







监督学习的方法可以分为2类,生成方法(generative approach)和判别方法(discriminative approach),所学到的模型分别为生成模型(generative model)和判别模型(discriminative model)。
生成方法:
由数据首先学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)。即通过学习先验分布来推导后验分布而进行分类
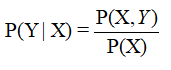
生成模型:
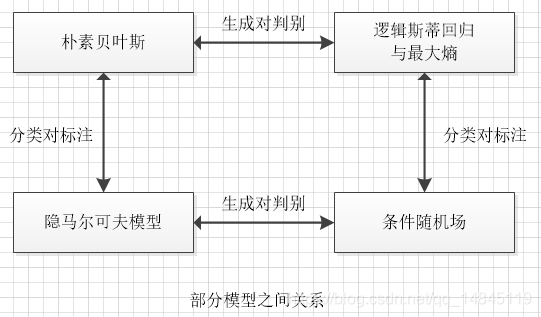
生成方法学习到的模型。包括,朴素贝叶斯(naive bayes),隐马尔可夫(HMM),混合高斯(GMM),线性判别分析(LDA)
判别方法:
由数据直接学习决策函数f(x)或者条件概率分布P(Y|X)。即直接学习后验分布来进行分类
判别模型:
判别方法学习到的模型。包括,K近邻(KNN),感知机(perceptron),决策树(decision tree),逻辑斯蒂回归(logistic regression),最大熵(MaxEnt),支持向量机(SVM),提升方法(AdaBoost),条件随机场(CRF)。
区别:
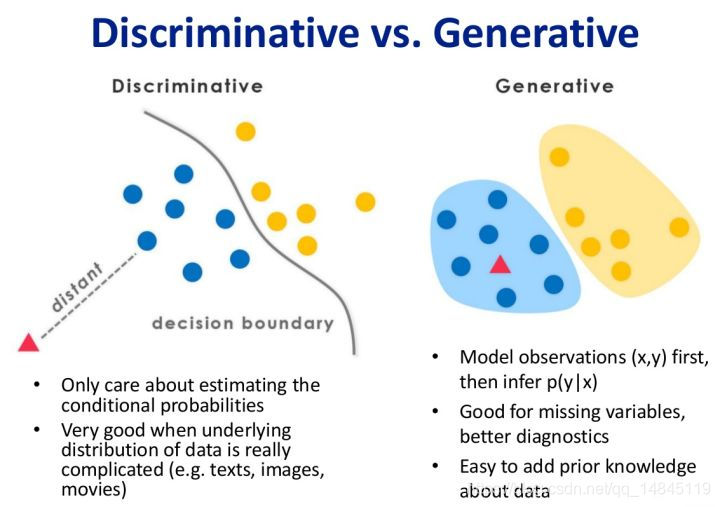
生成方法特点:
- 从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度
- 可以还原出联合概率分布P(X,Y),判别方法不能
- 随着样本容量的增加,学习收敛速度也加快
- 存在隐变量时还可以用生成方法,比如混合高斯模型,判别方法则不行
判别方法特点:
- 寻找不同类别之间的最优分类面,反映的是异类数据之间的差异
- 节省计算资源,需要的样本数量少于生成方法
- 由于直接学习决策函数f(x)或者条件概率分布P(Y|X),直接面对预测,准确性往往更高
- 可以对数据进行各种程序的抽象(降维,构造),定义并使用特征,从而简化学习问题
联系:
举例:
判别式模型举例:要确定一个羊是山羊还是绵羊,用判别模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成式模型举例:利用生成模型是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,在放到绵羊模型中看概率是多少,哪个大就是哪个。
细细品味上面的例子,判别式模型是根据一只羊的特征可以直接给出这只羊的概率(比如logistic regression,这概率大于0.5时则为正例,否则为反例),而生成式模型是要都试一试,最大的概率的那个就是最后结果。
References:
https://www.zhihu.com/question/20446337

















 4466
4466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









