







第七章 过拟合(over-fitting)
这一章主要就是处理过拟合问题。
首先介绍如何选择参数:
- 选择尽可能少的特征
- 自动选择模型(这是啥?)
正则化
正则化就是给每个参数以系数λ,这个λ可以在参数值较小和与数据拟合中间取得一个平衡,具体公式如下:
之后介绍带正规化的梯度下降和正规方程
梯度下降:
正规方程:
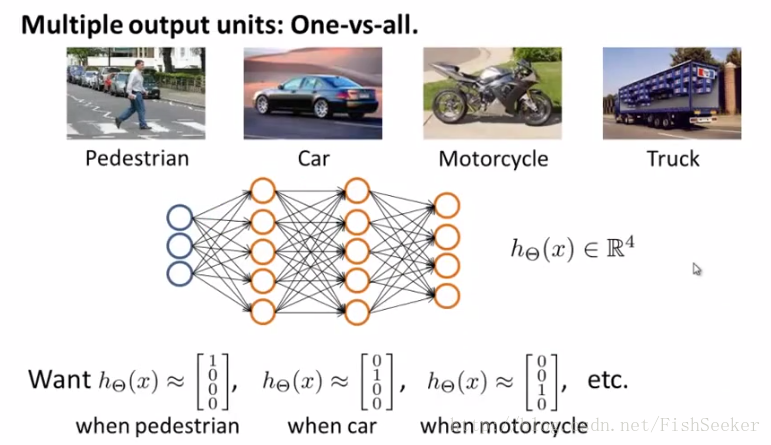
最后讲了如何多分类问题,就是采用one-vs-all的方法,比如想分三个类,先分出一个类和其他两个类的区别,做三次就可以分出来三类了。
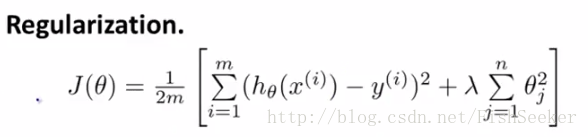


第八章 神经网络1
先上来是简单的BP神经网络:

然后多个分类即最后一层是多个:
第九章 神经网络2
上一节概要介绍BP神经网络的结构,这节讲其cost function的实现

想要求得最优,就要求知道关于Θ的偏导数。这里就引入了误差项δ,这个δ是从最后一层往前计算的,具体如下:

通过误差项获得关于Θ的偏导数:

误差项的意思其实是修改Θ的值,对于最后cost function造成的影响。
之后是检查梯度,使用数学上的方法:

让这里计算出来的梯度值和上面的梯度值大致相等,就说明计算对了。
然后讲到随机化初始化权重,就是用random函数在一个较小的区间内随机生成即可。
最后给出了一个自动驾驶的例子,挺有意思的。
第十章 选择模型方法
如何调整模型有六种思路:
- 更多数据
- 增加/减少特征数量
- 上升/下降λ的值
不同的特征结合(x2之类的)
评估假设函数使用的是将样本分为训练集,交叉检验集和测试集。这三个集的作用分别是确定各个模型Θ的值,选择合适的模型和检测模型与实际数据的拟合度:
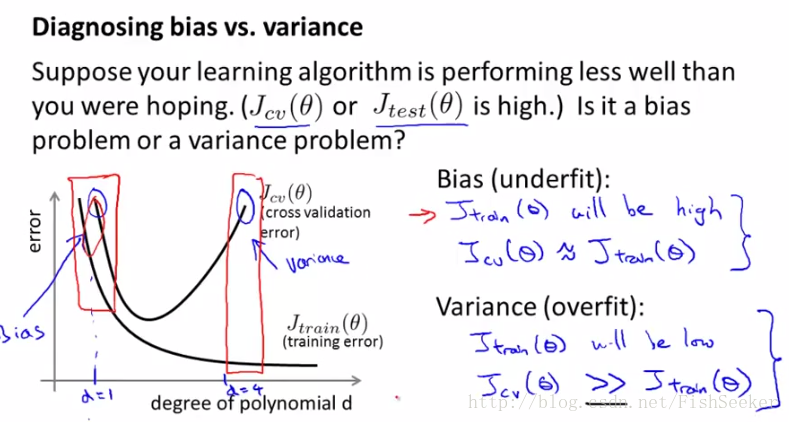
然后小妙招(= =)教你识别过拟合和欠拟合。
底下的d就是你的假设函数的最高次。
以及和λ的关系:
右边是欠拟合左边是过拟合。
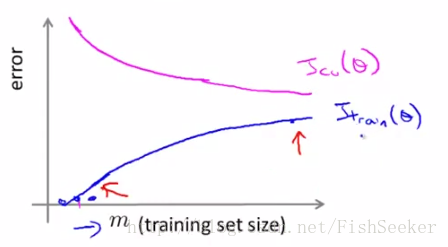
最后是很重要的学习曲线(learning curves)
正常情况下的学习曲线:
这个通过增加数据量可以使拟合效果变好。欠拟合:
过拟合:
由上边的例子我们可以看出,当模型欠拟合的时候,增加数据量是没有用的。
最后介绍了这六种完善模型的思路都在什么情况下适用:

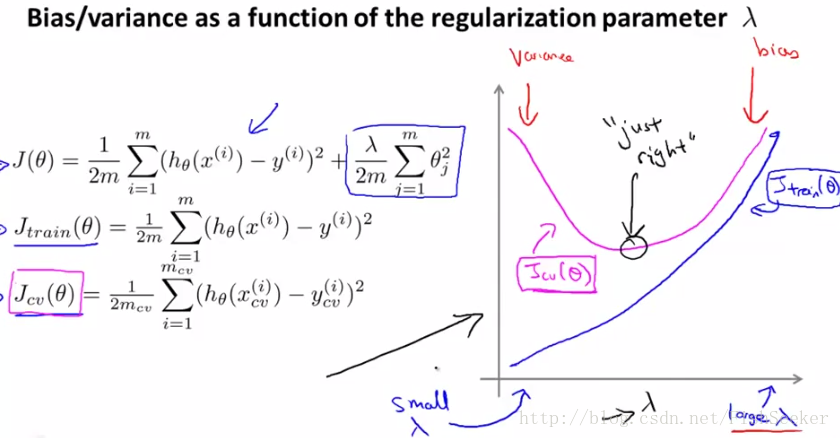
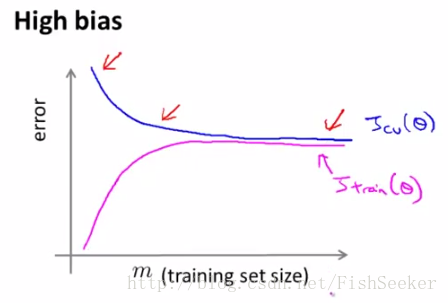
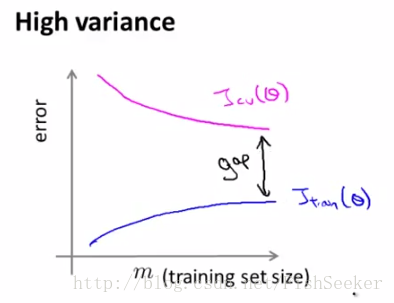

这里high variance(高方差)就是过拟合,high bias(高偏差)就是欠拟合。
第十一章 机器学习系统设计
误差分析(error analysis):简单说来就是分析那些你的算法弄错的样本,看看能不能找到一些以前木有发现的特征之类的事。然后举了个分析辣鸡邮件的例子;或者,你有一种数值分析方法来分析你的模型的预测的准确度之类的事。
之后介绍的一种,当正样本极少的情况下的评价算法准确性的方法,也叫偏斜类(skewed classes),具体方法如下:
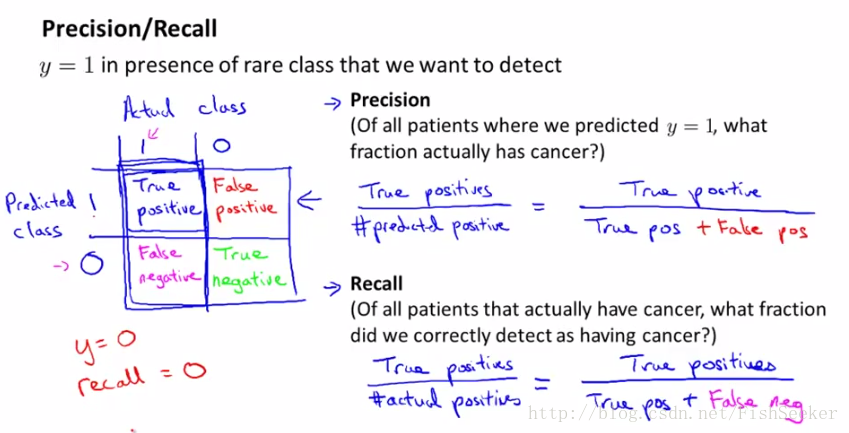
有了查准率(precision)和召回率(recall)该怎么使用呢,本来不太理解,后来发现这不就是和以前信息检索里的查准率和查全率就是一个意思。precision就是你预测出来一堆有病的人,这里面真有病的概率,就是你预测的准确率;recall就是本来有这么多有病的人,你一共找出来多少。它们俩有一定的负相关关系。举两个极限一点的例子,第一个,你就找一个人,这个人有病,你也预测他有病,那么你的precision就是100%,但是你的recall就会很低很低;相反,你把所有的人都认为是有病,那么你的recall就是100%因为一共就这么多病人,你全找出来了,但是你的precision就会低得要死。这里结合假设函数来分析:

这里当h(x)>0.9时,即当我们很确定的时候才说明这个人有病,那么precision就会很高,但是由于这样找出来的人肯定很少,那么recall就很低,同理当h(x)>0.3这种比较小的数值的时候就会相反。所以,我们应该如何控制precision和recall呢,通过下面这个公式来判断:

通过这个你可以知道你不同的标准下你的precision和recall哪个比较高,你就可以选择合适的假设。
最后介绍了数据量大小和模型的关系:可以用一个具有大量参数的学习算法,来保证偏差较小,然后使用大量训练集来减少过拟合,从而达到训练出一个在测试集上误差较小,泛化能力强的模型。
第十二章 SVM
资瓷向量机(胡建人?)以前在DM课上学过一些,这里倒也是讲得通俗易懂(但是感觉为什么和课堂上讲的那些不太一样呢):
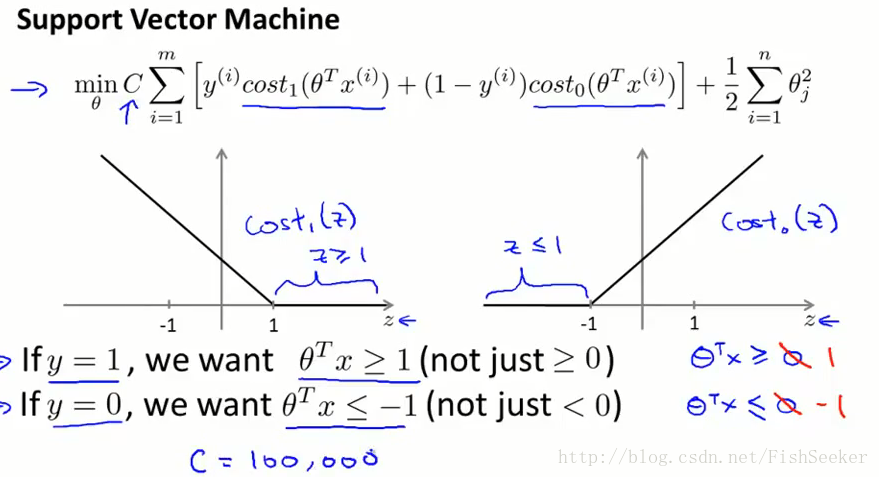
然后提出核函数的概念:

这里的f就是用来代替以前的x的,f的值就是:
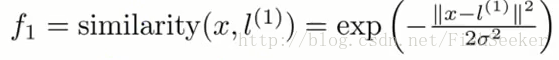
而l点的选取就是我们拥有的样本点。
这些θ是怎么训练出来的呢,就需要有cost function:
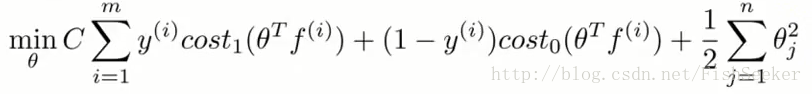
还有对于C(=1/λ)的选择:
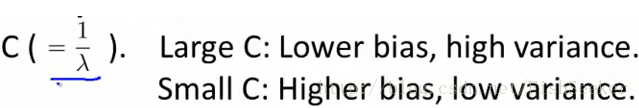
关于核函数的选择有一个Mercer定理:任何半正定的函数都可以作为核函数。
最后总结了一下什么时候用SVM什么时候用逻辑回归:当特征数量n(=10000)远大于数据的样本m(10-1000)的时候,选用逻辑回归;如果特种数量(10-1000)比较少,而样本数量(10-10000)又中等的时候,用SVM;当特征数量很少(10-1000)但是样本数(50000+)很多的时候应考虑增加特征数。














 1849
1849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









