









论文题目:Online Knowledge-Based Model for Big Data Topic Extraction
论文地址:https://www.hindawi.com/journals/cin/2016/6081804/abs/
论文大体内容:
本文对automatic must-links cannot-links(AMC)[1]模型进行改进,针对stream data进行改进,提出online automatic must-links cannot-links(AMC)模型,提高模型的处理速度以及提高对于流数据的表现。
1、现在一般有5种类型的主题模型:
①半监督式主题模型:使用人工标注的种子aspect来找到更多相关的aspect;
②监督式主题模型:一般用于1个dataset来提高准确率;
③混合主题模型:使用小量标注数据来训练,然后给主题模型预测更合适的初始值;
④基于知识库的主题模型:从各个dataset中抽取知识,用该知识指导后面的学习;
⑤基于迁移学习的主题模型:使用一个dataset训练,然后作为先验知识用到另一个比较相似的dataset上测试。
2、对于Lifelong Machine Learning(LML)来说,造成topic incoherent的原因有4种[2]:
①chained(链式):A-B是同一topic,B-C也是同一topic,但A-C不是;
②intruded(闯入):多个topic set的word混合在一个topic里面;
③random:未知的随机混入;
④unbalanced:topic word set中的词都与第一个词有关,但里面混杂了general和aspect的词。
3、OAMC会对之前的dataset进行选择,因为在一个dataset中表现很好的topic应该对以后的学习应用权重比表现不好的大。
4、OAMC为了适用于online,需要追求更高的效率,所以不直接存储topic词,而是直接存储积累的知识。
5、OAMC的算法以及framework如下图。

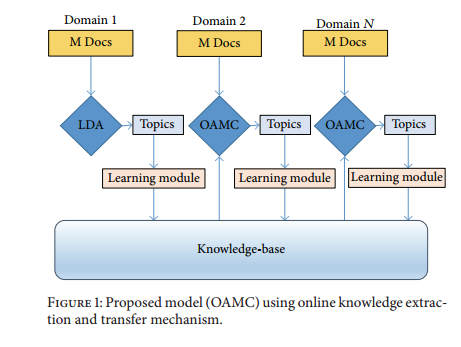
6、OAMC的知识表示方式有别于其它的LML模型,它将must-link与cannot-link的词对都放在一起,而不是分开为2个list存放,用[-1,+1]的置信度来表示,其中-1是cannot-link,+1是must-link,除此之外,加入了以下3种新的知识特征:
①Utility:该知识在之后的学习中的使用程度;
②Freshness:知识的新鲜度;
③Background:知识的上下文,用于解决词语二义性问题;
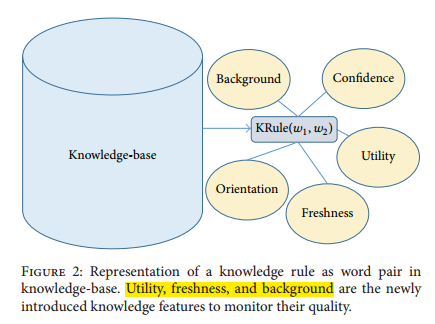
7、作者使用的知识抽取方式是nPMI(normalized PMI[3])。然后根据nPMI计算出的值,与预先设定的阈值比较,以决定是否存储改知识。
8、本文使用的知识迁移的方式是Multigeneralized Polya Urn(M-GPU)[4]。
9、dataset:Amazon 50个商品的各1000个评论。
10、参数设定:α=1,β=0.1,主题数15,2000次迭代。
11、baseline:①LDA;②LTM;③AMC;④AMC-M。
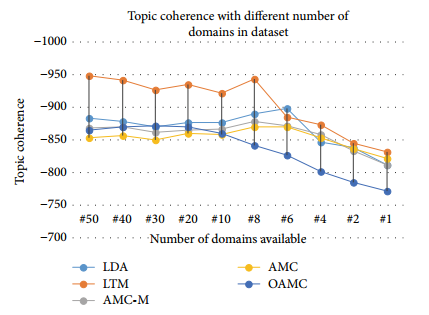
12、评测方法:topic coherence。
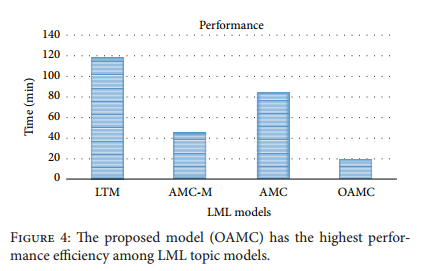
13、评测结果:发现OAMC无论是topic coherence的值,还是计算的时间,都比baseline有不少的提升。
参考资料:
[1]、Chen Z, Liu B. Mining topics in documents: standing on the shoulders of big data[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 1116-1125. (http://dl.acm.org/citation.cfm?id=2623622)
[2]、Mimno D, Wallach H M, Talley E, et al. Optimizing semantic coherence in topic models[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011: 262-272. (http://dl.acm.org/citation.cfm?id=2145462)
[3]、Bouma G. Normalized (pointwise) mutual information in collocation extraction[J]. Proceedings of GSCL, 2009: 31-40. (https://svn.spraakdata.gu.se/repos/gerlof/pub/www/Docs/npmi-pfd.pdf)
[4]、Chen Z, Liu B. Mining topics in documents: standing on the shoulders of big data[C]//Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2014: 1116-1125. (http://dl.acm.org/citation.cfm?id=2623622)
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 5374
5374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









