







🌞欢迎来到深度学习实战的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年2月12日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

RNN介绍
RNN(Recurrent Neural Network) 是一种用于处理序列数据的神经网络模型,特别适用于
处理时间序列、语音、文本等具有顺序关系的数据。
简单的神经网络都是水平方向的延申,RNN可以关联不同的时刻,RNN的输出不仅取决于当前
时刻的输出还取决于上一时刻隐藏层的输出。(神经网络具有某种记忆的能力)

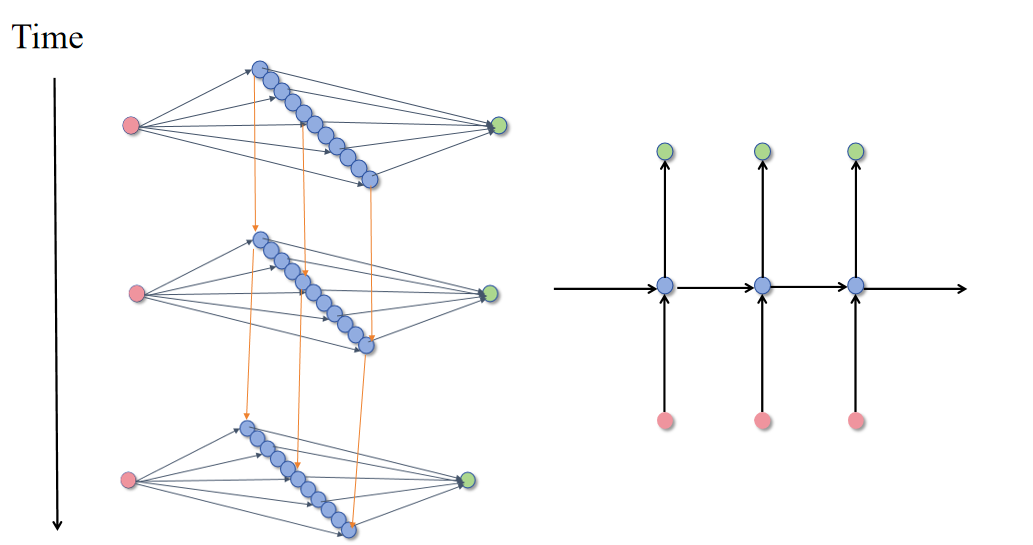
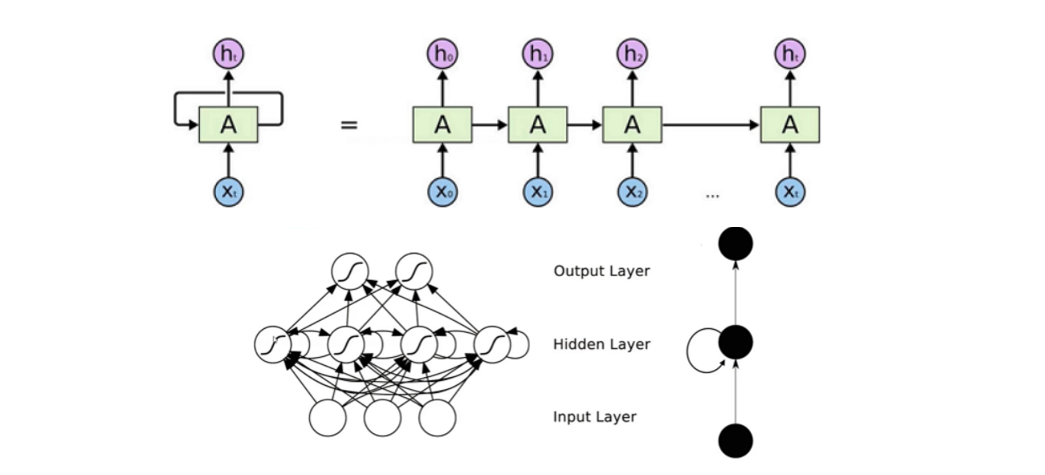
举个例子(使用RNN进行情感分类)
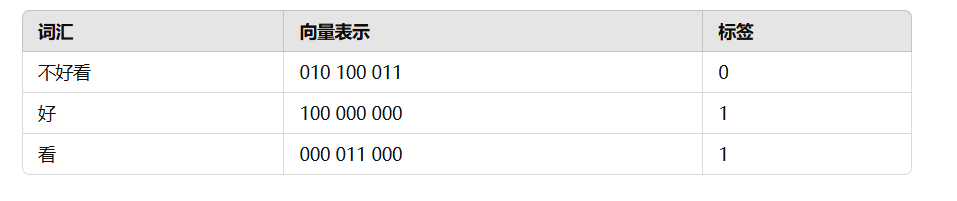
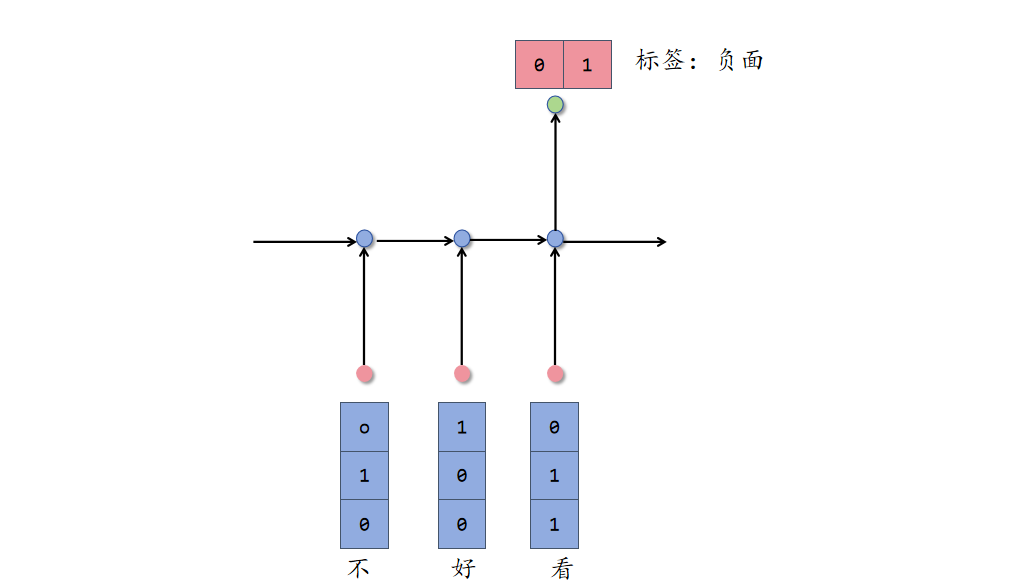
手算模拟

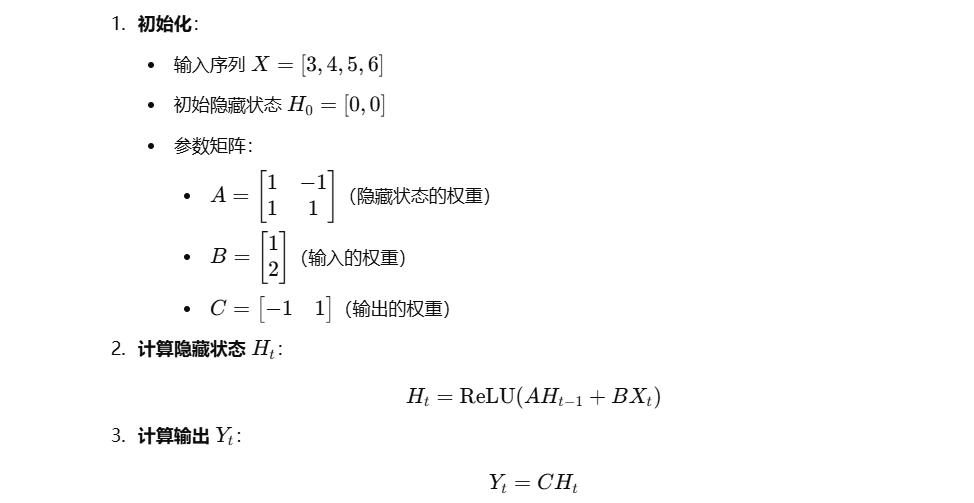
代码实现
import torch
import torch.nn as nn
# 设置随机种子保证结果可复现
torch.manual_seed(42)
# 定义超参数
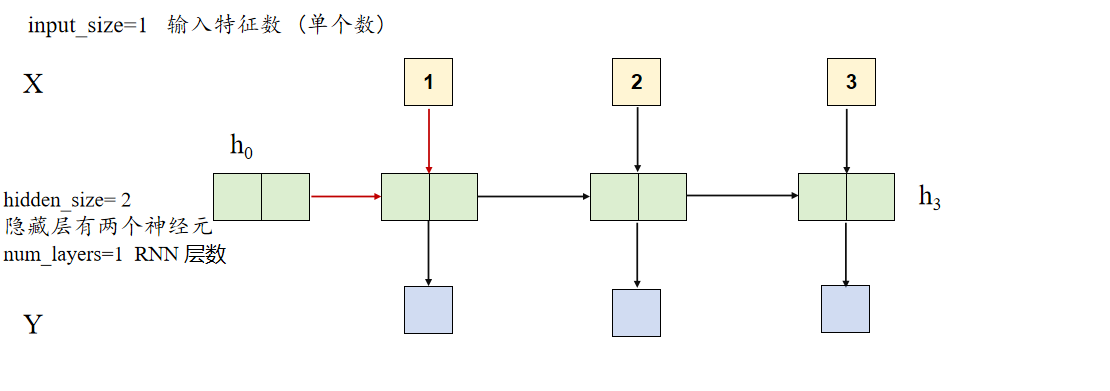
input_size = 1 # 输入特征数 (单个数)
hidden_size = 2 # 隐藏层大小 (两个神经元)
num_layers = 1 # RNN 层数
seq_length = 3 # 序列长度 (3 个时间步)
batch_size = 1 # 只有 1 个样本
# 创建 RNN
rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
# 人工设定权重和偏置(方便计算)
with torch.no_grad():
rnn.weight_ih_l0.copy_(torch.tensor([[0.5], [-0.5]], dtype=torch.float32)) # 输入到隐藏层的权重
rnn.weight_hh_l0.copy_(torch.tensor([[0.3, -0.3], [0.6, -0.6]], dtype=torch.float32)) # 隐藏层到隐藏层
rnn.bias_ih_l0.zero_() # 输入层偏置设为 0
rnn.bias_hh_l0.zero_() # 隐藏层偏置设为 0
# 输入数据 (时间步数为 3)
X = torch.tensor([[[1.0], [2.0], [3.0]]]) # 形状 (batch_size, seq_length, input_size)
# 初始化隐藏状态 (全零)
h0 = torch.zeros(num_layers, batch_size, hidden_size)
# 进行前向传播
out, hn = rnn(X, h0)
# 打印输出
print("隐藏状态 Ht (每个时间步):\n", out.detach().numpy()) # 所有时间步的隐藏状态
print("\n最终隐藏状态 hn:\n", hn.detach().numpy()) # 最后一个时间步的隐藏状态
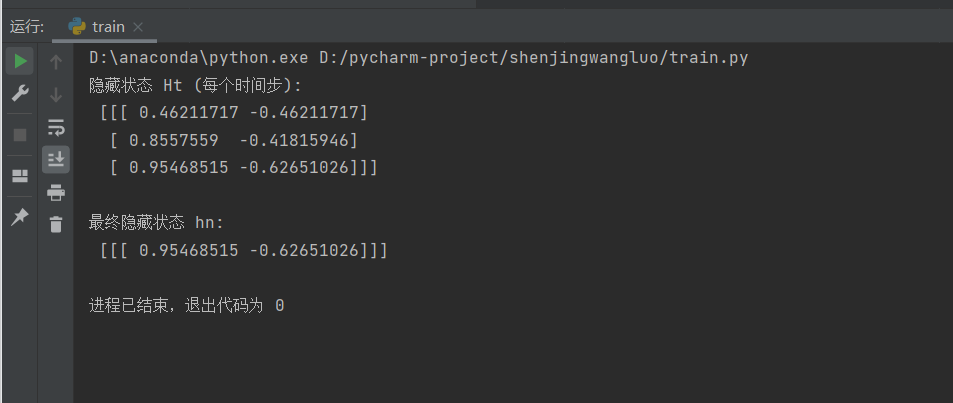
实战
# --------------------------
# 修正 NumPy 中已废弃的别名(np.object、np.bool、np.int)
# --------------------------
import numpy as np
np.object = object
np.bool = bool
np.int = int
# --------------------------
# 导入所需的库
# --------------------------
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# --------------------------
# 1. 生成中文情感分类数据集
# --------------------------
# 简单数据集包含正面和负面句子
texts = [
"我喜欢这个产品", "这真是太棒了", "我讨厌这个商品", "质量差劲",
"简直太棒了", "最糟糕的购买", "我对这个感觉很好", "不好",
"我对这个很满意", "这个真糟糕", "我喜欢使用这个", "非常失望"
]
# 标签:1表示正面,0表示负面
labels = [1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0]
# 划分训练集和测试集(70%训练,30%测试)
X_train, X_test, y_train, y_test = train_test_split(texts, labels, test_size=0.3, random_state=42)
# --------------------------
# 2. 文本预处理:使用 Keras 的 Tokenizer 进行向量化和序列填充
# --------------------------
# 定义最大词数,构建 Tokenizer 对象
tokenizer = Tokenizer(num_words=10000)
tokenizer.fit_on_texts(X_train)
# 将文本转换为数字序列
X_train_seq = tokenizer.texts_to_sequences(X_train)
X_test_seq = tokenizer.texts_to_sequences(X_test)
# 对序列进行填充,使得所有句子长度一致(此处设为10)
maxlen = 10
X_train_pad = pad_sequences(X_train_seq, padding='post', maxlen=maxlen)
X_test_pad = pad_sequences(X_test_seq, padding='post', maxlen=maxlen)
# --------------------------
# 3. 将数据转换为 PyTorch Tensor
# --------------------------
X_train_tensor = torch.tensor(X_train_pad, dtype=torch.long)
X_test_tensor = torch.tensor(X_test_pad, dtype=torch.long)
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)
# --------------------------
# 4. 定义 RNN 模型(使用 PyTorch 构建)
# --------------------------
class RNNModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super(RNNModel, self).__init__()
# 嵌入层:将词索引转换为词向量
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# RNN 层:这里使用 nn.RNN,参数 batch_first=True 保证输入维度为 (batch, seq, feature)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
# 全连接层,将 RNN 的输出映射到情感分类(1维输出)
self.fc = nn.Linear(hidden_dim, output_dim)
# Sigmoid 激活函数,将输出转换为 0~1 之间的概率
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: (batch_size, seq_length)
x = self.embedding(x) # 输出形状: (batch_size, seq_length, embedding_dim)
out, _ = self.rnn(x) # out: (batch_size, seq_length, hidden_dim)
out = out[:, -1, :] # 取最后一个时刻的输出: (batch_size, hidden_dim)
out = self.fc(out) # 全连接层映射: (batch_size, output_dim)
out = self.sigmoid(out) # 输出概率: (batch_size, output_dim)
return out
# 定义超参数
vocab_size = 10000 # 词汇表大小
embedding_dim = 128 # 嵌入层维度
hidden_dim = 64 # RNN 隐藏层维度
output_dim = 1 # 输出维度(1 表示二分类任务)
# 初始化模型
model = RNNModel(vocab_size, embedding_dim, hidden_dim, output_dim)
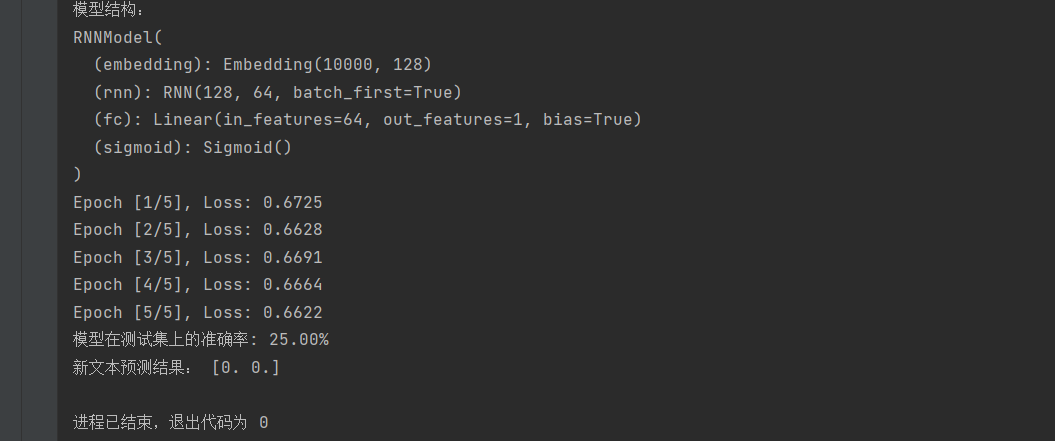
print("模型结构:")
print(model)
# --------------------------
# 5. 训练模型
# --------------------------
# 定义损失函数(BCELoss 适用于二分类任务)和优化器(Adam)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 5
batch_size = 4 # 此示例中数据集较小,可直接一次性传入
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# 前向传播
outputs = model(X_train_tensor) # 输出形状: (batch_size, 1)
outputs = outputs.squeeze(1) # 去除多余维度 -> (batch_size)
loss = criterion(outputs, y_train_tensor)
# 反向传播和更新参数
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# --------------------------
# 6. 评估模型在测试集上的表现
# --------------------------
model.eval()
with torch.no_grad():
test_outputs = model(X_test_tensor).squeeze(1)
# 将概率转换为 0/1 标签,阈值设置为 0.5
predicted = (test_outputs > 0.5).float()
correct = (predicted == y_test_tensor).sum().item()
accuracy = correct / len(y_test_tensor)
print(f'模型在测试集上的准确率: {accuracy * 100:.2f}%')
# --------------------------
# 7. 使用模型对新文本进行预测
# --------------------------
new_texts = ["我非常喜欢我的购买", "这个产品真的很糟糕"]
new_seq = tokenizer.texts_to_sequences(new_texts)
new_pad = pad_sequences(new_seq, padding='post', maxlen=maxlen)
new_tensor = torch.tensor(new_pad, dtype=torch.long)
model.eval()
with torch.no_grad():
predictions = model(new_tensor).squeeze(1)
predicted_labels = (predictions > 0.5).float()
print("新文本预测结果:", predicted_labels.numpy())



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











