有监督方式单独训练的模型产生的性能要高得多。
受此启发,我们提出了 Make-A-Video(造啊视频)。Make-A-Video 利用了 T2I 模型来学习文字和视觉世界之间的对应关系,并对未标记(未配对)的视频数据使用无监督学习方法来学习真实物体的运动。Make-A-Video 可以在不使用 [文字,视频] 这种配对数据的情况下从文字直接生成视频。显然,描述图片的文字不可能(也不需要)捕捉到视频中观察到的全部景象。即是说,人们通常可以从静态图片中——例如喝咖啡的妇女,或踢足球的大象——推断物体的动作和事件,就像在基于图片的动作识别系统中所做的那样。此外,即使没有文字描述,无监督视频也足以学习世界上不同的实体如何移动和交互——例如海滩上的波浪或大象鼻子的运动。我们发现只见过描述图片文字的模型在生成短视频方面效率惊人,如基于时间扩散的方法所示。Make-A-Video 开创了 T2V 时代的新技术。

我们使用函数保持转换在模型初始化阶段扩展了空间层,以包括时间信息。扩展的时空网络包括新的注意力模块,从视频集合中学习时间动态。该程序通过将先前训练过的 T2I 网络中的知识瞬间转移到新的 T2V 网络中,极大地加快了 T2V 训练过程。为了提高视觉质量,我们训练了空间超分辨率模型和帧插值模型。这增加了生成视频的分辨率,并实现了可控的更高帧速率。
我们的主要贡献是:
- 我们提出了 Make-A-Video:一种通过时空因子扩散模型扩展基于扩散的 T2I 模型到 T2V 的有效方法。
- 我们利用联合文字图片先验来绕过对于成对文字-视频数据的需求,从而可以扩展到更大数量的视频数据。
- 我们提出空间和时间上的超分辨率策略,在用户提供的文字输入的情况下,首次生成高清晰度、高帧率的视频。
- 我们将 Make-A-Video 与现有的 T2V 系统进行了评估,并提出:(a) 最先进的定量和定性测量结果,以及 (b) 比 T2V 现有文献更彻底的评估。我们还收集了一个包含 300 个提示的测试集,用于零样本 T2V 人工评估,计划稍后发布。
2 以前的工作
文字转图片生成。里德发表的方法是最早将无条件生成对抗网络(GAN)用于 T2I 生成的研究之一。后续的 GAN 变种则专注于渐进式生成,或者更优图文对齐。有关 DALL-E 的研究开创性地将 T2I 生成看作是序列到序列的翻译问题,并使用了一个离散变分自动编码器(VQVAE)和变换器来实现。在那之后,不断有新的变种推出。例如,造啊场景(Make-A-Scene)利用语义映射研究了可控的 T2I 生成。趴踢(Parti)则瞄准多元内容生成,通过编码器-解码器的架构和改良的图片令牌器完成功能。另一方面,降噪扩散概率模型(DDPM)成功撬动了 T2I 生成的发展。GLIDE 训练了一个 T2I 和用于层叠式生成的上采样扩散模型。 T2I 生成中广泛采用了 GLIDE 提出的无分类器引导,借此提高图片质量和文字符合度。DALLE-2 利用了 CLIP 隐空间和先验模型。VQ-diffusion 和 stable diffusion 在隐空间而非像素空间中进行 T2I 生成,以提高工作效率。
文字转视频生成。尽管 T2I 生成功能进展显著,但 T2V 生成的进展却大幅滞后,主要有两个原因:缺乏具有高质量文字视频配对的大规模数据集,以及高维视频数据建模的复杂性。一些早期工作主要关注简单领域的视频生成,例如移动的数字或者特定的人物动作。据我们所知,Sync-DRAW 是第一个利用重复注意力的变分自编码器 T2V 生成方法。中科大的 Pan Yingwei 和杜克大学的 Li Yitong 等人也在各自研究中将 GAN 网络从图片生成领域扩展到了 T2V 上。
最近,GODIVA 首次使用 2D VQVAE 和稀疏注意力来支持更加真实的 T2V 生成场景。 NÜWA 扩展了 GODIVA,并在多任务的学习方案中为各种生成型任务提供了统一的表示方法。为了进一步提高 T2V 生成的性能,清华大学的 Hong Wenyi 等人基于已经下马的 CogView-2 项目开发出添加了额外时间注意力的 CogVideo T2I 模型。视频扩散模型(VDM)同时使用了图片和视频数据对用于视频表达的时间-空间进行训练。CogVideo 和 VDM 收集了 10M 的私人文字-视频对用于训练,而我们的工作仅使用开源数据集,使其更容易由大众复现。
利用图片先验生成视频。由于视频建模的复杂性和高质量视频数据收集的挑战,人们自然会考虑利用视频的图片先验知识来简化学习过程。毕竟,图片是只有一帧的视频。在无条件视频生成中,MoCoGAN-HD 将视频生成定义为在预先训练的固定图片生成模型的隐空间内寻找轨迹的任务。在 T2V 生成中,NÜWA 在多任务预训练阶段结合了图片和视频数据集,以提高模型泛化以进行微调。CogVideo 利用预先训练和固定的 T2I 模型用于 T2V 生成,这样只需少量可训练参数,以减少训练期间的内存使用。但是固定的自编码器和 T2I 模型对 T2V 的生成有一定的限制。VDM 的架构可以实现结合了图片和视频的生成方式。然而,他们是从随机视频中随机抽取独立图片作为来源,也未利用大量的文本图片数据集。
Make-A-Video 与这些作品有几个不同之处:首先,我们的架构打破了 T2V 生成中对于文本-视频配对训练样本的依赖。与以前的工作相比,这是一个显著的优势,前者必须限制在很窄的范围,或者需要大规模配对的文本视频数据;其次,我们对 T2I 模型进行了视频生成微调,获得了有效调整模型权重的优势,而不是像 CogVideo 那样冻结权重;第三,我们的成果从之前对视频和 3D 视觉任务的高效架构的工作中获取了灵感,使用伪三维卷积和时间注意力层。这不仅更好地利用了 T2I 架构,而且与 VDM 相比,它还允许更好的时间信息融合。
3 方法
Make-A-Video 包含了三个主要的组件:(i) 用文字图片数据对训练的 T2I 基本模型(见 3.1 节);(ii) 时空卷积和注意力层,用于将网络的砌块(building block)扩展到时间维度上(见 3.2 节);(iii) 时空网络,包括时空层和 T2V 生成所需的另一个关键元素——用于高帧率生成的帧插值网络(见 3.3 节)。
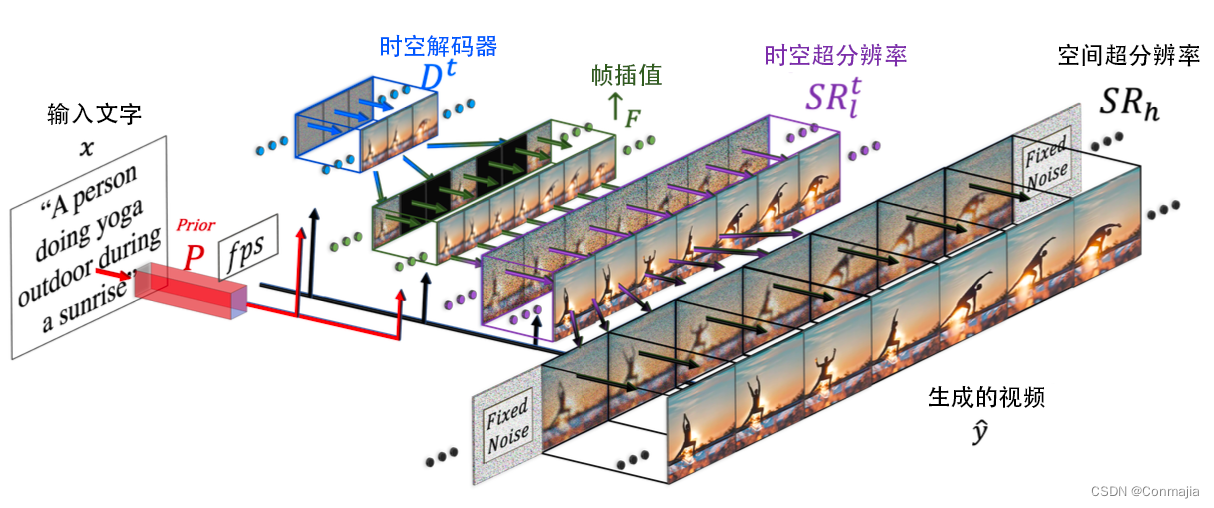
Make-A-Video 的最终 T2V 推断方案(如图 2 所示)可以表述为:
y t ^ = S R h ∘ S R l t ↑ F ∘ D t ∘ P ∘ ( x ^ , C x ( x ) ) , (1) \hat{y_t}=\mathrm{SR}_h\circ\mathrm{SR}_l^t\uparrow_F\circ\mathrm{D}^t\circ\mathrm{P}\circ\left(\hat{x},\mathrm{C}_x\left(x\right)\right),\tag{1} yt^=SRh∘SRlt↑F∘Dt∘P∘(x^,Cx(x)),(1)
其中 y t ^ \hat{y_t} yt^ 是生成的视频, S R h \mathrm{SR}_h SRh、 S R l \mathrm{SR}_l SRl 分别是空间、时空超分辨率网络(见 3.2 节), ↑ F \uparrow_F ↑F 是帧插值网络(见 3.3 节), D t \mathrm{D}^t Dt 是时空解码器(见 3.2 节), P \mathrm{P} P 是先验值(见 3.1 节), x ^ \hat{x} x^ 是经 BPE 编码的文字, C x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











