







discriminative model 和 generative model是机器学习算法中两种概率模型,用来实现对训练样本的概率分布进行建模,在实践中由于经常混淆,现在通过查阅资料,将两者的分别总结于此。
不妨用stackoverflow上的一段描述来开启这个话题:
Let’s say you have input data x and you want to classify the data into labels y. A generative model learns the joint probability distribution p(x,y) and a discriminative model learns the conditional probability distribution p(y|x) - which you should read as “the probability of y given
x ”. Here’s a really simple example. Suppose you have the following data in the form (x,y):(1,0),(1,0),(2,0),(2,1)
p(x,y) is
| p(x,y) | y=0 | y=1 |
|---|---|---|
| x=1 | 12 | 0 |
| 14 | 14 |
p(y|x) is
| p(y|x) | y=0 | y=1 |
|---|---|---|
| x=1 | 1 | 0 |
| 12 | 12 |
If you take a few minutes to stare at those two matrices, you will understand the difference between the two probability distributions. The distribution p(y|x) is the natural distribution for classifying a given example x into a class y, which is why algorithms that model this directly are called discriminative algorithms. Generative algorithms model p(x,y) , which can be tranformed into p(y|x) by applying Bayes rule and then used for classification. However, the distribution p(x,y) can also be used for other purposes. For example you could use p(x,y) to generate likely (x,y) pairs. From the description above you might be thinking that generative models are more generally useful and therefore better, but it’s not as simple as that. The overall gist is that discriminative models generally outperform generative models in classification tasks.
Generative models are used in machine learning for either modeling data directly (i.e., modeling observations drawn from a probability density function), or as an intermediate step to forming a conditional probability density function. A conditional distribution can be formed from a generative model through Bayes’ rule.
生成模型是对样本数据的联合概率
p(x,y)
进行建模,建模得到的联合概率
p(x,y)
可以用来生成数据对
(x,y)
,所以被称为生成模型。而判别模型则是对条件概率
p(y|x)
进行建模,即给定
x
对应
Although this topic is quite old, I think it’s worth to add this important distinction. In practice the models are used as follows.
In discriminative models to predict the label y from the training example x, you must evaluate:
Which merely chooses what is the most likely class considering x. It’s like we were trying to model the decision boundary between the classes. This behavior is very clear in neural networks, where the computed weights can be seen as a complex shaped curve isolating the elements of a class in the space.
Now using Bayes’ rule, let’s replace the
p(y|x)
in the equation by
p(x|y)p(y)p(x)
. Since you are just interested in the arg max, you can wipe out the denominator, that will be the same for every y. So you are left with
Which is the equation you use in generative models. While in the first case you had the conditional probability distribution p(y|x) , which modeled the boundary between classes, in the second you had the joint probability distribution p(x,y) , since p(x,y)=p(x|y)p(y) , which explicitly models the actual distribution of each class.
With the joint probability distribution function, given an y, you can calculate (“generate”) its respective x. For this reason they are called generative models.
Imagine your task is to classify a speech to a language:
you can do it either by:
1) Learning each language and then classifying it using the knowledge you just gained
OR
2) Determining the difference in the linguistic models without learning the languages and then classifying the speech.
the first one is the Generative Approach and the second one is the Discriminative approach.
Examples of discriminative models used in machine learning include:
- Logistic regression
- Support vector machines
- Boosting (meta-algorithm)
- Conditional random fields
- Linear regression
- Neural networks
Examples of generative models include:
- Gaussian mixture model and other types of mixture model
- Hidden Markov model
- Probabilistic context-free grammar
- Naive Bayes
- Averaged one-dependence estimators
- Latent Dirichlet allocation
- Restricted Boltzmann machine
2015-8-31 艺少
增补内容:2015-9-1
利用Discriminative model对
p(w|x)
直接进行建模:
(注:
w
在此就是
1. 为
p(w)
选择一个合适的概率分布形式
比如选择
w
服从正态分布,如图所示:
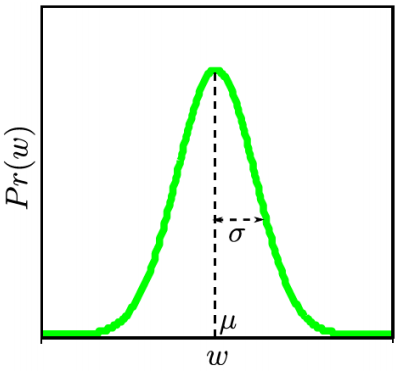
2. 通过
将正态分布的均值
μ
由
x
的线性函数表示,方差为一个常数。
3. 以
θ
为参数将定义
p(w|x)
的形状
参数为
ϕ0,ϕ1,σ2
. note: this is a linear regression model。
参数可以通过最大化后验概率(MAP),或者最大似然概率(MLE)等来实现估计。
利用Generative模型对
p(x|w)
或者是
p(x,w)
进行建模:
1. 为
p(x)
选择一个合适的概率分布形式
比如选择
x
服从正态分布,如图所示:
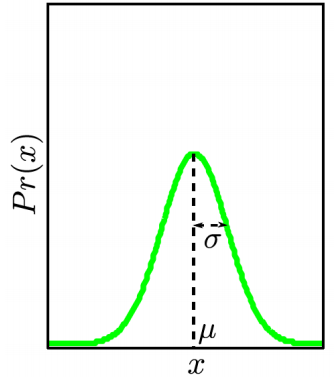
2. 通过
将正态分布的均值
μ
由
x
的线性函数表示,方差为一个常数。
3. 以
θ
为参数将定义
p(w|x)
的形状
参数为
ϕ0,ϕ1,σ2
。
参数可以通过最大化后验概率(MAP),或者最大似然概率(MLE)等来实现估计。
之后通过
p(x|w)×p(w)=p(x,w)
来计算联合概率密度,之后再通过贝叶斯概率公式,推导至
p(w|x)
。图示如下:
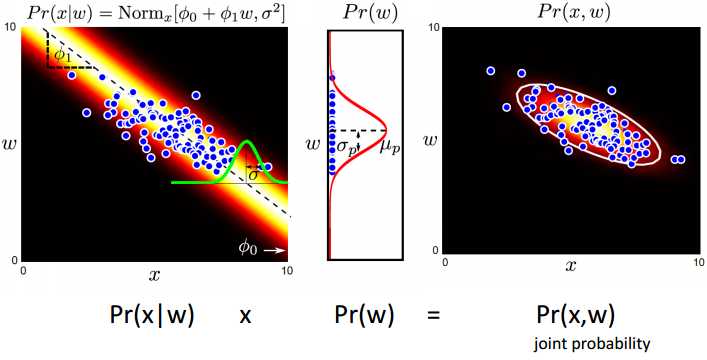
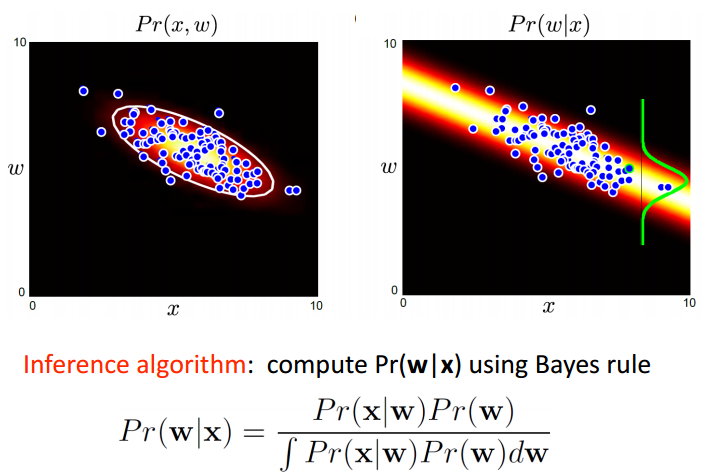
在这个例子中,如果采用最大似然估计的方法,则两个模型生成的相同的正态分布。主要是因为x,w都是连续的,而且由线性模型相关联着,都是采用的正态分布来表示不确定性。如果使用MAP即最大后验估计,两个模型将会有不同的结果。
上面主要是以连续回归的方法进行的对比,下面将通过分类离散的方法进行对比,区分效果将更加明显
利用Discriminative model对
p(w|x)
直接进行建模:
(注:
w
在此就是
1. 为
p(w)
选择一个合适的概率分布形式
比如选择
w
服从伯努利分布,如图所示:
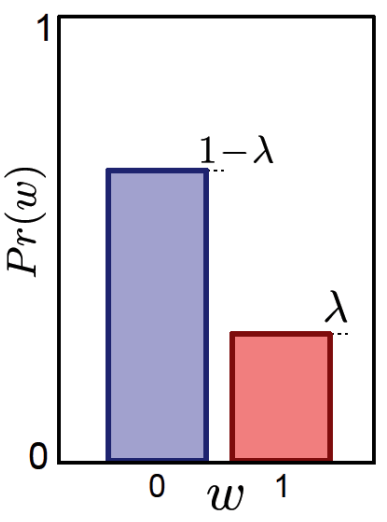
2. 通过
对伯努利分布中的参数
λ
用
x
的函数进行建模表示:
3. 以
θ
为参数将定义
p(w|x)
的形状
参数为
ϕ0,ϕ1
. note: this is a logistic regression model。
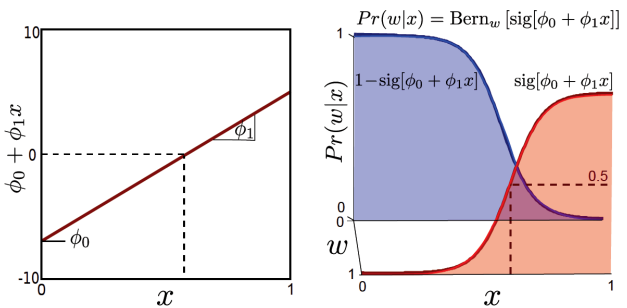
利用Generative模型对
p(x|w)
或者是
p(x,w)
进行建模:
1. 为
p(x)
选择一个合适的概率分布形式
比如选择
x
服从正态分布,如图所示:
2. 通过离散的二进制值
将正态分布的均值
μ
由
x
的线性函数表示,方差为一个常数。
3. 以
θ
为参数将定义
p(w|x)
的形状
参数为
μ0,μ1,σ20,σ21
。
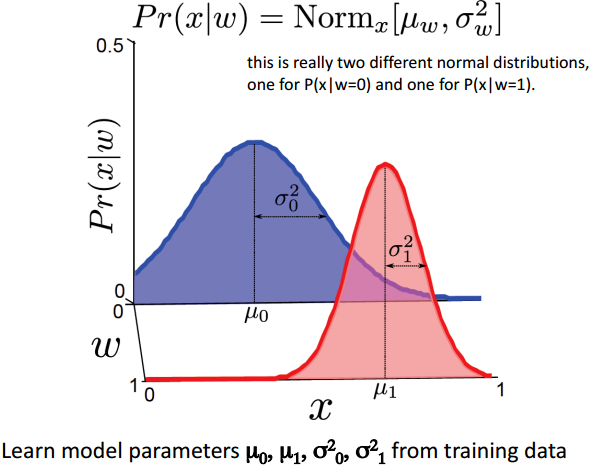
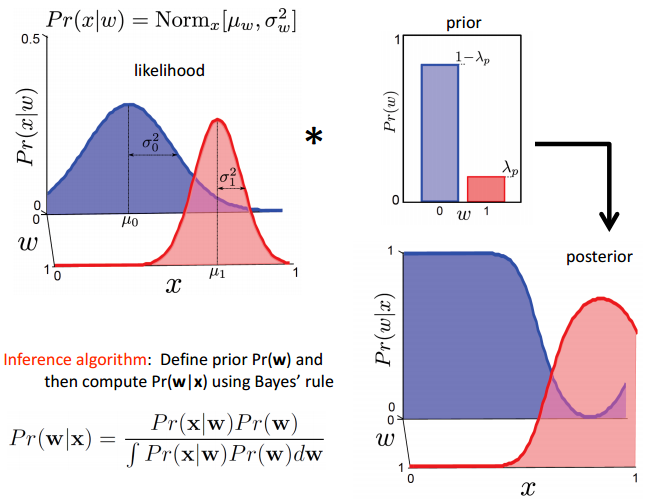
两者的对比如下图所示:
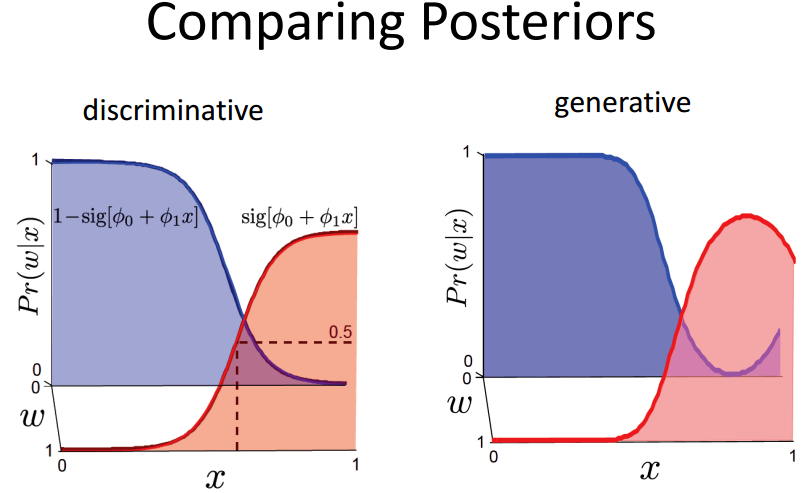
对于generative model,采用学习算法(learning algorithm)估计的是 p(x|y) 模型,而采用推理算法(inference algorithm)直接结合先验概率 p(y) ,推至联合概率密度和利用贝叶斯准则计算至后验概率 p(y|x) 。
2015-9-1 艺少















 2450
2450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











