






实现背景:
从音频和静态图像中创建逼真而富有表现力的肖像动画具有广泛的应用,从虚拟现实和游戏到数字媒体。然而,制作具有视觉吸引力和保持时间一致性的高质量动画是一项重大挑战。这种复杂性来自于唇部动作、面部表情和头部位置的复杂协调,以创造出视觉上引人注目的效果。
在样本有限的条件下,面部配音(facial dubbing)的工作中,实现高分辨率的面部配音仍旧是一项挑战。为了解决这个问题,网易伏羲实验室提出了一种用来实现高分辨率面部配音的形变-修补网络(deformation inpainting network),通过对参考图像的特征图进行形变来保留更多的高频纹理细节,相关论文《DINet:实现高分辨率下的人脸视觉配音》已被第37届国际顶级人工智能会议AAAI录用。
获取Dinet论文网站:
| https://doi.org/10.48550/arXiv.2303.03988 |


论文概述:
Dinet模型:通过对参考人脸图像进行空间形变来保留更多的嘴部纹理细节,来实现高分辨率下的人脸视觉配音。主体:
形变修复网络:
①形变网络部分 :自适应的空间形变作用于五帧参考人脸图像的特征图上,得到形变后的特征图。
②修复网络部分 :使用一个特征解码器自适应的融合形变特征图中的口型特征和源人脸特征图中的其他属性,如头部姿态和上半边脸的表情。

l优势:不再使用网络直接合成嘴部的像素,而是对参考人脸图像的特征图做空间形变(像素移动),使用空间形变后的特征去修补嘴部区域
l缺陷:DINet可能受限于训练数据中人脸表情、光照条件、背景多样性等方面的覆盖不足(见另一个笔记),导致模型在未见过的场景下表现不佳;如何确保模型在不同语言、方言、说话速度以及各种情绪表达下的稳定表现(泛化能力不足)。
很通俗的理解:提取面部特征-->面部+嘴部深度学习-->抠嘴部图像(形变网络部分)-->修补嘴部区域(这里是像素移动!!并不是重新生成)-->得到新的推理视频
前期准备工作:
①安装CUDA;
②安装Anaconda;
③安装pytorch;(这个我在代码复现中才下载,并没有提前下载好,因为每个项目实现环境可能会对应不同的pytorch)
代码复现:
第一步:git项目源代码
第二步:数据集准备
①需要准备人脸关键点的检测图(下载openface源码,编译程序,导入程序分析可得)
注意:openface也是需要从github上下载的,这个也是开源的,以下是下载网址:
我会在第三步教大家如何编译使用openface
②asserts.zip 将该文件放在项目的根目录,并解压到 asserts 文件夹(文件夹包括训练文件,运行视频中提取帧文件、数据训练模型等)
注意:如果你可以翻墙下载的话请忽略此条注意。在github上需要在跳转到谷歌云盘下,不翻墙的话网页进都进不去,所以我找到了下载该文件的国内镜像网站:KrispOo/DINet at main (hf-mirror.com)
这个网站里面有许多开源代码以及模型下载,十分方便,下载十分迅速!!
第三步:openface安装步骤及使用
步骤一:下载openface源码解压包并解压
步骤二:解压后,执行文件夹中的脚本 download_libraries.ps1。该脚本是下载三个文件名后缀为.dll的文件。如果无法打开或下载(下载中断、或者闪退)。可以用记事本(.txt)方式打开该脚本,下载所需的三个dll文件:①opencv_ffmpeg410_64.dll ②opencv_world410.dll ③opencv_world410d.dll
这里只展示第一个文件的下载图片,后面两个文件以此类推

64位机器的话下载对应x64文件的,62位机器的话下载对应x32文件的。
注意:下载需要翻墙。如果不翻墙的话可以尝试一下:复制dropdox下载方式网址到迅雷下载,但是经过我的实测,用迅雷下载的话只能下载成功第一个,后面几个根本下载不下来,必须要翻墙下载!!!
步骤三:执行文件夹中的脚本download_models.ps1,同步骤二一样,运行后会跳出.txt形式的文件,然后寻找对应文件的下载网址。该脚本是下载四个文件名后缀为.dat的模型文件。同上,必须要翻墙下载!
将下载好的四个文件放置在:E:\OpenFace-master\lib\local\LandmarkDetector\model\patch_experts(这是我的地址,参考自己的电脑,放置在合适的文件夹中)

步骤四:后面几步我是参照以下网址做的,因为其中涉及到安装Visual Studio 2017安装配置,所以请大家进入以下网站进行安装配置并编译:
OpenFace 2.2.0安装步骤 - Wang_Peicheng - 博客园 (cnblogs.com)
步骤五:配置成功后并成功编译后,会在文件夹里出现这样一个文件:

这个文件就是最后的运行文件了,点开并运行,出现这样的界面:

点击上面的设置,点开后按照这样配置,按照以下图片进行选择:







然后openface界面会变成这样:

第四步:可以导入图片文件、视频文件,由于本题目需要提取视频中的人脸关键点的检测图,要得到对应的landmarks序列,所以在导入视频后,效果如图所示:


注意:生成的文件有三个①.csv②.avi③.txt,存放在openface/processed文件中,这三个文件如下图所示:(我自己的电脑是存在这:E:\OpenFace\processed中)

第五步:将openface生成的.csv文件添加到E:\Code_Dinet\DINet-master\asserts\training_data\split_video_25fps_landmark_openface,这个路径是你下载的Dinet模型源码的文件中,按照我的路径找到相对应的文件夹
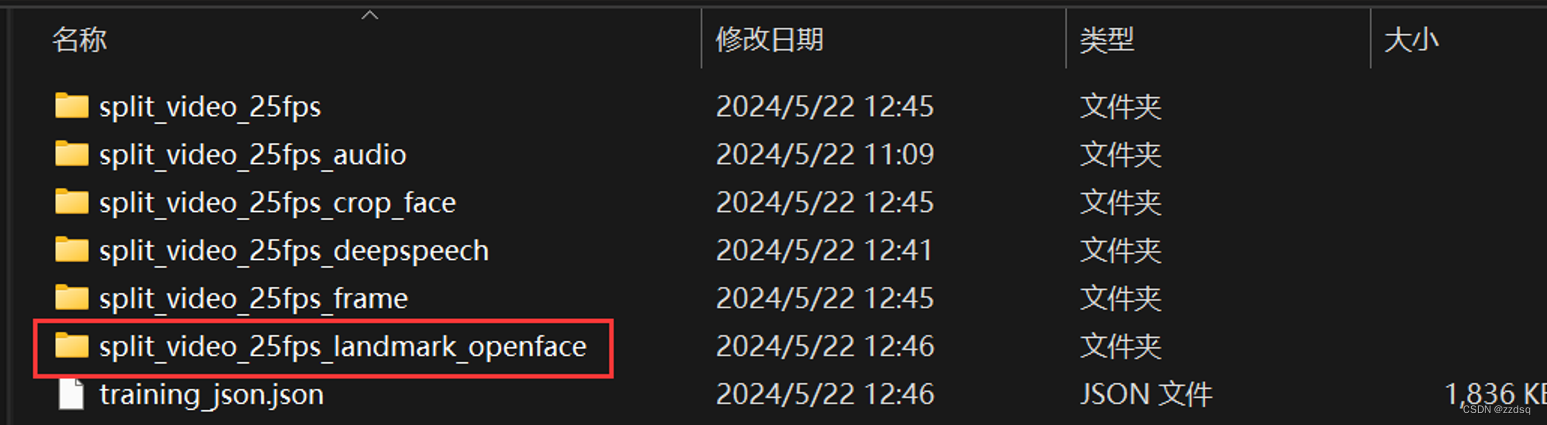
注意:要将对应的文件放在相应的数据集中,并且只把.csv文件剪贴加入即可
第六步:将自己所转换相对应的.mp4文件放进E:\Code_Dinet\DINet-master\asserts\training_data\split_video_25fps
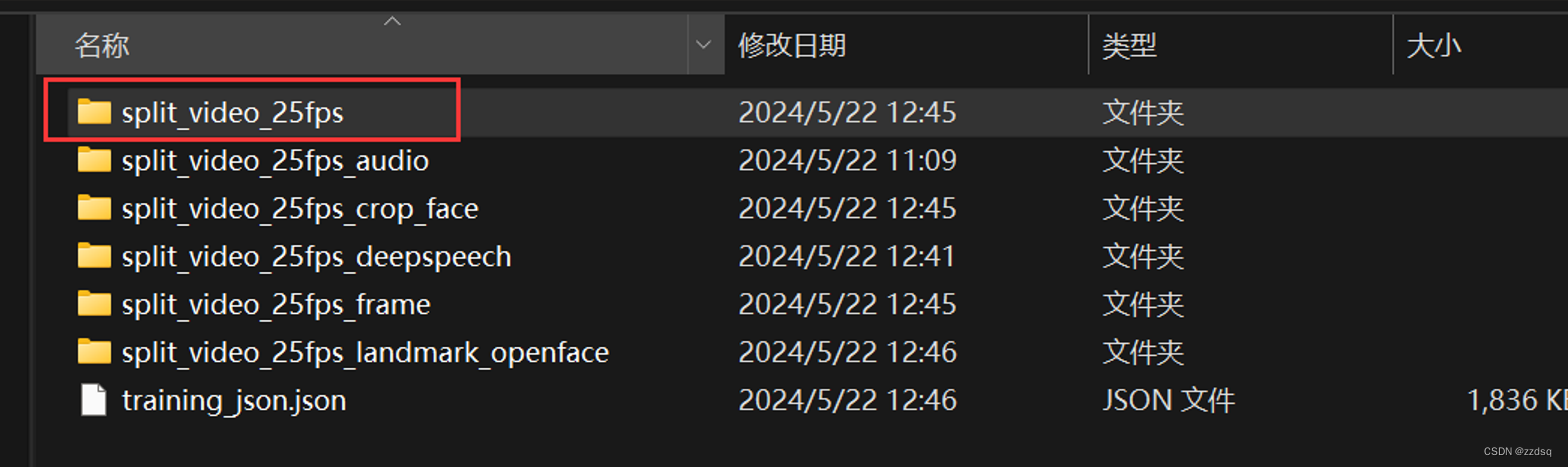
第七步:使用pycharm运行项目文件,并搭建环境python3.10,如下图所示:

第八步:先在training_data文件夹中自己创建文件:split_video_25fps_frame。在终端输入指令:python data_processing.py --extract_video_frame。从所有视频中提取帧并将帧保存在“./asserts/training_data/split_video_25fps_frame”中,文件夹内的文件如下图所示:

说明:从第八步开始,到第十二步结束,该阶段都是数据集预处理部分!!
补充:数据预处理部分报错解决:
错误一:报错ModuleNotFoundError: No module named ‘python_speech_features‘等等,会报错许多模块,只需要使用命令行 pip install+缺失模块的名称 ,许多这种报错!!
错误二:pycharm中调用FFmpeg命令行报错显示不是内部或外部命令,是由于未安装对应版本的ffmpeg,并配置环境路径,如图所示:
安装方法网址:ffmpeg安装教程(windows版)_windows ffmpeg安装-CSDN博客

在安装完ffmpeg后,如果你也在Windows中配置了环境,但是仍然报错,请重启pycharm软件;如果还是不行的话,按着我下面的网址中的步骤进行解决:
pycharm中调用FFmpeg命令行报错显示不是内部或外部命令,也不是可运行的程序解决办法_ffmpeg' 不是内部或外部命令,也不是可运行的程序-CSDN博客
错误三:报错:ImportError: cannot import name ‘Literal‘ from ‘typing‘
错误产生原因:这是由于 ‘Literal’ 只支持python3.8版本以上的,对于python3.7并不支持,但是我的电脑恰恰装的就是PYTHON3.7,所以需要在代码里手动导入导入 Literal 库。
注意:修改的时候需要把报错的那个.py文件那一行删除(具体哪个文件我忘记了,因为当时没有记录),然后添加如图所示的代码,我已经用红框框住了。

错误四:ImportError: Numba needs NumPy python3.8 or greater. Got python3.7
原因:这是由于numba与numpy的版本不能相互匹配,如果要升级python3.7-->3.8,卸载会非常麻烦,会破坏许多依赖关系,所以,我们可以降低numba的版本,使之可以适应numpy的版本
输入命令行:pip install numba=0.51
错误五:TypeError: guvectorize() missing 1 required positional argument 'signature'
解决方法:pip install resampy==0.3.1
错误六:Torch not compiled with CUDA enabled
错误原因:这是因为我没有安装GPU版本的torch,跑数据集预处理的时候需要在GPU上运行,所以需要安装对应电脑CUDA版本的GPU版本的torch即可。
安装命令行:pip install torch==1.13.0+cu117 torchvision==0.15.1+cu117 torchaudio==0.13.0+cu117 -f https://download.pytorch.org/whl/torch_stable.html
注释:应该还有一些错误,但是有的因为实现项目的过程中没有全部记录下来,但从我自身电脑运行项目的过程中,遇到的错误都可以搜到,例如:CSDN、博客园、github里的讨论区,并没有特别难的问题,故这里就展示我能想起来的六个错误!
第九步:先创建文件夹split_video_25fps_audio;输入命令行:python data_processing.py --extract_audio;从所有视频中提取音频并将音频保存在“./asserts/training_data/split_video_25fps_audio”中
注意:一定要选取带有音频的数据视频,否则这一步会报错,以及在后面的一步也会报错,因为缺少与对应mp4相关的音频源

第十步:先创建文件夹split_video_25fps_deepspeech,输入命令行:python data_processing.py --extract_deep_speech ,从所有音频中提取深度语音特征并将特征保存在“./asserts/training_data/split_video_25fps_deepspeech”中

第十一步:先创建文件夹:split_video_25fps_crop_face;输入命令行:python data_processing.py --crop_face 从所有视频中裁剪面部并将图像保存在“./asserts/training_data/split_video_25fps_crop_face”中

文件夹内容展示:


第十二步:创建.json文件,输入命令行:python data_processing.py --generate_training_json ;生成训练 json 文件“./asserts/training_data/training_json.json” (存储模型的配置参数和训练过程中的日志信息)

第十三步:输入命令行:python train_DINet_frame.py --augment_num=32 --mouth_region_size=64 --batch_size=24 --result_path=./asserts/training_model_weight/frame_training_64
说明:从第十三步开始,到第十六步都属于模型训练部分!!
首先,以 104x80(嘴部区域为 64x64)分辨率训练 DINet:
注意:如果你电脑显存非常大,无需注意这段!!
这里可能会报错:直接使用github上的命令行会出现错误,会炸显存,因为我的电脑显卡是3050的,GPU专用内存只有4GB(拯救者3050的GPU),所以跑模型训练部分非常吃力,64*64的训练起来还可以承受,将命令行中的batch_size改为batch_size=15,每次训练模型的大小向小改一点,这样造成的效果只是训练效果非常非常慢
训练说明:因为训练慢,并且训练出来的文件内存很大,由于内存限制,迭代次数会少


说明:这仅仅是第一个命令迭代了178次 ,就占用了21.7GB,因为受内存限制直接导致训练次数可能会少,导致效果并不是很好。
第十四步:输入命令行:python train_DINet_frame.py --augment_num=100 --mouth_region_size=128 --batch_size=80 --coarse2fine --coarse_model_path=./asserts/training_model_weight/frame_training_64/netG_model_epoch_178.pth(参考源码中README文件,这个是添加你上述步骤中迭代过程中最优的模型,自行选择) --result_path=./asserts/training_model_weight/frame_training_128
说明:迭代上一次的64分辨率训练最优模型,加载预训练模型(面部:104x80 和嘴巴:64x64)并以更高分辨率训练 DINet(面部:208x160 和嘴巴:128x128)
注意:因为还是由于GPU大小限制,故调整batch_size才能训练模型,这个阶段非常非常慢,迭代一次需要大概4分钟及以上
过程很慢,占用内存大,所以这一阶段一共迭代了28次(注意:如果你的内存以及GPU运行,你必须迭代许多次,保证当损失收敛时,你可以停止训练,关于收敛判断,可以观察输出日志中的学习率参数 lr_g 当它到原来的 50% 就差不多了,下同)
第十五步:输入命令行:python train_DINet_frame.py --augment_num=20 --mouth_region_size=256 --batch_size=12 --coarse2fine --coarse_model_path=./asserts/training_model_weight/frame_training_128/netG_model_epoch_28.pth(参考源码中README文件,这个是添加你上述步骤中迭代过程中最优的模型,自行选择) --result_path=./asserts/training_model_weight/frame_training_256
说明:迭代上一次的128训练最优模型,加载预训练模型(面部:208x160 和嘴巴:128x128)并以更高分辨率训练 DINet(面部:416x320 和嘴巴:256x256)
这一阶段一共迭代32次(同上注意!!)
第十六步:输入指令:python train_DINet_clip.py --augment_num=3 --mouth_region_size=256 --batch_size=3 --pretrained_syncnet_path=./asserts/syncnet_256mouth.pth --pretrained_frame_DINet_path=./asserts/training_model_weight/netG_model_epoch_32.pth(参考源码中README文件,这个是添加你上述步骤中迭代过程中最优的模型,自行选择) --result_path=./asserts/training_model_weight/clip_training_256
(注释:最后模型的效果非常差与这一步有很大的关系)
在本步骤中,调整batch_size的大小即使调整到1,都还是会爆显存,这显然就不能用mouth_region_size=256来实现,我改成128,仍然爆显存,所以我又改成64并且将batch_size调整成3,才可以运行,
虽然生成速度变快了,并且迭代次数也变多了(迭代了194次),但是由于嘴巴部分没有进行更高分辨率的训练,导致后面的模型效果性特别差。
当然,你的显存很牛的话,当我这些话没说,加强迭代次数,训练出特别好的模型来!!

最终训练完成,目录结构如下,其中 clip_training_256 中我们推理要使用的模型:

推理:
第一步:E:\Code_Dinet\DINet-master\Dinet中创建输入文件夹inputs(这是Dinet源码在我电脑里的路径)
第二步:在inputs中创建音频、视频以及openface提取的人脸landmarks文件夹,如下图所示:

第三步:运行代码:python inference.py --mouth_region_size=256 --source_video_path=./DINet/inputs/video/test.mp4 --source_openface_landmark_path=./DINet/inputs/csv/test.csv --driving_audio_path=./DINet/inputs/audio/lyl.wav --pretrained_clip_DINet_path=./asserts/training_model_weight/clip_training_256/netG_model_epoch_194.pth(我们最终推理所需要的模型)
①提取信息:

②分析提取的视频帧:

③最终结果:一共生成三个文件,不加音频的面部展示信息test_facial_dub,最后的结果视频test_facial_dub_bing_add_audio,合成的面部分析文件text_syntheic_face,生成的文件存在E:\Code_Dinet\DINet-master\asserts\inference_result(这是我自己的路径)

最后,查看自己经过推理模型后的视频!!完结!!感谢大家的阅读!!!















 7771
7771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









