







本文主要介绍DINet网络,来源于2023年AAAI顶会的文章。
DINet网络主要实现高分辨率图像的面部配音,包含形变和修复两个部分。以前的网络主要通过特征数据生成嘴部像素,作者认为在高分辨率图像下,通过少量的语音特征数据生成的嘴部像素会相对模糊,因此作者提出首先利用形变网络部分分别编码原人脸头部姿态特征和驱动音频的语音内容,然后利用这些特征去将参考人脸进行形变操作,最后修复网络部分通过卷积层合并原始人脸特征与形变结果,去修复原始嘴巴区域的像素。其网络结构如下图(图片来自网上):
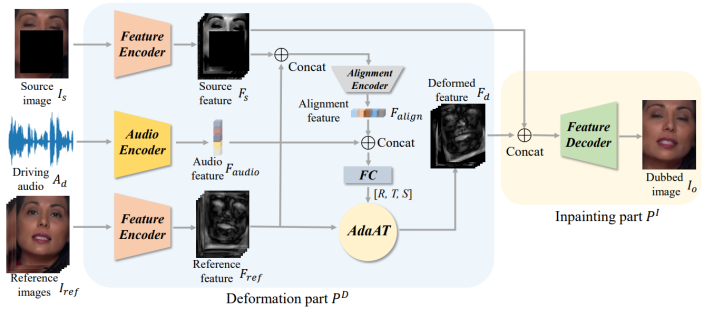
对于三个输入,
1. 原图,实际上是截取面部的一张图片,图片大小取决于算法训练时的分辨率,比如嘴部分辨率为256x256时,面部大小为416x320,计算如下:
resize_w = int(opt.mouth_region_size + opt.mouth_region_size // 4)
resize_h = int((opt.mouth_region_size // 2) * 3 + opt.mouth_region_size // 8)实际工程中这个原图一般是一段视频的其中一帧,通过脸部处理工具OpenFace的帮助,可以得到这一帧图像的脸部截图,接着resize到(320,416),然后归一化处理,最后是将嘴部区域像素点值置为0并在送入模型之前将WHC格式转换为NCHW,代码如下:
crop_frame_data = cv2.resize(crop_frame_data, (resize_w,resize_h)) crop_frame_data = crop_frame_data / 255.0
crop_frame_data[opt.mouth_region_size//2:opt.mouth_region_size//2 + opt.mouth_region_size,
opt.mouth_region_size//8:opt.mouth_region_size//8 + opt.mouth_region_size, :] = 0
crop_frame_tensor = torch.from_numpy(crop_frame_data).float().permute(2, 0, 1).unsqueeze(0)当
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











