










 本文详细介绍使用Scrapy框架进行高效数据抓取的过程,包括安装配置、正则和XPath数据提取、翻页处理及代理IP设置,适用于贴吧等网站的大规模数据采集。
本文详细介绍使用Scrapy框架进行高效数据抓取的过程,包括安装配置、正则和XPath数据提取、翻页处理及代理IP设置,适用于贴吧等网站的大规模数据采集。
scrapy为爬虫框架 通过框架更加效率的提取数据 使用scrapy框架时 只需要 通过正则 或者xpath 提取想要爬取的数据
首先安装 scrapy 模块 使用命令行
pip install scrapy
如果安装失败 则使用其他方法安装 在其他文章里面有详细介绍
再创建一个 项目 先cd到所需文件夹
scrapy startproject teiba
再创建一个爬虫 先cd到所建项目
cd teiba
scrapy genspider tb tieba.baidiu.com #tb为创建的爬虫名字 tieba.baidu.com为爬取的范围
在所创项目里 有几个文件 不再一一介绍 在setting里面可以设置一些参数
在抓取数据时 一般先通过正则或者xpath抓取第一页的内容,抓取到标题 图片等数据之后 再提取到下一页的url地址,再通过 yield scrapy.Request方法请求下一页
代码如下
import scrapy
import urllib
import requests
class TbSpider(scrapy.Spider):
name = 'tb'
allowed_domains = ['tieba.baidu.com']
start_urls = ['https://tieba.baidu.com/f?ie=utf-8&kw=%E5%89%91%E7%81%B5%E6%B4%AA%E7%A6%8F%E5%8C%BA&pn=0&'] # 在响应中找到起始页的url
def parse(self, response):
li_list = response.xpath("//ul[@id='thread_list']/li") #通过观察源码 每一个帖子在一个li标签里然后分组
for li in li_list:
item = {}
item["title"] = li.xpath(".//a[@class='j_th_tit ']/text()").extract_first()
item["author"] = li.xpath(".//span[@class='tb_icon_author ']/@title").extract_first()
item["last_reply"] = li.xpath(".//span[@class='tb_icon_author_rely j_replyer']/@title").extract_first()
item["href"] = li.xpath(".//a[@class='j_th_tit ']/@href").extract_first() # extract_first()方法为取数据的第一个
if item["href"] is not None:
item["href"] = urllib.parse.urljoin(response.url, item["href"]) #抓取到的url地址一般都不完整 这里采用urllib.jion方法根据response中的url地址 将url地址补充完整 也可以直接使用 字符串相加
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta={"item": item} # 请求详情页 callback为调用详情页的方法
)
# 实现翻页
next_url = response.xpath("//a[text()='下一页>']/@href").extract_first() # 提取下一页的url地址
if next_url is not None:
next_url = urllib.parse.urljoin(response.url, next_url) # 补充完整url地址 再次请求
yield scrapy.Request(
next_url,
callback=self.parse
)
def parse_detail(self, response): #
item = response.meta["item"]
item["img_src"] = li.xpath(".//img[@class='threadlist_pic j_m_pic ']/@data-original").extract()
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url, next_url)
yield scrapy.Request(
next_url,
callback=self.parse,
meta={"item": item}
)
else:
print(item)
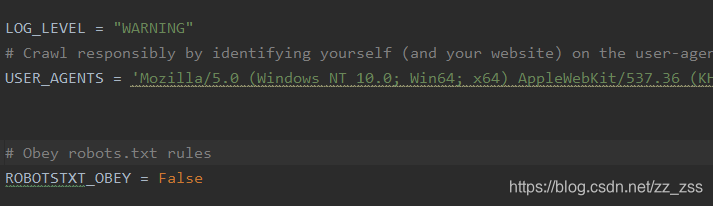
在setting文件中可以设置这几个参数
LOG_LEVEL 为取消日志
USER_AGENTS 手动设置ua
ROBOTSTXT_OBEY = False 设置robot协议 默认为Ture 遵守协议
当爬取多次可能爬取不出来数据 可能因为ip地址被拉黑 应设置一个代理ip
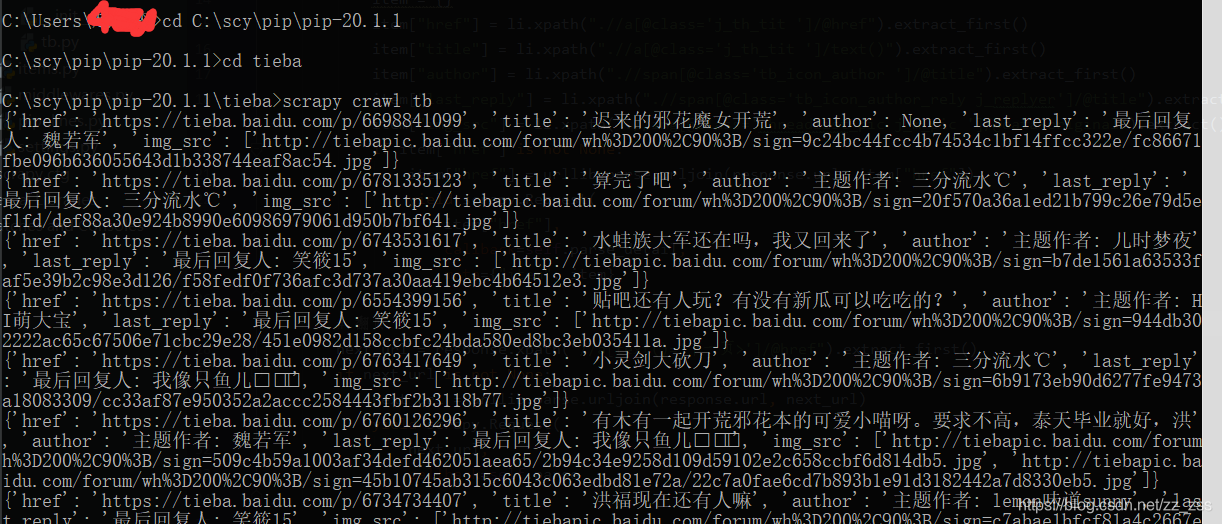
运行程序
scrapy crawl tb

















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









