






目录
Review: Self-supervised Learning for Text
Self-supervised Learning for Speech
Self-supervised Learning for Image
在影像、语音上如何训练Self-supervised Learning的model:
方法五:Simply Extra Regularization
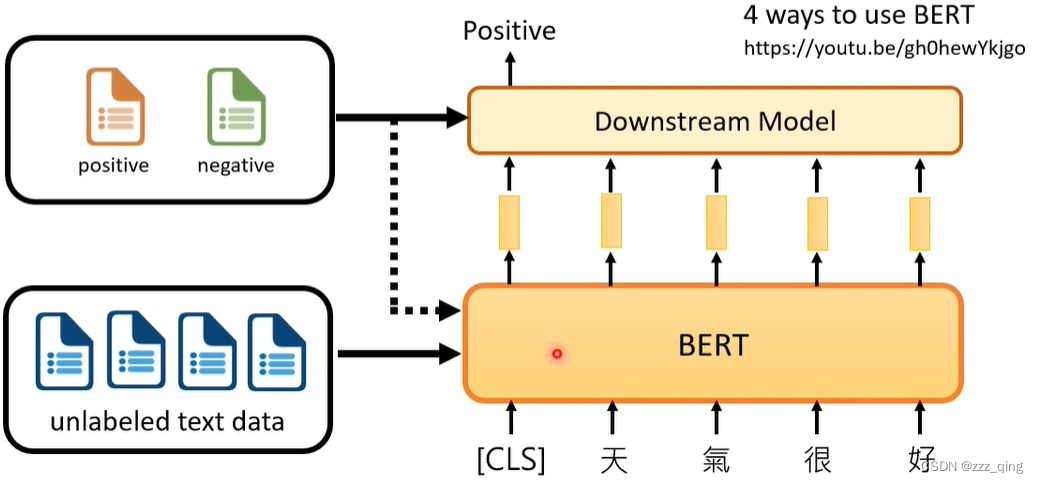
Review: Self-supervised Learning for Text
Self-supervised Learning for Speech
语音版的BERT和文字版的BERT在框架上并没有大的差别
在语音领域,Self-supervised Learning也用于各式各样的的任务上,并且效果很好
在没有大量标注的语音资料的时候,语音版的BERT可以给我们带来很大帮助:
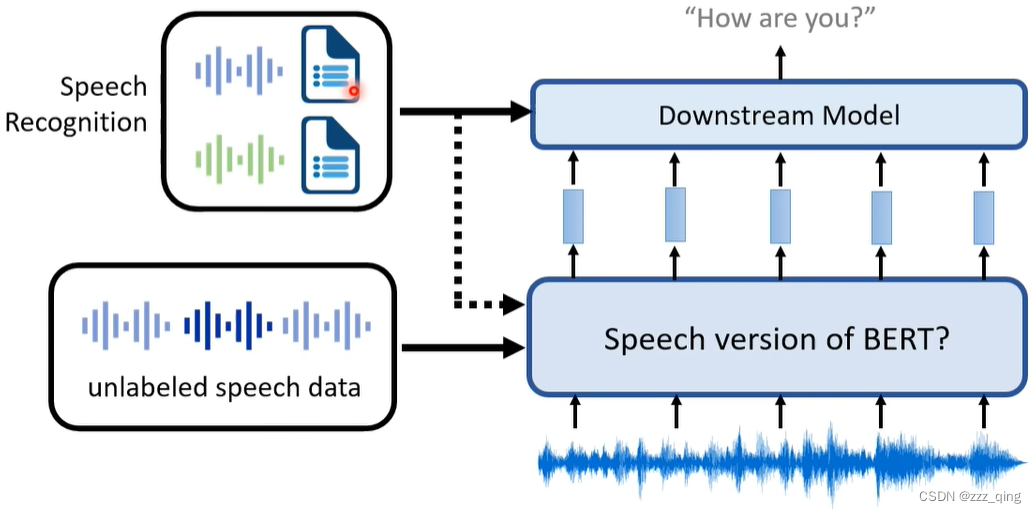
文献表明,用Downstream Task的资料去Fine-tune语音版的BERT是没有必要的
Self-supervised Learning for Image
与在文字、语音上一样,Self-supervised Learning在影像上也是非常有潜力的
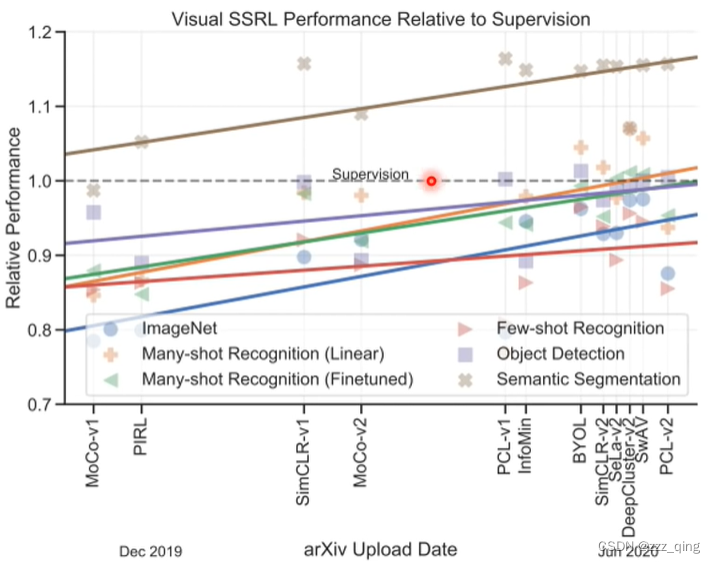
在影像、语音上如何训练Self-supervised Learning的model:
下面介绍五大类方法
方法一:Generative Approaches
语音上和文字版BERT的做法一样,mask一些token,再去还原被盖起来的部分:
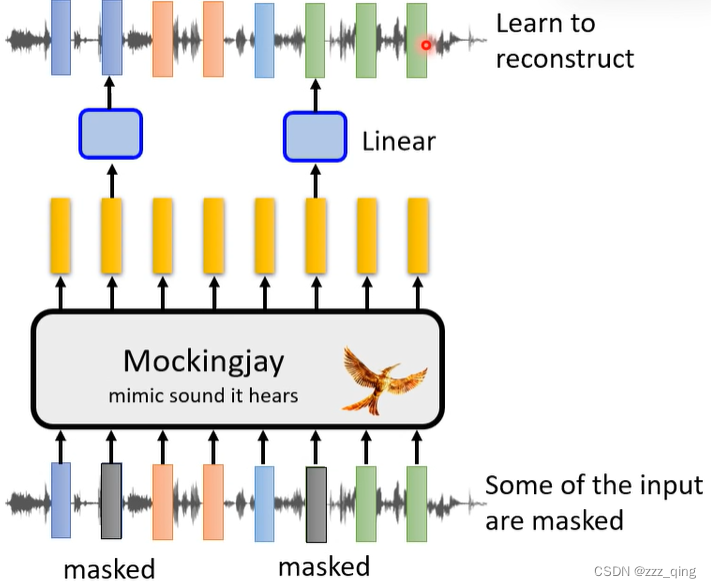
相比文字版BERT,语音上也需要进行一些对应的改进:
由于语音上每个feature和他相邻的两个feature之间内容十分接近,一次只mask掉一个feature的话,很容易根据相邻的两个feature猜出这个feature的内容,这样model就学不到什么东西。所以需要一次性mask掉一串feature

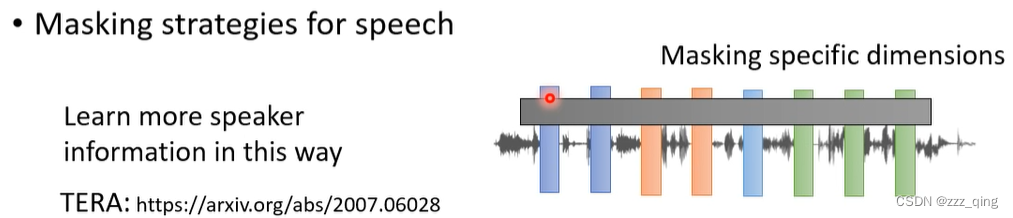
另外一个与文字不同的地方是,在语音上可以不在时间方向上做mask,可以mask一串向量的某几个dimension,这种mask的方法会让机器比较容易学到语者的资讯:
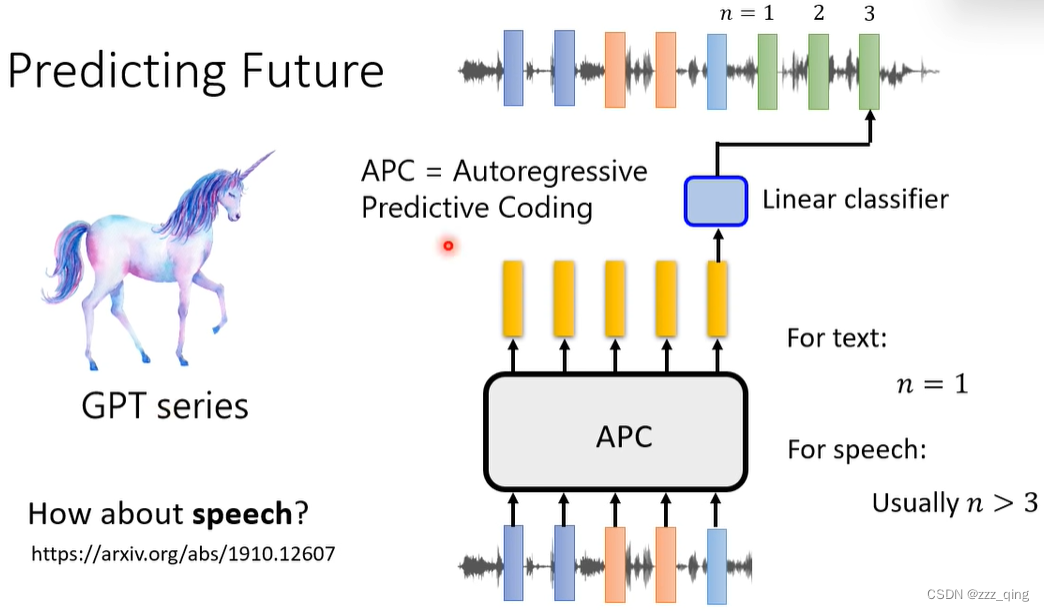
GPT系列完全可以用在语音上。对于文字版的GPT,要做的任务是给一段文字,预测下一个token。但是对于语音版的GPT,由于每个feature和他相邻的feature十分接近,所以预测下一个token没什么挑战,通常是预测往后数三个token之后的token:
BERT、GPT的概念也完全可以用在影像上:
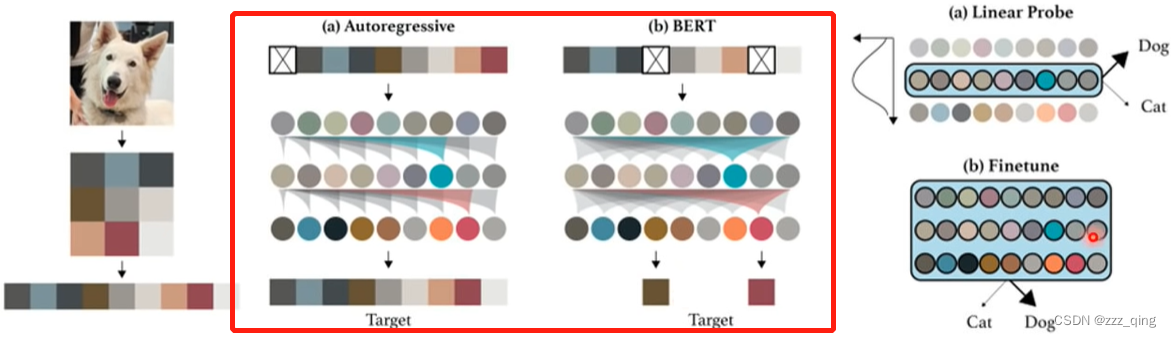
把在文字上generative的方法应用在语音和影像上,相较于应用在文字上有一个较大的问题是,文字是用token表示的,而语音和影像包含了非常多的细节。
方法二:Predictive Approach
除了让machine去还原声音讯号、还原影像之外,可以设计一些简单的任务让机器去完成,希望机器通过学会这些简单的任务,能在复杂的任务上做的更好。例如下面的任务:
Image - predicting rotation
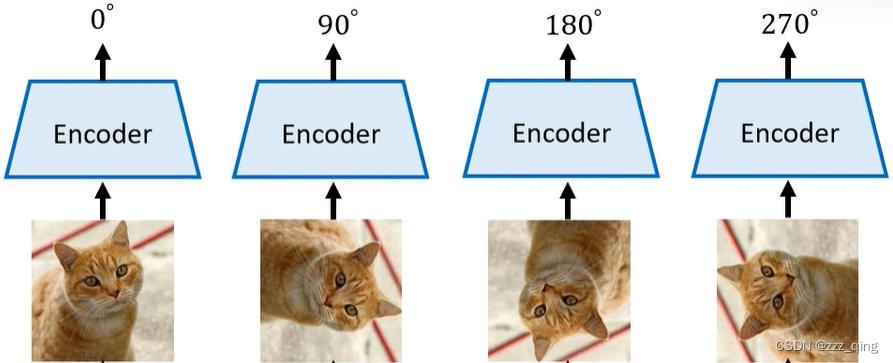
Image - context prediction(判断两块image的相对位置)

在语音、图像上,原来要生成的东西很复杂,因为语音、图像包含非常多的资讯。所以这里可以简化下要预测的东西:
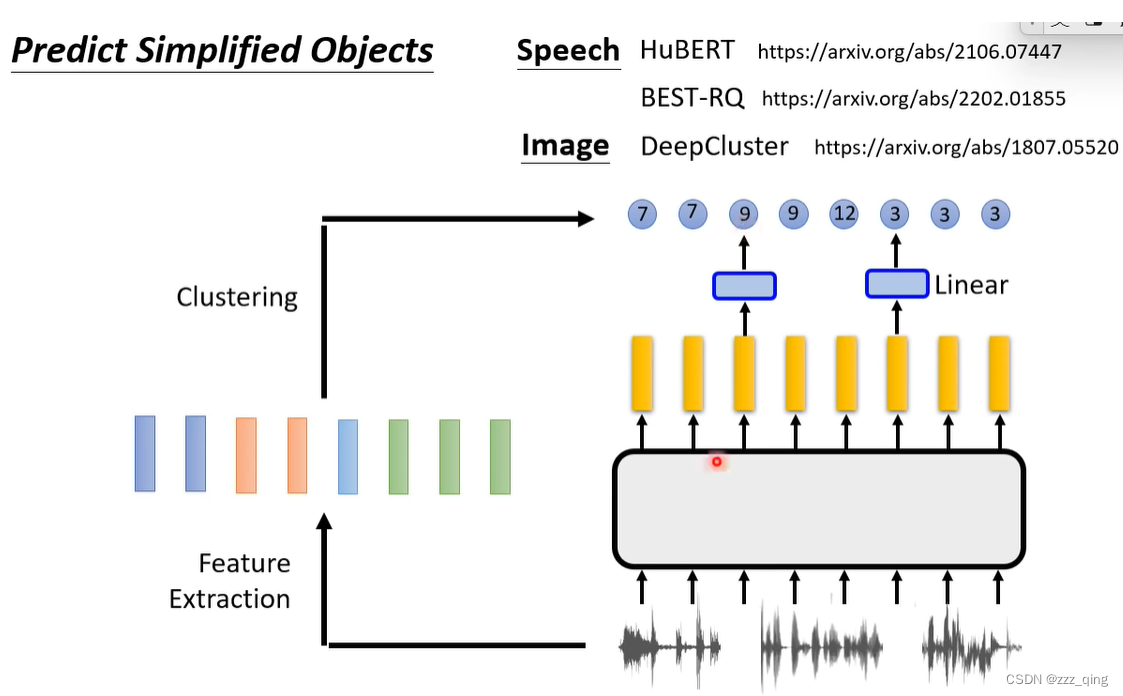
方法三:Contrastive Learning
Speech and images contain many details that are difficult to generate
Can a model learn without generation?——Contrastive Learning
Basic ldea of Contrastive Learning:
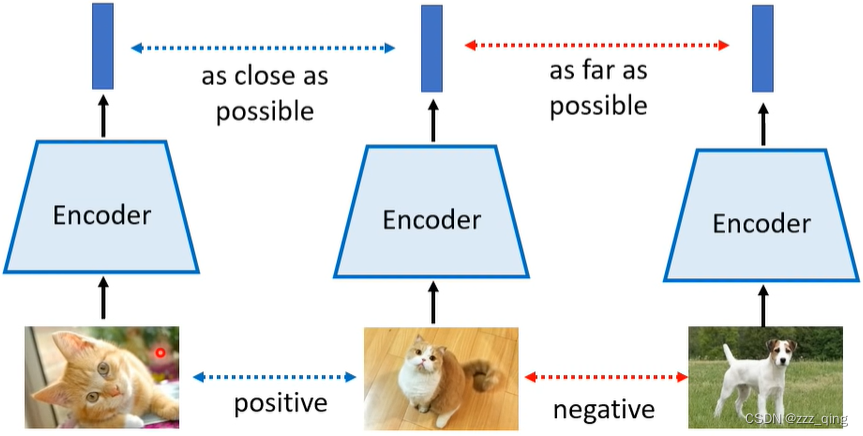
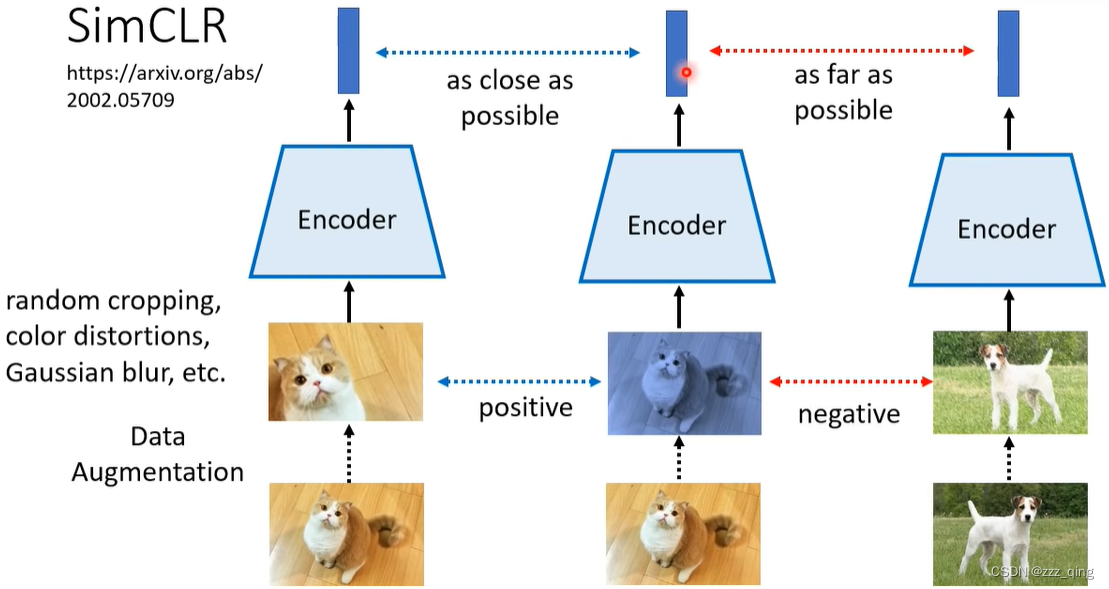
这里会有个问题,就是用于训练Self-supervised Learning model的data是没有标签的,如何判断两张图片之间是positive还是negative的关系?——SimCLR
对图片进行data augmentation,同一张图片augmentation出来的图片之间是positive的关系,不同图片augmentation出来的图片之间是negative的关系:
Contrastive Learning for Speech:
CPC / Wav2vec:
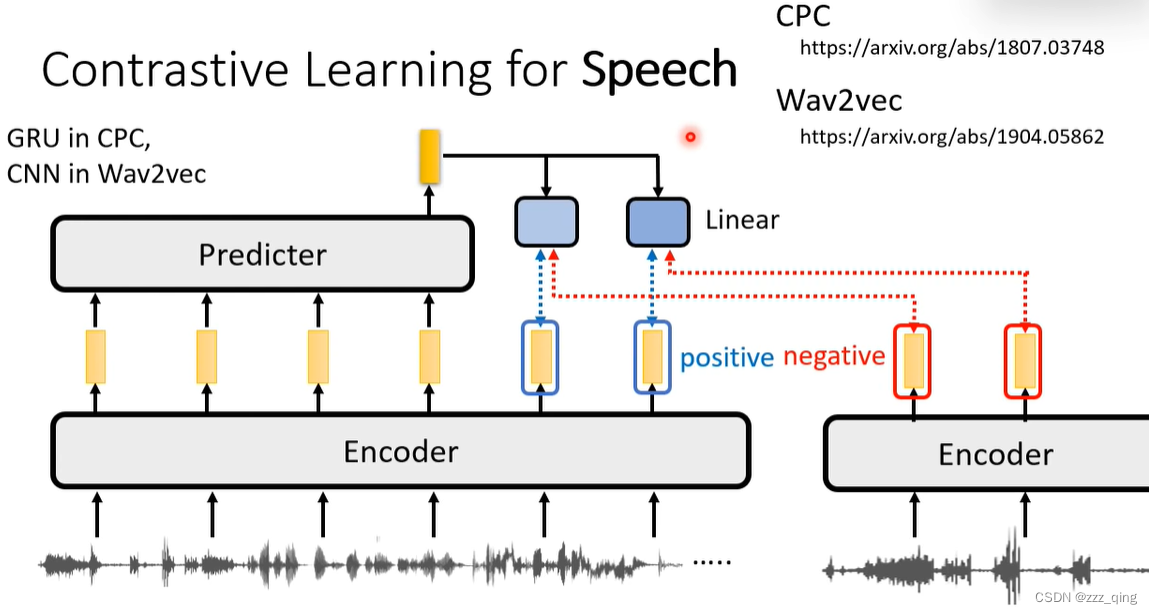
VQ-wav2vec:
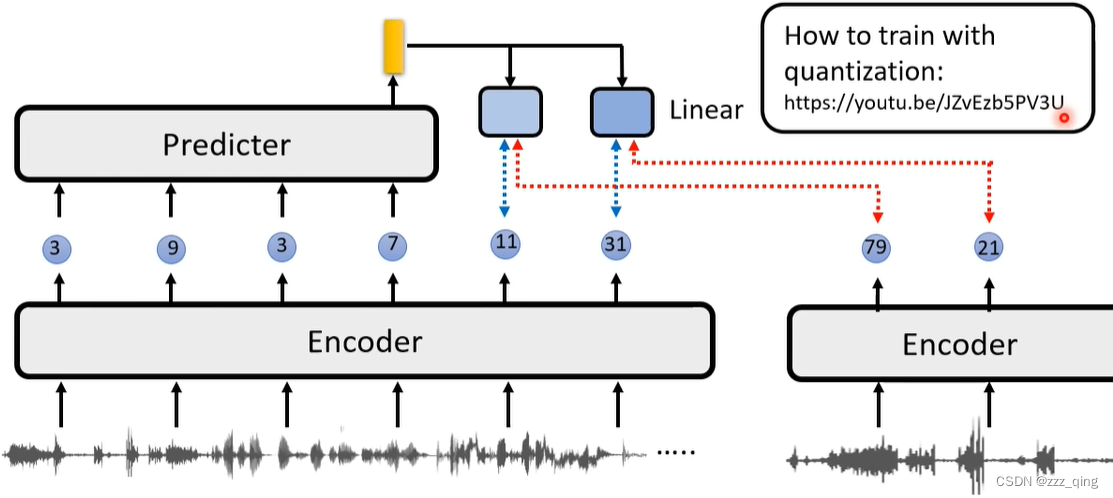
VQ-wav2vec + BERT:
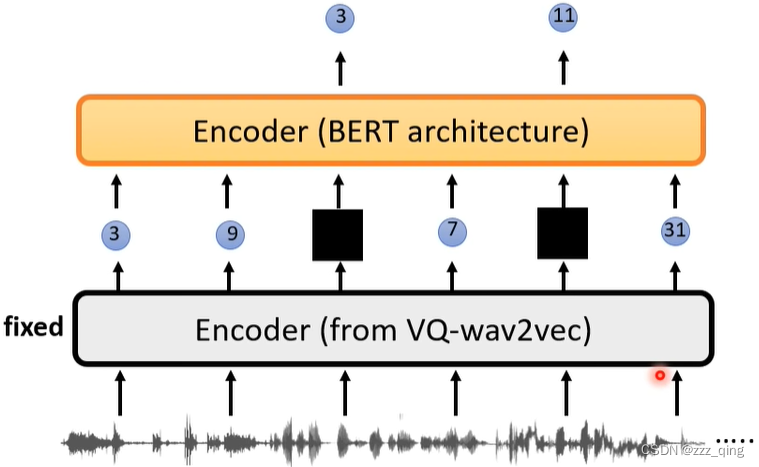
VQ-wav2vec 2.0:
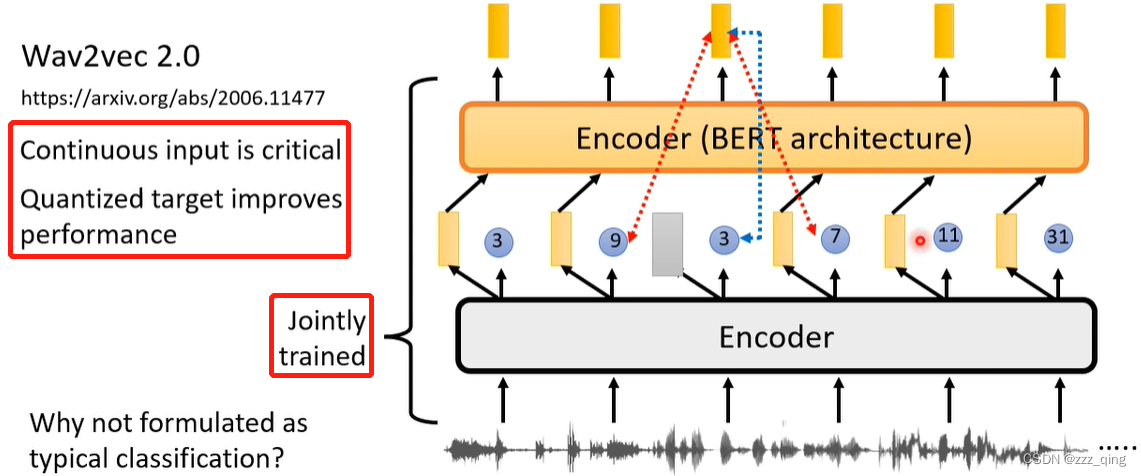
Classification vs. Contrastive
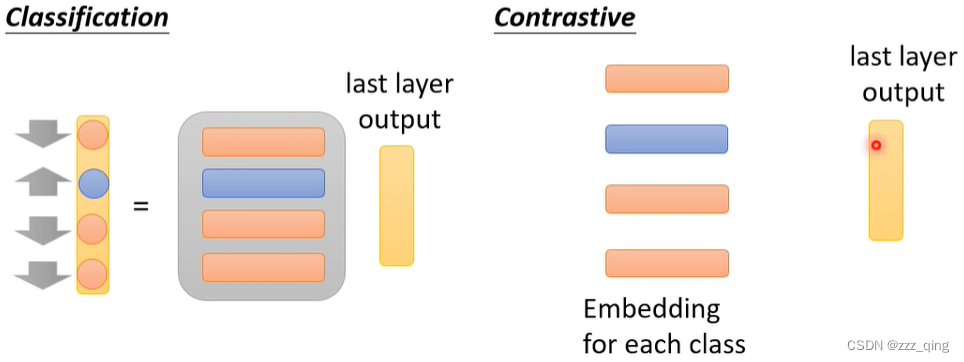
Contrastive Learning的方法,存在一个很大的问题就是需要选择合适的negative examples:

既然选择negative example是一个比较困难的问题,下面方法四和方法五就避开选择negative example。
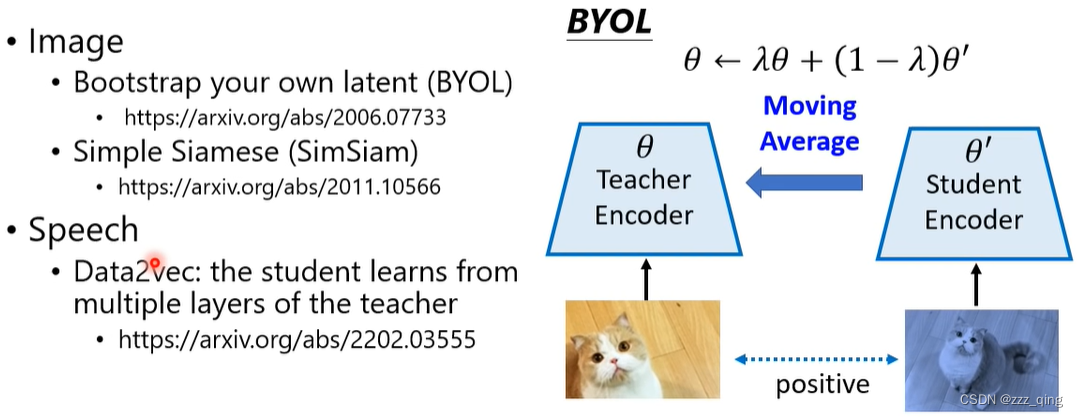
方法四:Bootstrapping Approaches
如果只用positive example去训练模型,无论输入是什么,machine只需要输出相同的向量就行,就会出现collapse的现象:
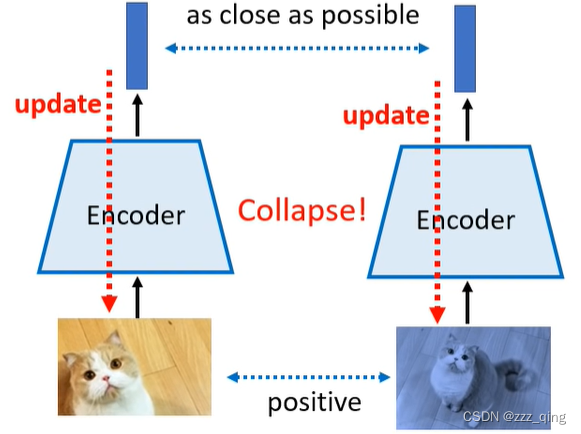
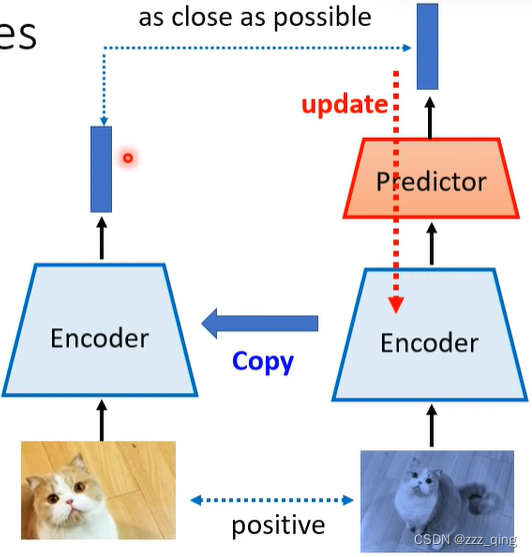
只用positive example的情况下,避免collapse发生:
关键技巧:左右两条路径的network架构不同、参数update的方式不同(左边不进行update,右边update后把Encoder的参数copy给左边的Encoder)
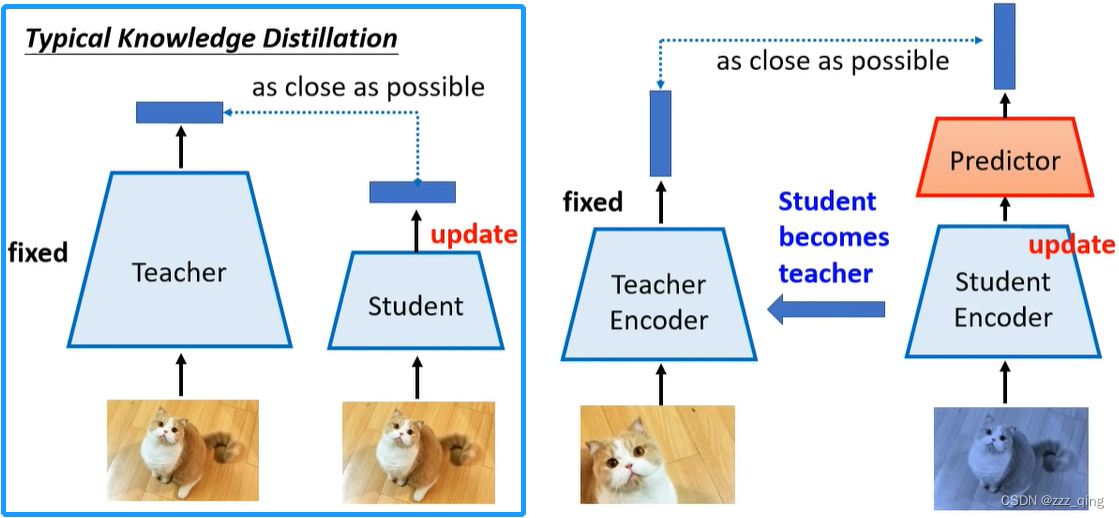
Bootstrapping也可以看做一种Knowledge Distillation:
下面是一些在图像和语音上使用Bootstrapping的model:
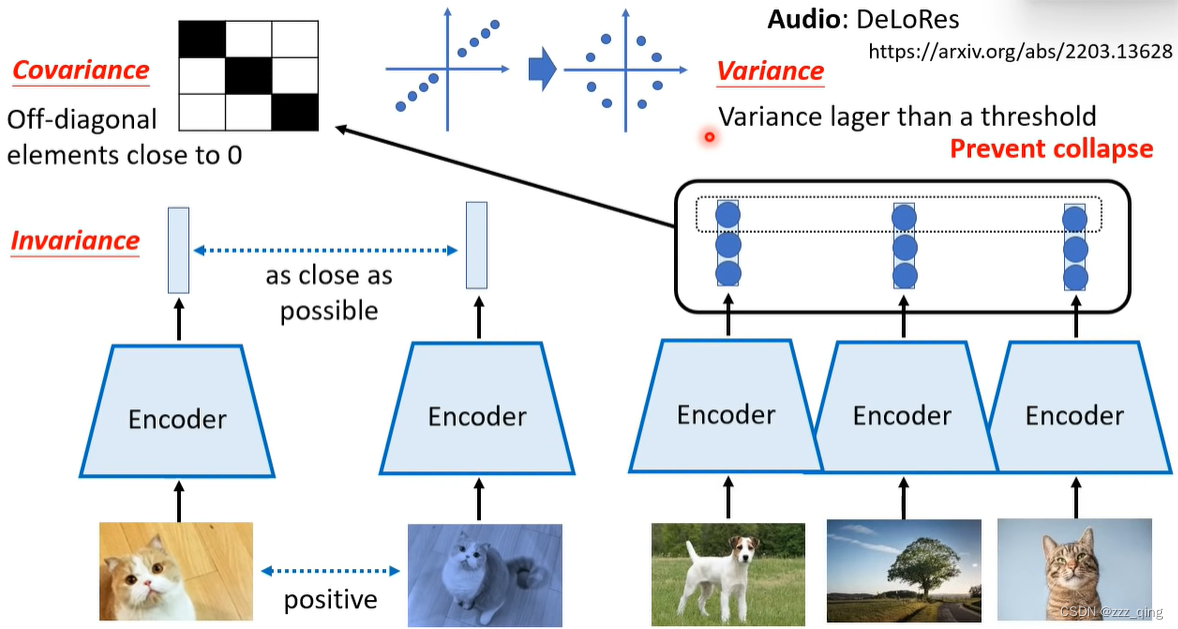
方法五:Simply Extra Regularization
——positive example + regularization
方法五有两个代表作品:
① Barlow Twins
② Variance-Invariance-Covariance Regularization (VICReg)
下面介绍VICReg:只需要Invariance和Variance,就不会出现collapse的问题
Concluding Remarks
















 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









