







一、背景介绍
VO、RVO、ORCA都是为了解决路径规划中的避障问题而研究的算法,它们三个的关系就是走进江湖的剑客,行走江湖逐渐改正自己,完善自己成为顶尖剑客。
而这三种算法是一种局部导航,它只能感知到靠近自身周围的情况,而没有全局环境的信息,只管导航时不与周围的个体目标或者障碍发生碰撞,在这一点与传统的寻路算法A星之间形成互补,A星是最大可能保证导航个体与自身起点到目标点之间的距离是最短路径,但A星没有感知所有导航个体的具体状态和周围其他agent的运动状态,因此它只能把所有物体都看做障碍物,这样就增加了地图的复杂程度,大大增加了寻路的时间。
下面就是我对这三种算法的一个理解
二、算法描述
VO:放弃所有可能相撞的速度和方向:
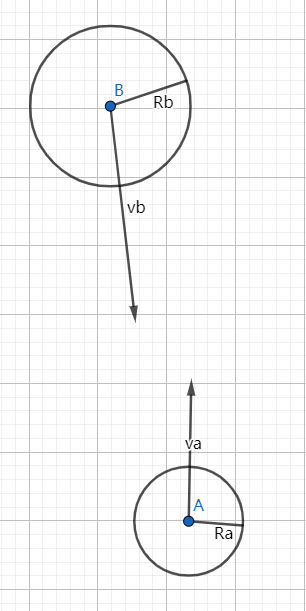
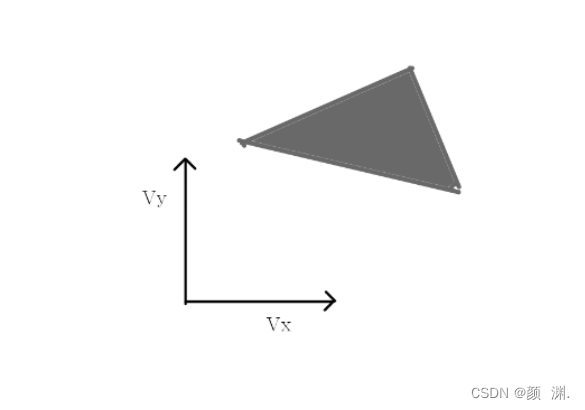
假设两个圆盘状物体A、B,它们的半径分别为Ra,Rb,如果两个物体不相撞,也就是说圆心A、B之间的距离要大于Ra+Rb,那也就可以等价于如下图所示:
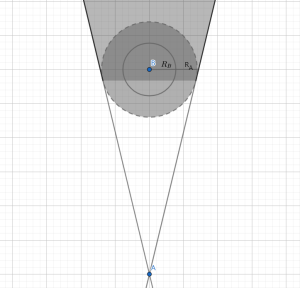
我们将A看成一个质点,也就是在这一帧的相对移动位于这个圆外就可以,并且因为运动是连续的,终点和起点之间是一条连线,所以圆的后方也是不能到达的,所以深色区域都是质点不能到达的。我们把上述图除以时间也就映射到速度域了(即为VO)。
但是,如图所示,A和B相向而行,一开始A和B会错开,但当下一帧对方的速度发生变化时,他们又会把速度转回来,因为A会认为B是就是往左上走的,所以我还是保持最佳的向下走也不会撞上,B也是这么想的,所以他们就转回来了。实际上他们可能不会碰撞,但两个agent的反复横跳是不够优雅的,并且在现实场景中,这种情况也是不可取的。
RVO:作为VO的改进,它解决了VO产生抖动的原因(反复横跳),
假设对方也会使用和我们相同的策略,而并非保持匀速运动。在基础的VO算法中产生抖动的原因是A在第二帧选择新速度之后,发现B的速度也变化了很多,A就会认为改回最佳速度(即直接指向目的地的速度)似乎也不会碰撞了,因为B的新速度其实就是根据A保持最佳速度也不会碰撞下的情况下改变的,所以A就会认为B允许他转回来,但同时B也是这么想的。
然而在 RVO 中,A 把自己的速度只改变 1/2,也就是说,我们假设 A 和 B 想要错开,总共需要错开 10cm,VO算法中A和B都会各自错开10cm,在RVO算法中A只错开一半,也就是5cm,同时A假设B会错开另外一半,B也是这么想的,因此两人不谋而合,第二帧的时候,两个人各自错开了一半,并且发现此时转回最佳速度依然是会碰撞的(因为每个人只转了一半),因此有效避免了上述抖动的现象。
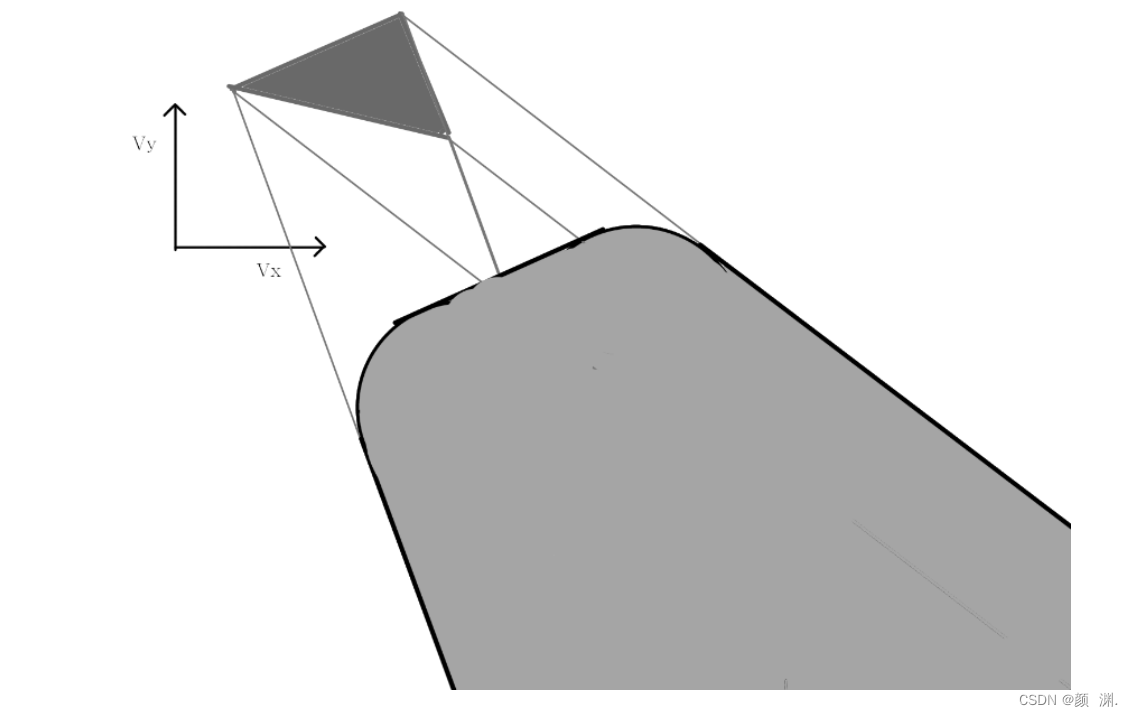
ORCA:作为究极进化体,(个人认为是最难理解的)它解决了上述两种算法只能应用在两个agent下,而当智能体数量增多,如下图所示:
A认为C会向右转,因此自己向左转了1/2,而B认为C会向左转,因此自己向右转了1/2,而C实际上两种做法都没有选择,因为在VO图中,两个锥体摆在自己的面前,所以C选择非常努力的向左或者向右转动。
在RVO中,所有智能体都假设对方只考虑自己。
ORCA与RVO最大的区别,在于VO的形状差异,在以往的VO算法中,VO都是以无限高度的锥形出现的,二维中就是同源的两条射线的夹角,但在ORCA中,我们使用一个有向平面来分割平面。
参考ORCA-有关机器人群碰撞避免算法解读 - 知乎 (zhihu.com)
这里我省略一些图片,跟我上面所描述的图也类似。
引入了VOτA|B的定义。VOτA|B(将A看成质点)是在二维速度空间坐标系中的一片区域,指在某一时刻A、B机器人位置已知的情况下,在下一刻A对于B的相对速度若属于以上定义的区域,则A、B机器人会在时间窗口τ内发生碰撞。相当于坐标系,A的速度是vAO,B的速度为vBO,而A对于B的相对速度是vAB,这里先假设B是静止不动的,vAB=vA.
当vAB∈VOτA|B时,A、B会在τ时间内发生碰撞。若vAB ∉ VOτA|B,则两机器人不会发生碰撞。
我们定义CAτA|B为本agent不与其他agent发生碰撞的速度集合。
CAτA|B(VB) = {v|v ∉ VOτA|B⊕VB}。
假设A、B在同一平面上。在二维速度空间坐标系,B这里开始有速度了,假设B的可选择的速度范围为下图深灰色区域。
然后假设VOτA|B为如下浅灰色区域:
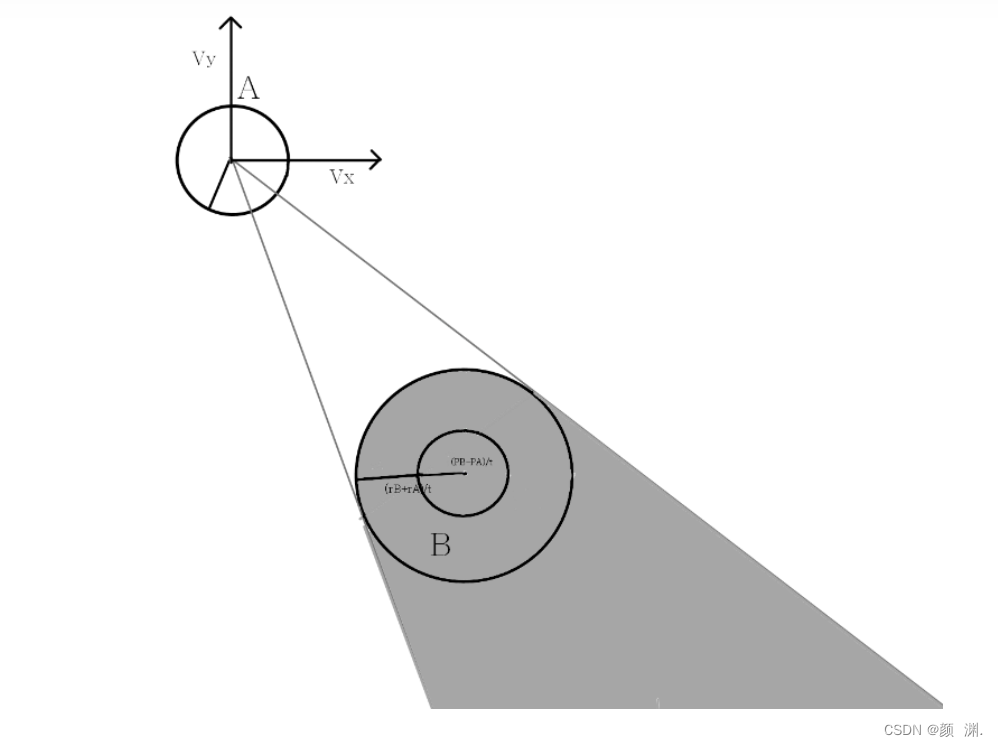
VOτA|B⊕VB为如下浅灰色阴影区域。相应的,由于CAτA|B(VB) = {v|v ∉ VOτA|B⊕VB},我们有CAτA|B(VB)为除去浅灰色阴影区域的其他区域。(感觉可以理解成A按照B的速度区域运动,然后得到的VO区域)
基于上面所说的,我们将对象引申到机器人,A机器人的速度为vAopt,B机器人速度为vBopt。先假定A、B会在τ时刻内发生碰撞,显然vAopt-vBopt属于速度障碍区域VOτA|B。
vAopt-vBopt∈VOτA|B。
现设向量u。u的起点为vAopt-vBopt。终点为到速度障碍区域VOτA|B边界最近的一点,u即为。
u = (v|arg min||v-(vAopt-vBopt)||)-(vAopt-vBopt),v∈∂VOτA|B。
由于vAopt和vAopt在速度障碍区VOτA|B的内部,A和B会在τ时间内发生碰撞。现在倘若我们让A和B在τ时间内不发生碰撞,那我们必须要改变VAopt或VBopt,或者两者都改变,来使vAopt-vBopt移动至速度障碍区VOτA|B之外。在之前的RVO规定中已经定义了A、B采取相同的计算方法避免碰撞,现在,我们把碰撞责任平均分摊给A、B两个机器人,即A的新速度为vAopt+1/2u,B的新速度为vBopt-1/2u,这样(vAopt+1/2u)-(vBopt-1/2u)已经不属于速度障碍区VOτA|B,也就是避免了碰撞。如图所示:
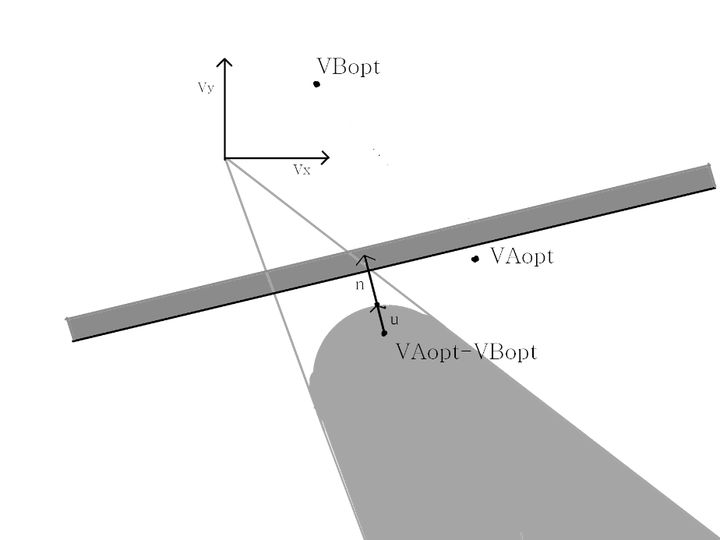
其中n向量为单位向量,它的起点是u向量的终点。由于ORCAτA|B={v|(v-(vAopt+1/2u))*n≧0},可得ORCAτA|B为一个半平面区域,其中,该半平面区域的边界距离点vAopt的距离为||1/2u||,且与向量n垂直。以同样的方法,我们可得ORCAτB|A。
以上就是我的个人理解,写这篇的目的也主要是为了加强自己的理解,可能会存在错误或者偏差,欢迎人批评指正,互相学习!

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









