







简介
ZooKeeper : 分布式应用程序协调服务;也是一个集群,内部干的事就是提供少量数据的存储和管理、提供对数据节点的监听器。
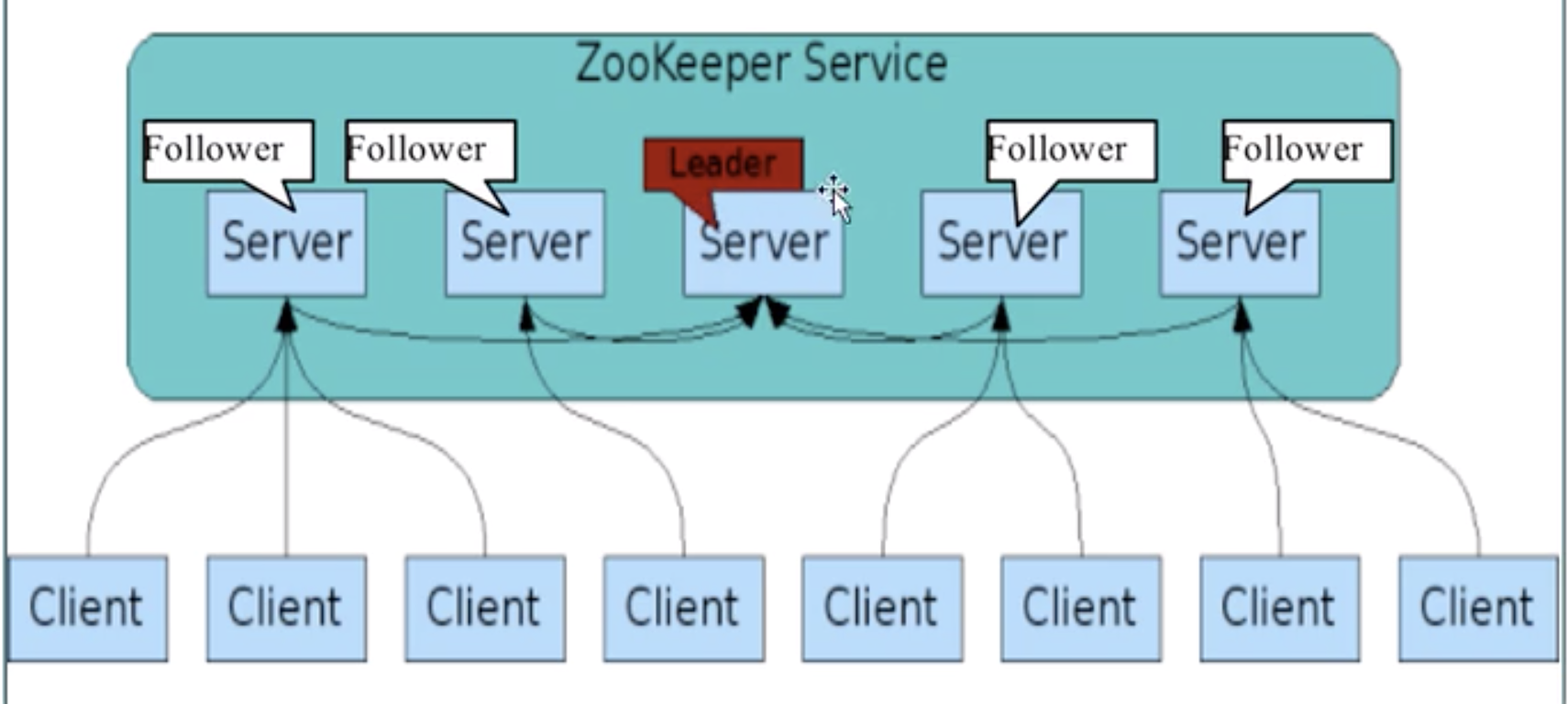
- 如果client往zookeeper集群里面写数据,先通过leader,leader得到数据再让follower去备份
- leader和follower的身份不是由搭建zookeeper之前的配置文件决定,而是服务起来之后通过选举机制划分的
- zookeeper正常工作需要集群中超过一半的节点正常工作
zookeeper的文件节点
zookeeper里面存储的文件是以文件的形式、树的结构存储,每个文件为一个Znode(文件节点)
- Znode有两种类型:短暂的(客户端和zookeeper集群断开之后数据丢失)、长期的(永久保存,除非手动删除),而且短暂的Znode不可有子节点
- Znode类型在创建的时候确定,之后不可修改
zookeeper的角色
- Leader:负责投票的发起和决议,跟新系统状态
- Follower:接收客户端请求并向客户端返回结果,在选举过程中参与投票
- Observer:可以接收客户端的请求,将请求转发给leader,但不参与投票,只同步leader状态。observer的目的是扩展系统,提高读取状态
- Client:请求发起方
ZooKeeper的应用场景
- 统一命名服务:
- 配置管理:配置文件的存储
- 集群管理:选举一个总管来管理整几个集群
- 共享锁:集群里面同时运行一个节点修改内容,锁的机制















 4038
4038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









