









快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,实现简单,而且效率高,适合于各种输入数据,它是处理大数据最快的排序算法之一了。
快速排序令人瞩目的特点就是它是原地排序(排序过程中不申请多余的存储空间),且将长度为N的数组排序所需要的时间和NlogN成正比,其他排序算法都无法将以上两个优点相结合。
它的主要缺点是非常脆弱,在现实的时候需要非常小心才能避免低劣的性能。
基本思想
通过一趟排序将要排序的数据分割成独立的两个部分,选择一个数作为基准,目的是让该数左边的数都比它小,右边的数都比它大。然后按照此方法对两部分分别进行快速排序,整个排序过程可以使用递归的方法进行。
一般把数组中最左边的第一个数当做基准数,然后从两边开始检索,先从右边开始检索比基准数小的数,再从左边检索比基准数大的,如果检索到了就停下,然后交换这两个数,一轮检索完成。
例如一组数据:
| 10 | 15 | 8 | 12 | 4 | 9 | 14 |
选第一给我数字10作为基准,从右边开始检索比10小的数,再从左检索到比10大的数,那么就分别检索到了9和15,交换这两个数:
| 10 | 9 | 8 | 12 | 4 | 15 | 14 |
继续检索,分别检索到了4和12,交换它们:
| 10 | 9 | 8 | 4 | 12 | 15 | 14 |
继续向右检索时,都检索到4所处的位置(两个指针相遇),停止检索,将4与10交换:
| 4 | 9 | 8 | 10 | 12 | 15 | 14 |
第一轮排序结束,此时10的左边都是比10小的数,10的右边都是比10大的数。
以后先排基准数左边,再排基准数右边,排序方式和第一轮一致。
代码实现
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
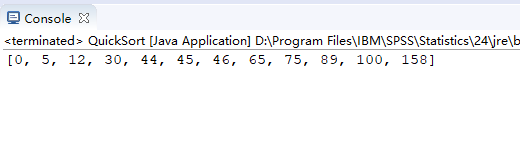
int[] arr = {100,45,89,158,75,65,12,5,46,30,44,0};
sort(arr,0,arr.length-1);
System.out.println(Arrays.toString(arr));
}
//快速排序算法,三个输入参数
//第一个为矩阵,left为从哪个参数开始排,right为排到哪个参数,从left排到right
public static void sort(int[] arr, int left, int right) {
if(left > right) {
return;
}
//定义变量保存基准数
int base = arr[left];
//定义i指向最左边
int i = left;
//定义j指向最右边
int j = right;
//当i和j不相遇时,在循环中进行检索
while(i != j)
{
//从右开始检索比基准数小的数,如果检索到就停下来
while(arr[j]>=base && i<j) {
j--;
}
//从左开始检索比基准数大的数,如果检索到就停下来
while(arr[i]<=base && i<j) {
i++;
}
//跳出循环说明都检索到了,交换这两个值
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
//跳出这个循环说明i和j相遇了,则基准书与相遇位置元素交换
arr[left] = arr[i];
arr[i] = base;
//此时,基准数左边的数都比基准数小,右边的都比基准数大
//排序左边
sort(arr,left,i-1);
//排序右边
sort(arr,i+1,right);
}
}
特点
时间复杂度比较复杂,最好的情况是O(n),最差的情况是O(n2),所以平时说的O(nlogn),为其平均时间复杂度。
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度就提高了。
快速排序在被排序的数据完全无序情况下最易发挥其长处。
















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











