






学习内容:
这周学习了论文:Diverse Video Captioning by Adaptive Spatio-temporal Attention(CVPR2022),一种基于BERT的采用自适应时空注意
生成多样性字幕的方法,其中涉及到了tokenizer,embedding,cross-attention等概念,经过查阅资料理清了文章的脉络。
- 深度学习中的embedding
- 深度学习中的tokenizer
- 深度学习中的语义
学习时间:
10.10 ~ 10.15
学习笔记:
深度学习中的embedding
深度学习模型不会接受原始文本数据作为输入,它只能处理数值张量。因此需要文本向量化。
文本向量化是指将原始文本转化为数值张量的过程,有多种实现方式:
1. 将文本分割为单词,并将每个单词转化为一个向量
2. 将文本分割为字符,并将每个字符转化为一个向量
3. 提取单词或字符的n-gram(多个连续的单词或字符),将每个n-gram转化为一个向量。
将文本分割后的单词/字符/n-gram称为token,将tokens转化为向量有两种方法:
1.one-hot 编码
2.Embedding(通常只用于单词,叫作词嵌入(word embedding))
one-hot 编码
什么是one-hot编码
假设,一共只有10个汉字,那么我们用0-9就可以表示完。
比如,这十个字就是“小普喜欢星海湾的朋友”
其分别对应“0-9”,如下:

那么,其实我们只用一个列表就能表示所有的对话。
例如:


经过one-hot编码把上面变成:

即:把每一个字都对应成一个十个(样本总数/字总数)元素的数组/列表,其中每一个字都用唯一对应的数组/列表对应,数组/列表的唯一性用1表示。
优点
这样做的好处就是计算简单,稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和。
缺点
使用One-hot 方法编码的向量特点是维度高并且稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当使用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,要是我的字典再大一点,比如中文大大小小简体繁体常用不常用有十几万,假设有一篇100W字的文章,则要表示成100W X 10W的矩阵,这种方法的计算效率会大打折扣。
这时我们需要使用Embedding层解决这个问题。
Embedding(嵌入层)
在整个深度学习框架中都是十分重要的“基本操作”,不论是NLP(Natural Language Processing,自然语言处理)、搜索排序,还是推荐系统,或是CTR(Click-Through-Rate)模型,Embedding都扮演着重要的角色。
为什么引入Embedding
-
神经网络过大
巨大的输入向量意味着神经网络的超大数量的权重。 如果你的词汇表中有M个单词,并且输入上的网络的第一层中有N个节点,则您需要使用MxN个权重来训练该层。 大量的权重会导致进一步的问题:
数据量:模型中的权重越多,有效训练需要的数据就越多。
计算量:权重越多,训练和使用模型所需的计算量就越多,很容易超出硬件的能力。 -
向量间缺少有意义的关系
如果将RGB通道的像素值提供给图像分类器,那么谈论“相近”值是有意义的。 略带红色的蓝色接近纯蓝色,无论是在语义上还是在向量之间的几何距离方面。 但是对于索引1247的1的向量表示的“马”,与索引50,430为1的向量表示的“羚羊”的关系不比索引238为1表示的向量“电视”的更接近。
这些问题的解决方案是使用embedding,embedding将大型稀疏向量转换为保留语义关系的低维空间。
简单来说,我们提取了数据集进行训练,根据训练,找寻我们所给的词汇之间的的关系,根据图,可以看出来积极的词汇聚拢,消极的词汇聚拢。
Embedding的作用
-
降维
接one-hot编码的案例,假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它的维度降到100W X 20,瞬间量级降了10W/20=5000倍,这便是嵌入层的一个作用——降维。
-
升维
低维的数据可能包含的特征是非常笼统的,我们需要不停地拉近拉远来改变我们的感受,让我们对图像有不同的观察点,对低维的数据进行升维时,可能把一些其他特征放大,或者把笼统的特征分开。
综上所述,Embedding作为一种桥梁,让我们想要操作的对象可伸可缩,变成我们希望的样子。
语义理解中Embedding的意义
如下图所示,我们可以通过将两个无法比较的文字映射成向量,接下来就能实现对他们的计算。
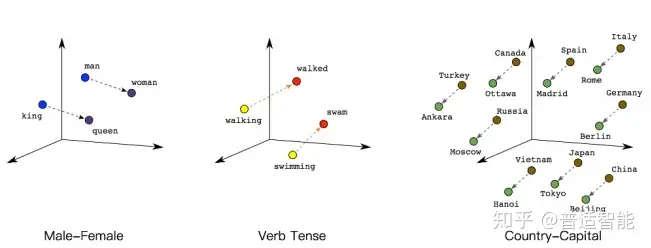
例如:
queen(皇后)= king(国王)- man(男人)+ woman(女人)
那么计算机对皇后的理解为:King - man = power(国王的权利),power+woman=拥有王权的女性=queen(皇后)。
另一个例子:
walked(过去式)= walking(进行时)- swimming(进行时)+ swam(过去式)
同理计算机也能明白,“walked,就是walking的过去式”另外,向量间的距离也可能会建立联系,比方说“北京”是“中国”的首都,“巴黎”是“法国”的首都,那么向量:|中国|-|北京|=|法国|-|巴黎|。
参考文章:
https://zhuanlan.zhihu.com/p/164502624
https://www.jianshu.com/p/fdf52856bd1c
https://www.codenong.com/cs105898040/
深度学习中的tokenizer
在NLP任务中,原始文本需要处理成数值型字符才能够被计算机处理,我们熟悉的one-hot编码就是一种转换方式。但这种方式有两个弊端:
- 向量维度太高
- 丢失了语义信息
后来人们发明了词向量(或称之为词嵌入),它在一定程度了解决了one-hot的上述两个问题。
从「词向量」这个名字上就可以看出,其基本单元是词。因此,要想得到词向量,首先要对句子进行分词,所以,我们需要一个分词工具,简称之为“分词器”。在现代自然语言中,分词器的作用不再是仅仅将句子分成单词,更进一步的,它还需要将单词转化成一个唯一的编码,以便下一步在词向量矩阵中查找其对应的词向量。
将文本拆分为标记的过程称为标记化(tokenization),而标记化用到的模型或工具称为tokenizer。Keras提供了Tokenizer类,用于为深度学习文本文档的预处理。
完成分词和编码后通过padding把所有词向量补成同样长度,再用keras中自带的embedding层进行一个向量化,就可以输入到各种模型中。
参考链接:
https://blog.csdn.net/a321123b/article/details/121436837
https://blog.csdn.net/sunjw_2017/article/details/121783956
深度学习中的语义理解
语义信息
图像的语义分为视觉层、对象层和概念层。
视觉层即通常所理解的底层,即颜色、纹理和形状等等,这些特征都被称为底层语义特征;
对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;
概念层是高层,是图像表达出的最接近人类理解的东西。
通俗点说,比如一张图上有沙子,蓝天,海水等,视觉层是一块块的区分,对象层是沙子、蓝天和海水这些,概念层就是海滩,这是这张图表现出的语义。
空间关系特征
所谓空间关系,是指图像中分割出来的多个目标之间的相互的空间位置或相对方向关系,这些关系也可分为连接/邻接关系、交叠/重叠关系和包含/包容关系等。
通常空间位置信息可以分为两类:相对空间位置信息和绝对空间位置信息。前一种关系强调的是目标之间的相对情况,如上下左右关系等,后一种关系强调的是目标之间的距离大小以及方位。
显而易见,由绝对空间位置可推出相对空间位置,但表达相对空间位置信息常比较简单。
空间关系特征的使用可加强对图像内容的描述区分能力,但空间关系特征常对图像或目标的旋转、反转、尺度变化等比较敏感。
另外,实际应用中,仅仅利用空间信息往往是不够的,不能有效准确地表达场景信息。为了检索,除使用空间关系特征外,还需要其它特征来配合。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









