






0 Abstract
近年来,随着经济的快速发展,越来越多的人开始投资股票市场。准确预测股票价格的变化,可以降低股票投资者的投资风险,有效提高投资收益。由于股票市场的波动特征,股票价格预测往往是非线性的时间序列预测。股票价格受到多种因素的影响。很难通过一个简单的模型进行预测。因此,本文提出了一种CNN - BiLSTM - AM方法来预测未来一天的股票收盘价。该方法由卷积神经网络( CNN )、双向长短期记忆网络( Bi LSTM )和注意力机制( AM )组成。CNN用于提取输入数据的特征。Bi LSTM利用提取的特征数据预测次日股票收盘价。AM用于捕捉过去不同时刻特征状态对股票收盘价的影响,以提高预测精度。为了证明本文方法的有效性,采用本文方法和其他7种方法对上证综指1000个交易日的次日股票收盘价进行预测。结果表明,该方法的性能最好,MAE和RMSE均为最小的(分别为21.952和31.694)。R2是最大的(其值为0.9804)。与其他方法相比,CNNBiLSTM - AM方法更适用于股票价格的预测,为投资者进行股票投资决策提供了可靠的途径。
1 Introduction
股票市场是股票可以转让、交易和流通的场所。它已有400多年的历史,可以作为企业筹集资金的渠道[ 1 ]。通过发行股票,大量资本流入股票市场。这促进了资本的集中,提高了企业资本的有机构成,极大地推动了商品经济的发展。因此,股票市场被视为一个国家或地区经济金融活动的晴雨表。中国股票市场起步晚于西方股票市场。中国股票市场建立于20世纪90年代初。虽然中国股票市场起步较晚,但中国股票市场的市场规模和组织结构与西方股票市场相当。随着中国经济的快速发展,股票市场的规模迅速扩大,越来越多的人进入其中,参与股票投资[ 3、4]。
股票市场中投资者最为关注的问题之一就是股票价格的变化趋势[ 5 ]。股票价格受多种因素的影响,如国家政策的变化、国内外经济环境、国际形势等。[ 6、7]。股票价格的变化往往是非线性的。提前预测股价变动一直是经济学家[ 8、9]关注的重要问题。对股票价格的变化做出合理准确的预测,可以大大降低投资者的投资风险。这样的预测可以让投资者将预测的股票价格纳入他们的投资策略,并帮助投资者最大化他们的投资收益。
为了更准确地预测股票价格,本文提出了一种基于CNN - BiLSTM - AM的方法来预测次日的股票收盘价。该模型由卷积神经网络( CNN )、双向长短期记忆网络( Bi LSTM )和注意力机制( AM )组成。CNN可以从输入的股票数据中提取特征。长短期记忆网络( LSTM )是对循环神经网络( RNN )的改进,避免了RNN带来的梯度消失和梯度爆炸问题。Bi LSTM可以充分发现股票时间序列数据的相互依赖关系。AM是一种能够获得较好结果的机制,能够捕捉到时间序列数据过去的特征状态对股票价格的影响。
本文的主要贡献如下:( 1 )通过分析股票价格数据的时序性和相关性,提出了一种新的深度学习方法CNNBiLSTM - AM来预测次日的股票收盘价。( 2 )根据过去特征状态对次日股票收盘价的影响程度,可以对AM进行加权计算过去特征状态,从而提高预测的准确性。( 3 )通过与其他七种机器学习方法预测股票价格进行对比,证明了CNN - BiLSTM - AM方法是最准确有效的,说明其更适用于预测股票价格。
2 Related work
3 CNN-BiLSTM-AM
3.1 CNN-BiLSTM-AM
CNN具有关注视线中最明显特征的特点,因此被广泛应用于特征工程中。Bi LSTM具有按时间序列扩展的特性,被广泛应用于时间序列分析。AM具有将时间序列数据的过去特征状态添加到输出结果中的重要神经计算和应用。在BiLSTM之后,它被更广泛地用于调整预测结果。根据CNN、BiLSTM和AM的特点,建立了基于CNN - BiLSTM - AM的股票预测模型。模型结构图如图1所示。主要结构为CNN、Bi LSTM和AM,包括输入层、CNN层(一维卷积层、池化层)、Bi LSTM层(正向LSTM层,反向LSTM层)、AM层和输出层。

3.2 CNN
CNN主要由卷积层、池化层、全连接层三部分组成[ 29 ]。每个卷积层包含多个卷积核,其计算如式( 1 )所示。经过卷积层的卷积操作后,提取数据的特征。然而,提取的特征维度非常高。所以为了解决这个问题,降低训练网络的成本,在卷积层之后加入池化层来降低特征维度

其中lt为卷积后的输出值,tanh为激活函数,xt为输入向量,kt为卷积核的权重,bt为卷积核的偏置
3.3 LSTM
LSTM是一种旨在解决RNN中长期存在的梯度爆炸和梯度消失问题的网络模型[ 32 ]。标准RNN只有一个重复模块,内部结构简单。它通常是一个tanh层。
3.4 AM
AM是由Treisman等人在1980年提出的[ 36 ]。通过计算注意力概率分布,从大量信息中筛选出关键信息,突出关键输入,对传统模型进行优化。AM的主要思想来源于人类的视觉注意过程。人类视觉可以快速找到关键区域,并在关键区域中添加注意力焦点,以获得所需的详细信息。同样,AM选择性地关注一些比较重要的信息,忽略不重要的信息,并分配信息的重要性。如图3所示,
 AM的计算过程一般分为三个阶段:
AM的计算过程一般分为三个阶段:
( 1 )计算Query (输出特征)和Key (输入特征)之间的相似度或相关性,如式( 8 )所示:

( 2 )对第一阶段的得分进行归一化处理,采用softmax函数对注意力得分进行转换,如式( 9 )所示:

( 3 )根据权重系数,对值进行加权求和得到最终的注意力值,如式( 10 )所示:
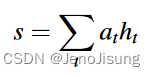
3.5 CNN-BiLSTM-AM Training Process
CNN - BiLSTM - AM训练过程如图4所示:
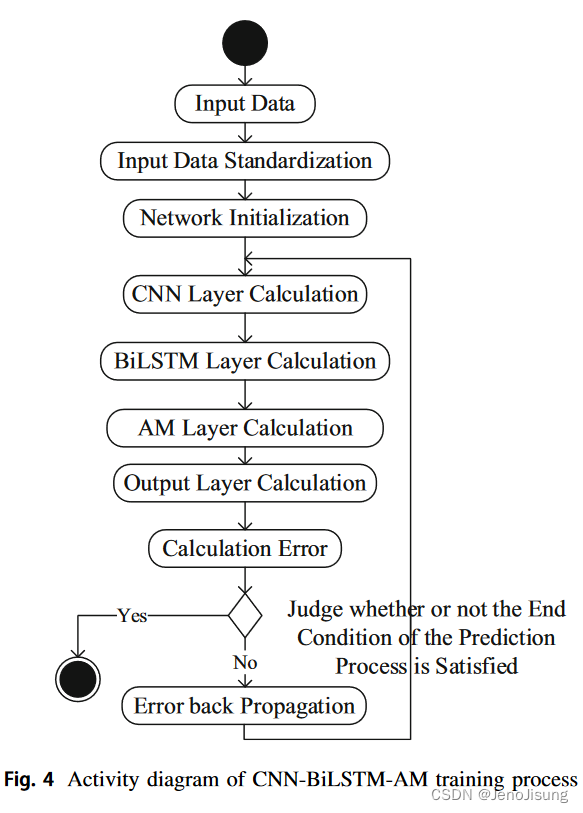
主要步骤如下:1 .输入数据:CNN - BiLSTMAM训练所需的数据输入2。输入数据标准化:由于输入数据存在较大差距,为了更好地训练模型,采用z - score标准化方法对输入数据进行标准化处理,如式( 11 )所示:

其中yi为标准化值,xi为输入数据,x为输入数据的平均值,s为输入数据的标准差。
( 3 )网络初始化:对CNN - BiLSTM - AM的每一层的权值和偏置进行初始化。
( 4 ) CNN层计算:输入数据依次经过CNN层内的卷积层和池化层,对输入数据进行特征提取,得到输出值。
( 5 ) BiLSTM层计算:通过BiLSTM层的隐含层计算CNN层的输出数据,得到输出值。
( 6 ) AM层计算:将BiLSTM层的输出数据通过AM层计算,得到输出值。
( 7 )输出层计算:计算AM层的输出值,得到模型的输出值。
( 8 )计算误差:将输出层计算得到的输出值与该组数据的真实值进行比较,计算相应的误差。
( 9 )判断是否满足预测过程的结束条件:成功结束的条件是完成预定的循环次数,权重低于某一阈值,预测的错误率低于某一阈值。如果至少满足结束的其中一个条件,则训练完成。否则,训练将继续进行。
( 10 )误差反向传播:将计算出来的误差反向传播,更新每一层的权重和偏置,然后回到步骤( 4 )继续进行网络训练。
3.6 CNN-BiLSTM-AM Prediction Process
CNN - BiLSTM - AM预测的前提条件是CNN - BiLSTM - AM已经完成训练。CNNBiLSTM - AM预测流程如图5所示。
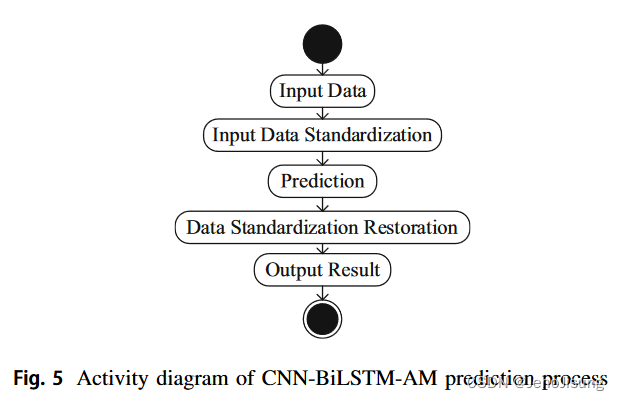
主要步骤如下:
( 1 )输入数据:输入预测所需的输入数据。
( 2 )输入数据标准化:根据公式( 11 )对输入数据进行标准化。
( 3 )预测:将标准化后的数据输入到训练好的CNN - BiLSTM - AM中,得到相应的输出值。
( 4 )数据标准化恢复:通过CNN - BiLSTM - AM得到的输出值即为标准化值。利用公式( 12 )将标准化值还原为原始值:
其中xi为标准化恢复值,yi为CNN - BiLSTM - AM的输出值,s为输入数据的标准差,x为输入数据的平均值。
( 5 )输出结果:输出恢复结果,完成预测过程。
4 Experiments
4.1 数据
本实验选取上证综合指数( 000、001)股票作为实验数据。从wind数据库中获取1991年7月1日至2020年6月30日共7083个交易日的日交易数据。每条数据包含8项:开盘价、最高价、最低价、收盘价、成交量、成交量、涨跌幅、变化幅度。部分数据如表1所示。本实验将前6083个交易日的数据作为训练集,后1000个交易日的数据作为测试集。
这里的开盘价是一个交易日(在证券交易所开业后)的首个成交股价。最高价是指一只股票从开盘到收盘的每个交易日的最高价。最低价是指某只股票从开盘到收盘的每个交易日的最低价。收盘价是指股票当日最后一次交易前1分钟每笔交易的加权平均交易量价格。成交量是指当日交易的股票总数。成交金额是指当天交易的所有股票的总股数。涨跌是指股票价格的变化量。变化是指当前交易日收盘价与前一交易日收盘价的值相比发生的变化;这个值一般用百分比表示。
4.2 模型
实现本实验CNN - Bi LSTM - AM模型的参数设置如表2所示。在本实验中,所有方法训练参数相同,历元为100,损失函数为MAE,优化器选择Adam,批大小为64,时间步长为5,学习率为0.001。这样做是为了提高方法的预测精度。
未来的研究工作将主要对模型中的参数进行调整,使结果更加准确。未来的研究工作还将研究该模型能否应用于更多的时间序列预测应用领域,如黄金价格预测、石油价格预测、天气预报、地震预测等。














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









