








前言
项目地址:https://github.com/Fafa-DL/Awesome-Backbones
操作教程:https://www.bilibili.com/video/BV1SY411P7Nd
Transformer in Transformer原论文:点我跳转
1. 数据集制作
1.1 标签文件制作
-
将项目代码下载到本地
-
本次演示以花卉数据集为例,目录结构如下:
├─flower_photos
│ ├─daisy
│ │ 100080576_f52e8ee070_n.jpg
│ │ 10140303196_b88d3d6cec.jpg
│ │ ...
│ ├─dandelion
│ │ 10043234166_e6dd915111_n.jpg
│ │ 10200780773_c6051a7d71_n.jpg
│ │ ...
│ ├─roses
│ │ 10090824183_d02c613f10_m.jpg
│ │ 102501987_3cdb8e5394_n.jpg
│ │ ...
│ ├─sunflowers
│ │ 1008566138_6927679c8a.jpg
│ │ 1022552002_2b93faf9e7_n.jpg
│ │ ...
│ └─tulips
│ │ 100930342_92e8746431_n.jpg
│ │ 10094729603_eeca3f2cb6.jpg
│ │ ...
- 在
Awesome-Backbones/datas/中创建标签文件annotations.txt,按行将类别名 索引写入文件;
daisy 0
dandelion 1
roses 2
sunflowers 3
tulips 4

1.2 数据集划分
- 打开
Awesome-Backbones/tools/split_data.py - 修改
原始数据集路径以及划分后的保存路径,强烈建议划分后的保存路径datasets不要改动,在下一步都是默认基于文件夹进行操作
init_dataset = 'A:/flower_photos'
new_dataset = 'A:/Awesome-Backbones/datasets'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/split_data.py
- 得到划分后的数据集格式如下:
├─...
├─datasets
│ ├─test
│ │ ├─daisy
│ │ ├─dandelion
│ │ ├─roses
│ │ ├─sunflowers
│ │ └─tulips
│ └─train
│ ├─daisy
│ ├─dandelion
│ ├─roses
│ ├─sunflowers
│ └─tulips
├─...
1.3 数据集信息文件制作
- 确保划分后的数据集是在
Awesome-Backbones/datasets下,若不在则在get_annotation.py下修改数据集路径;
datasets_path = '你的数据集路径'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/get_annotation.py
- 在
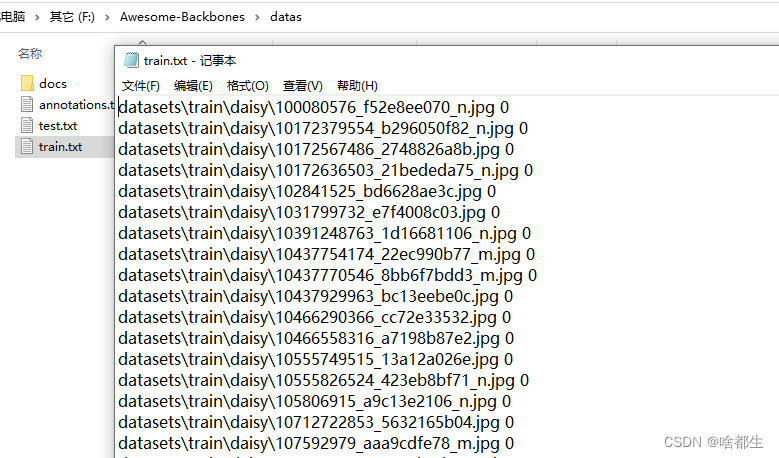
Awesome-Backbones/datas下得到生成的数据集信息文件train.txt与test.txt
2. 修改参数文件
- 每个模型均对应有各自的配置文件,保存在
Awesome-Backbones/models下 - 由
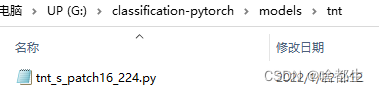
backbone、neck、head、head.loss构成一个完整模型 - 找到Transformer in Transformer参数配置文件
- 在
model_cfg中修改num_classes为自己数据集类别大小 - 按照自己电脑性能在
data_cfg中修改batch_size与num_workers - 若有预训练权重则可以将
pretrained_weights设置为True并将预训练权重的路径赋值给pretrained_weights - 若需要冻结训练则
freeze_flag设置为True,可选冻结的有backbone, neck, head - 在
optimizer_cfg中修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小 - 学习率更新详见
core/optimizers/lr_update.py - 更具体配置文件修改可参考配置文件解释
3. 训练
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下train.txt与test.txt与annotations.txt对应 - 选择想要训练的模型,在
Awesome-Backbones/models/下找到对应配置文件 - 按照
配置文件解释修改参数 - 在
Awesome-Backbones打开终端运行
python tools/train.py models/tnt/tnt_s_patch16_224.py
4. 评估
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下test.txt与annotations.txt对应 - 在
Awesome-Backbones/models/下找到对应配置文件 - 在参数配置文件中修改权重路径,其余不变
ckpt = '你的训练权重路径'
- 在
Awesome-Backbones打开终端运行
python tools/evaluation.py models/tnt/tnt_s_patch16_224.py
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











