






前言:
想要了解transformers.js ,我建议可以先去看一下这个视频:
来自
transformers.js的作者的技术分享视频:Transformers.js:Web 上的最新机器学习技术
以下内容是我看过视频之后,简单的总结:
transformers.js 是什么?
在我的理解中,我觉得其实 transformers.js 就是一个帮助我们在js中运行高级AI模型的库。简单来说,这个库让我们在前端应用里使用chat GPT这些预训练好的AI 模型,不用依赖后端服务。
它帮我们简化了很多复杂的细节,比如模型的加载和运行。这样也可以不用了解AI模型的内部机制,就可以通过几行低代码时间自然语言处理任务,比如文本生成、情感分析、问答等。
transformers.js 工作原理
“transformers.js ” 的核心原理是让 js能在浏览器或 Node.js 环境中加载和运行 Hugging Face 上的模型,这些模型通常用 PyTorch、TensorFlow 或 JAX 等框架训练过。为了在 js中使用,模型首先需要被转换为 ONNX格式,这种格式更适合高效推理和跨平台兼容。
用户有两种使用方式:
-
转换模型:如果有自定义模型,用户可以用 Hugging Face 的 Optimum 工具库,把这些用 PyTorch、TensorFlow 或 JAX 训练的模型转换成 ONNX 格式。这一步完成后,模型就能在前端用
transformers.js来加载和推理了。 -
直接使用 Hugging Face 预转换模型:对于那些已经转换为 ONNX 格式的模型,可以直接加载使用。
transformers.js与 Hugging Face 的 Hub 相连,用户无需手动转换就可以使用预先配置好的模型,适合快速开发。
这样,transformers.js 把原本只能在后端使用的 AI 模型引入到了前端,既降低了难度,也带来了便利。
transformers.js 实际应用:
————语音转文本
简单的做一个语音转文本:
新建一个文件夹:
在这个文件夹下放一个.html文件,再放一个测试用的音频文件
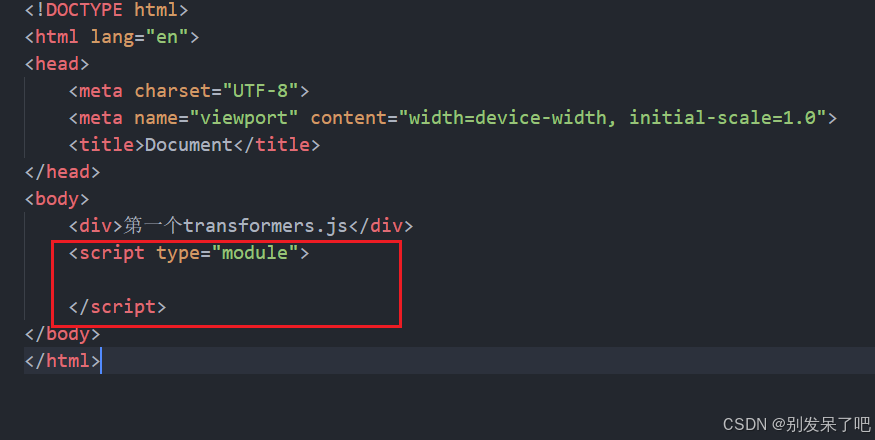
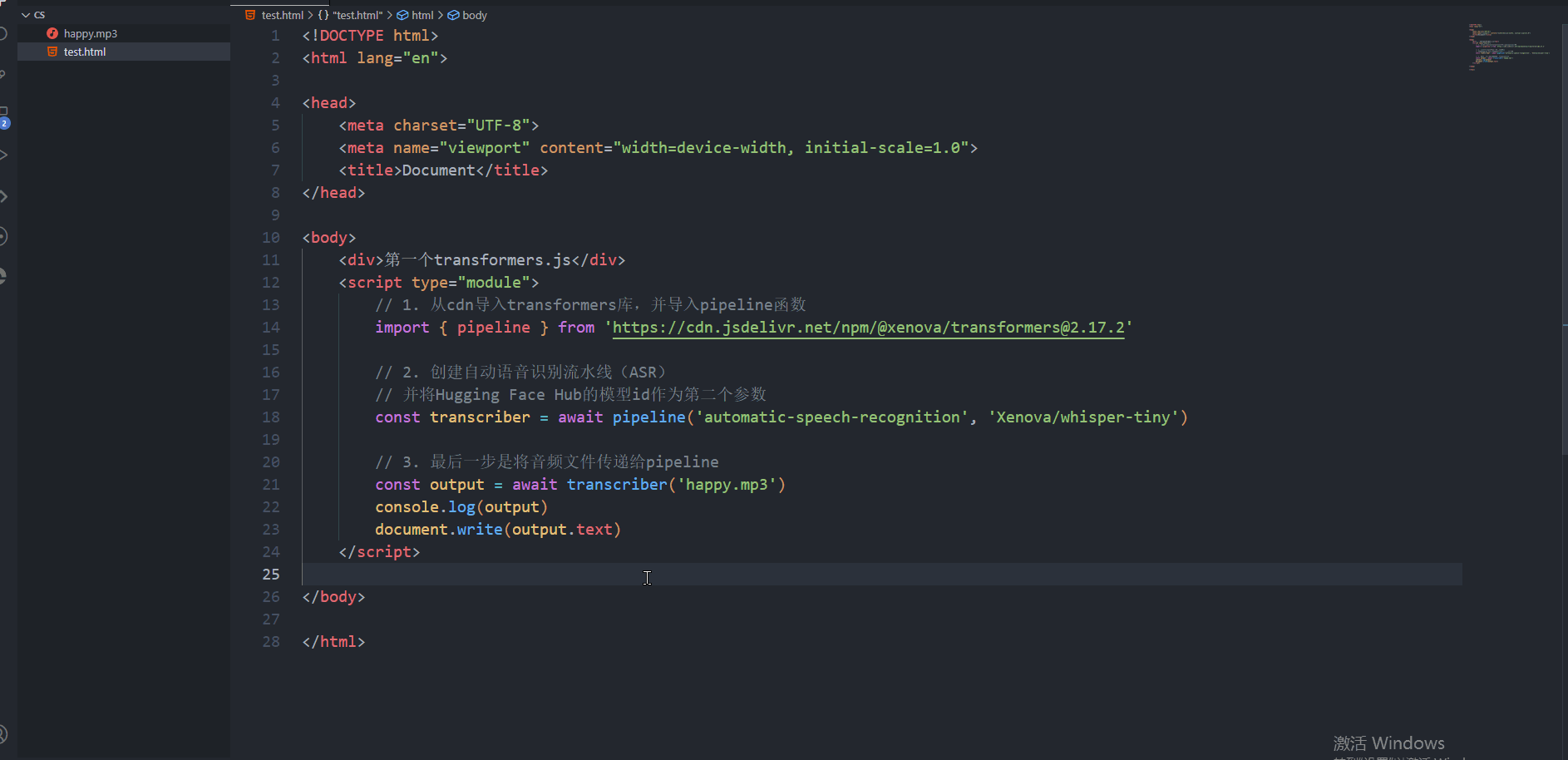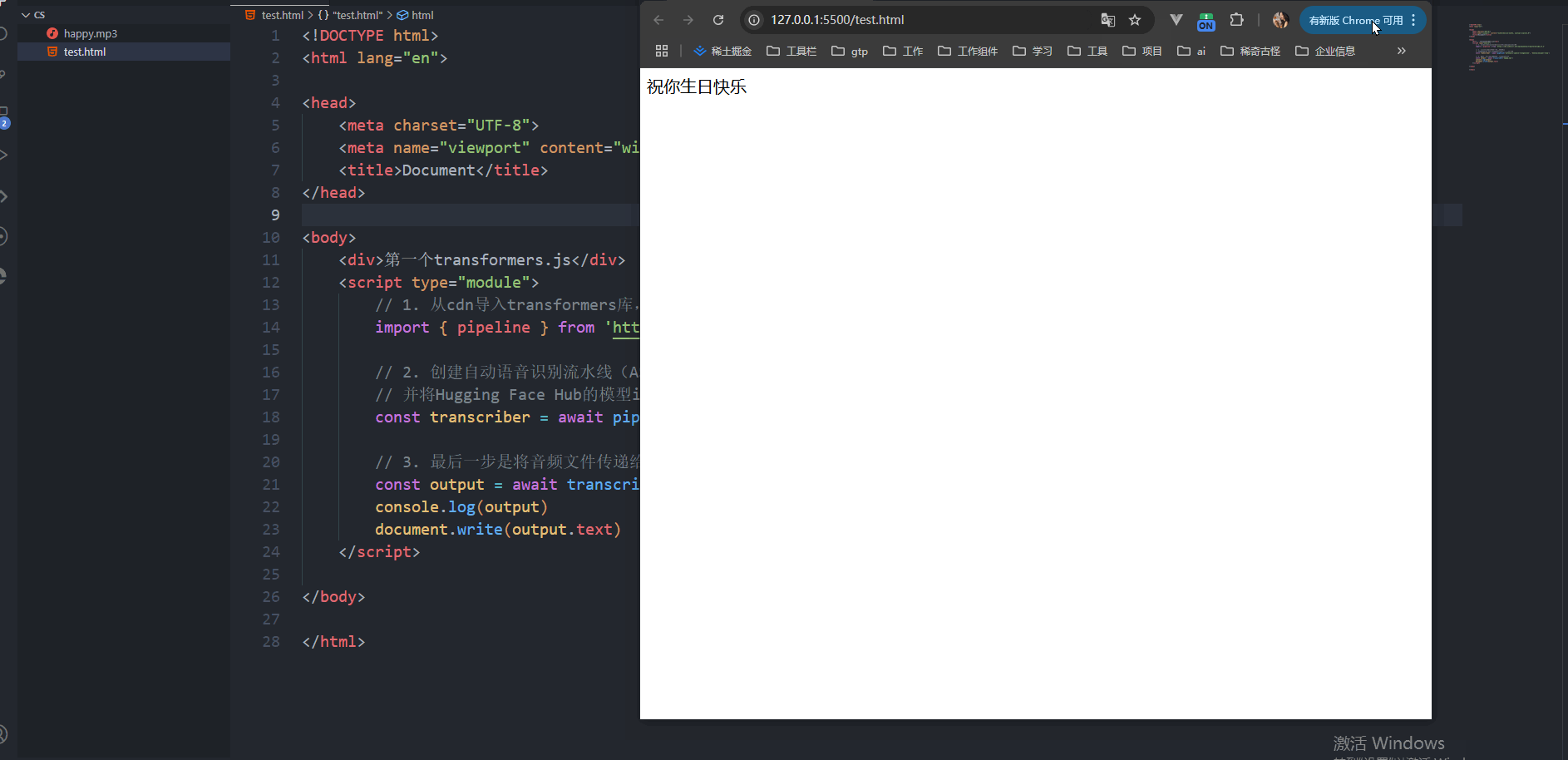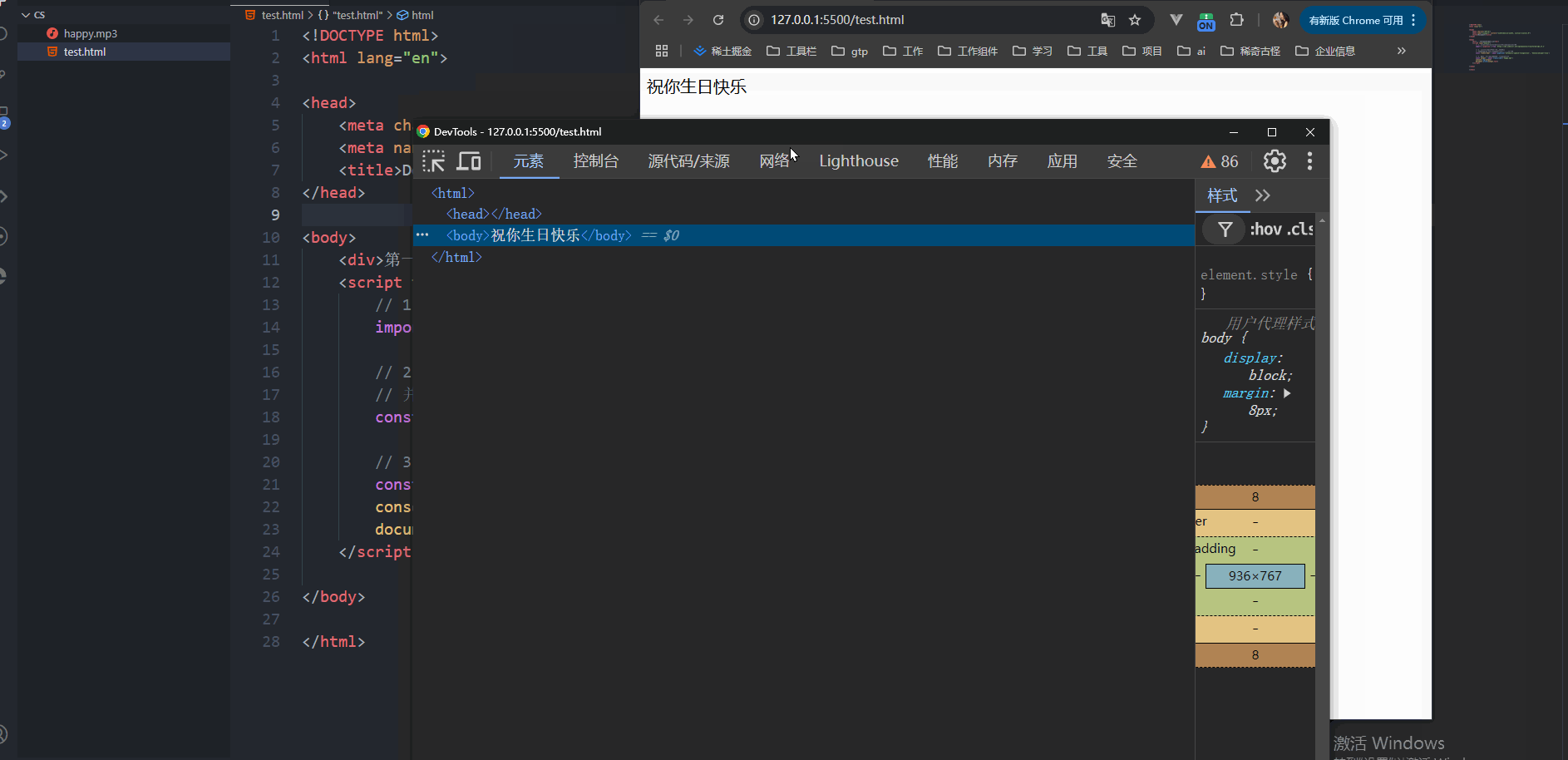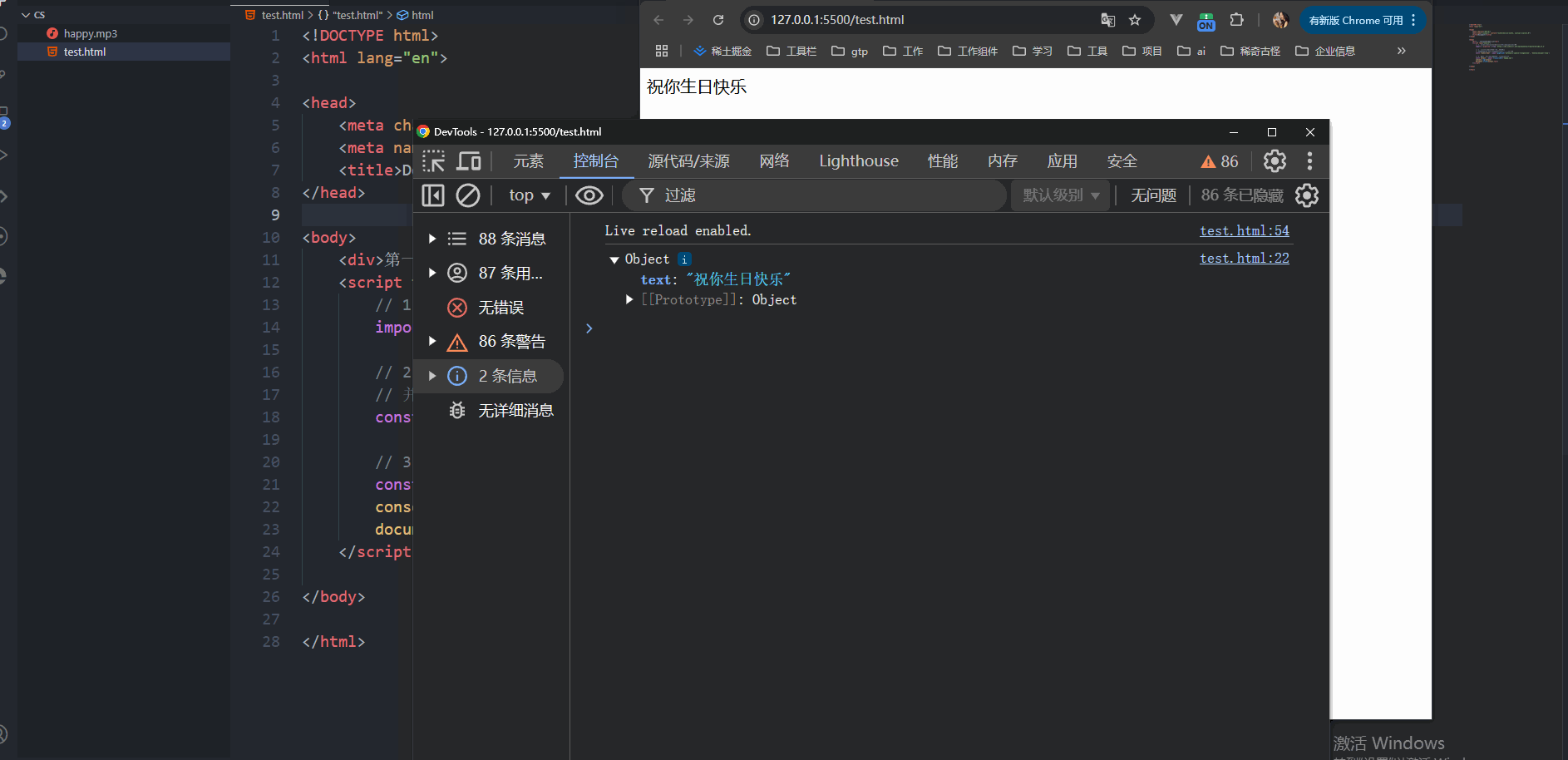
接下来在.html文件中 首先生成html的页面模版

然后在body中创建script标签 同时不要忘记在标签内加入type="module"
现在就正式进入对于transformers.js使用的步骤了:
1. 从cdn导入transformers库,并导入pipeline函数
参考网站:@xenova/transformers - npm
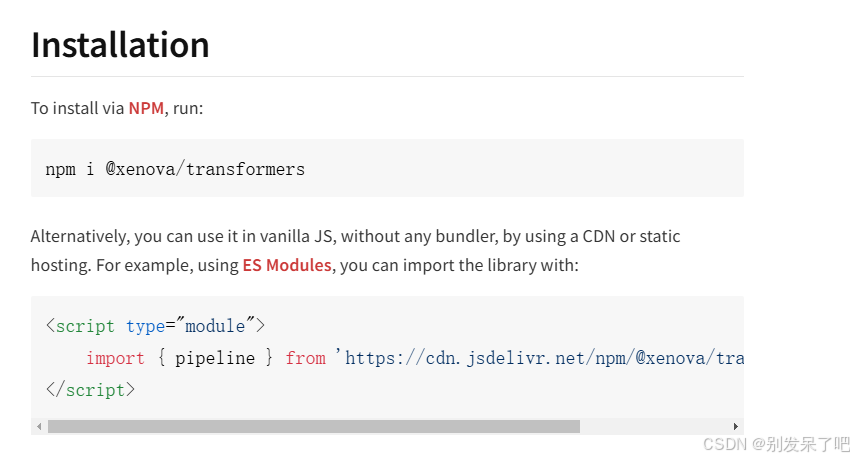

import { pipeline } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.2'2. 创建自动语音识别流水线(ASR) 并将Hugging Face Hub的模型id作为第二个参数
transformers.js官网(中文)网站:https://hugging-face.cn/docs/transformers.js/index

由于我们这儿的功能是自动语音识别,所以我们所实现的任务的音频,同时很清楚我们需要的是自动语音识别 所以将automatic-speech-recognition作为我们的第一个参数,
同时我们将Hugging Face Hub的模型id作为第二个参数
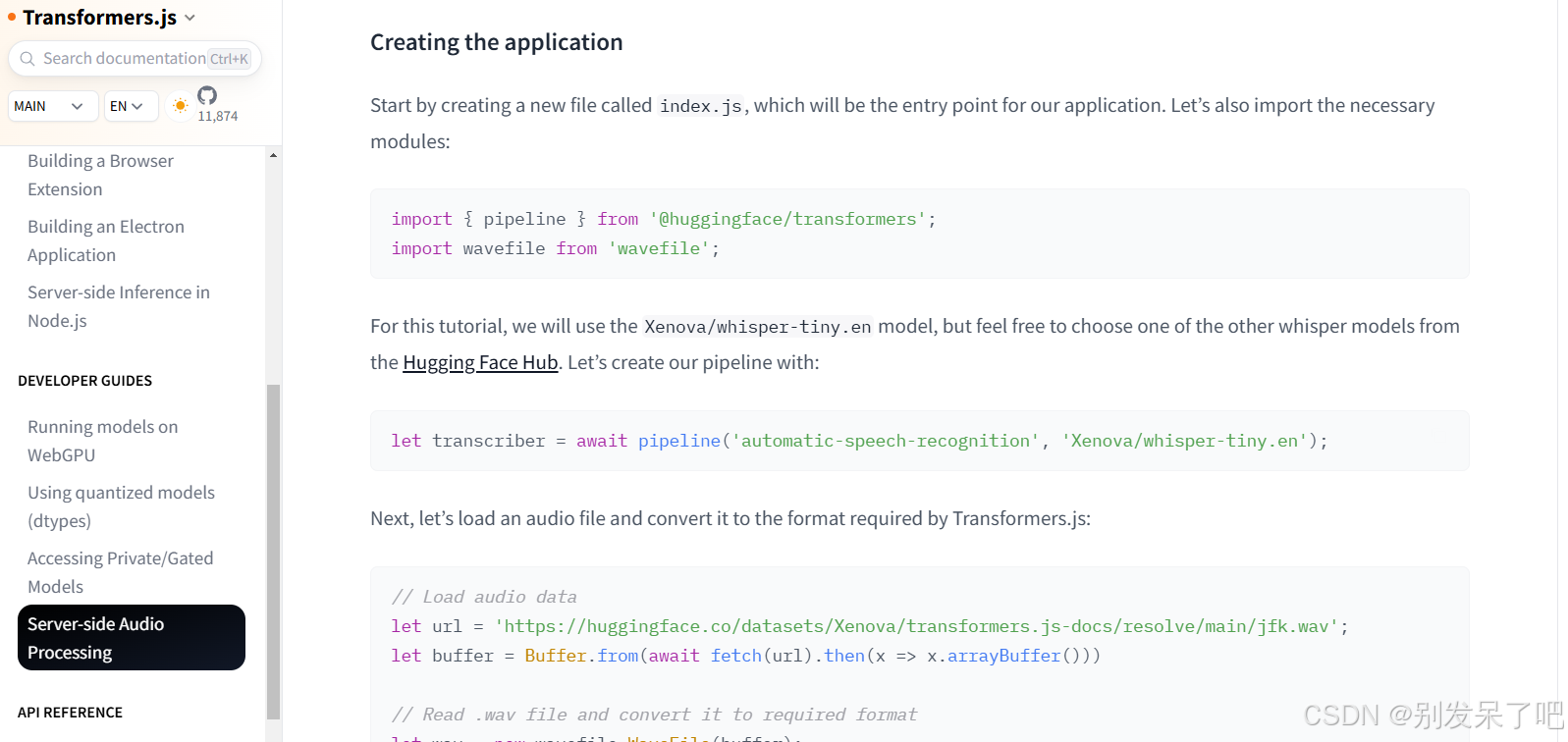

const transcriber = await pipeline('automatic-speech-recognition', 'Xenova/whisper-tiny')3. 最后一步是将音频文件传递给pipeline

这样就可以了
完整代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div>第一个transformers.js</div>
<script type="module">
// 1. 从cdn导入transformers库,并导入pipeline函数
import { pipeline } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.2'
// 2. 创建自动语音识别流水线(ASR)
// 并将Hugging Face Hub的模型id作为第二个参数
const transcriber = await pipeline('automatic-speech-recognition', 'Xenova/whisper-tiny')
// 3. 最后一步是将音频文件传递给pipeline
const output = await transcriber('happy.mp3')
console.log(output)
document.write(output.text)
</script>
</body>
</html>就这样ok。
昨天是我一个特别好朋友的生日,恰巧我找的音频是一句生日快乐,可是他并没有告诉我昨天是他生日。可能我算不上吧,人与人真的好难相处呀。


















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









