







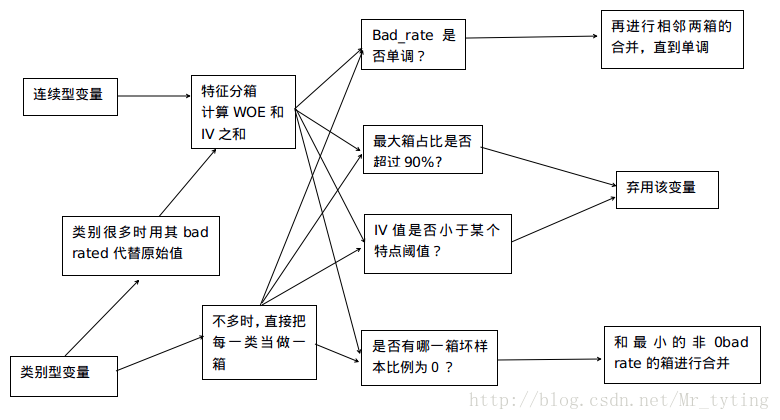
上一篇博文中,我们对数据进行了特征工程处理,包括特征分箱,WOE编码,计算IV值,进行单变量,多变量的分析等一系列的处理。总结特征分箱的一些处理办法如下图的流程图:
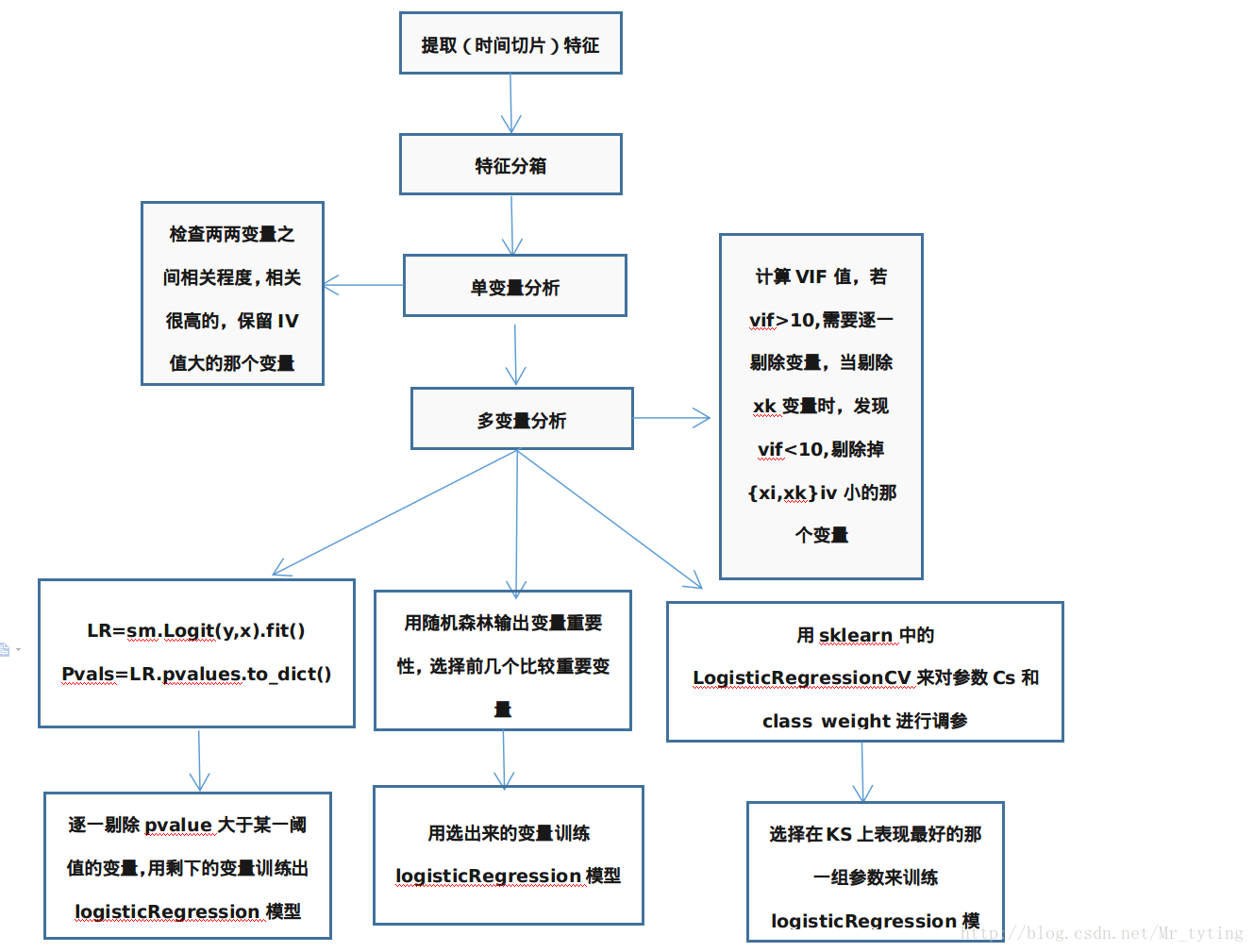
那么本篇博文在上篇博文的基础上,建立logisticRegression模型,其主要思想的流程图如下,其中特征分箱部分就是对应上面流程图:
logsiticRegression介绍
有关logsiticRegression详细介绍请看我的另外一篇博文logistic回归
特征选择
在实际场景中,金融数据的维度可能会非常大,那么有必要做一些特征选择,选择一些比较重要的特征来训练模型。有关特征选择详细的说明可以参考我的另外一篇博文sklean特征选择
逻辑回归中的权重问题
两类错误
- 第一类错误:将逾期人群预测成非逾期
- 第二类错误:将非逾期人群预测成逾期
以上两种误判的代价不一样!
增加逾期类样本的权重
在目标函数或者是损失函数中增加逾期权重。然后梯度下降法对参数进行估计。
评分卡模型中
- 逾期样本的权重总是高于非逾期样本的权重
- 可以用交叉验证法选择合适的权重
- 也可以跟业务相结合:权重通常跟利率有关。利率高,逾期样本的权重相对低
模型训练
对特征进行了单变量,多变量分析以后,剔除了一些冗余,多重共线性的变量以后。
sm.Logit:
import statsmodels.api as sm
var_WOE_list = [i+'_WOE' for i in var_IV_sortet_2]
y = trainData['target']
X = trainData[var_WOE_list]
X['intercept'] = [1]*X.shape[0]
LR = sm.Logit(y, X).fit()
summary = LR.summary()
pvals = LR.pvalues
pvals = pvals.to_dict()## 获取每个变量的显著性p值,p值越大则越不显著。
### Some features are not significant, so we need to delete feature one by one.
varLargeP = {k: v for k,v in pvals.items() if v >= 0.1}
varLargeP = sorted(varLargeP.iteritems(), key=lambda d:d[1], reverse = True)
while(len(varLargeP) > 0 and len(var_WOE_list) > 0):
# In each iteration, we remove the most insignificant feature and build the regression again, until
# (1) all the features are significant or
# (2) no feature to be selected
varMaxP = varLargeP[0][0]
if varMaxP == 'intercept':
print 'the intercept is not significant!'
break
var_WOE_list.remove(varMaxP)
y = trainData['target']
X = trainData[var_WOE]
X['intercept'] = [1] * X.shape[0]
LR = sm.Logit(y, X).fit()
summary = LR.summary()
pvals = LR.pvalues
pvals = pvals.to_dict()
varLargeP = {k: v for k, v in pvals.items() if v >= 0.1}
varLargeP = sorted(varLargeP.iteritems(), key=lambda d: d[1], reverse=True)
注意这里调用的是statsmodels.api里的逻辑回归。这个回归模型可以获取每个变量的显著性p值,p值越大越不显著,当我们发现多于一个变量不显著时,不能一次性剔除所有的不显著变量,因为里面可能存在我们还未发现的多变量的多重共线性,我们需要迭代的每次剔除最不显著的那个变量。
上面迭代的终止条件:
①剔除了所有的不显著变量
②剔除了某一个或某几个变量后,剩余的不显著变量变得显著了。(说明之前存在多重共线性)
RandomForest:
X = trainData[var_WOE_list]
X = np.matrix(X)
y = trainData['target']
y = np.array(y)
RFC = RandomForestClassifier()
RFC_Model = RFC.fit(X,y)
features_rfc = trainData[var_WOE_list].columns
featureImportance = {features_rfc[i]:RFC_Model.feature_importances_[i] for i in range(len(features_rfc))}
featureImportanceSorted = sorted(featureImportance.iteritems(),key=lambda x: x[1], reverse=True)
# we selecte the top 10 features
features_selection = [k[0] for k in featureImportanceSorted[:10]]
y = trainData['target']
X = trainData[features_selection]
X['intercept'] = [1]*X.shape[0]
LR = sm.Logit(y, X).fit()
summary = LR.summary()
sklearn中的logsiticRegressionCV:
X = trainData[var_WOE_list] #by default LogisticRegressionCV() fill fit the intercept
X = np.matrix(X)
y = trainData['target']
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)
X_train.shape, y_train.shape
model_parameter = {}
for C_penalty in np.arange(0.005, 0.2,0.005):## 选择适合的参数Cs,Cs越大选择的特征数越少。
for bad_weight in range(2, 101, 2):## 选择适合的正负样本的权重比例,对正负样本给予不同重视程度。
LR_model_2 = LogisticRegressionCV(Cs=[C_penalty], penalty='l1', solver='liblinear', class_weight={1:bad_weight, 0:1})## 运用L1正则化
LR_model_2_fit = LR_model_2.fit(X_train,y_train)
y_pred = LR_model_2_fit.predict_proba(X_test)[:,1]
scorecard_result = pd.DataFrame({'prob':y_pred, 'target':y_test})
performance = KS_AR(scorecard_result,'prob','target')
KS = performance['KS']
model_parameter[(C_penalty, bad_weight)] = KS
选择在ks指标上效果最好的参数进行模型训练。
### Calculate the KS and AR for the socrecard model
def KS_AR(df, score, target):
'''
:param df: the dataset containing probability and bad indicator
:param score:
:param target:
:return:
'''
total = df.groupby([score])[target].count()
bad = df.groupby([score])[target].sum()
all = pd.DataFrame({'total':total, 'bad':bad})
all['good'] = all['total'] - all['bad']
all[score] = all.index
all = all.sort_values(by=score,ascending=False)
all.index = range(len(all))
all['badCumRate'] = all['bad'].cumsum() / all['bad'].sum()
all['goodCumRate'] = all['good'].cumsum() / all['good'].sum()
all['totalPcnt'] = all['total'] / all['total'].sum()
arList = [0.5 * all.loc[0, 'badCumRate'] * all.loc[0, 'totalPcnt']]
for j in range(1, len(all)):
ar0 = 0.5 * sum(all.loc[j - 1:j, 'badCumRate']) * all.loc[j, 'totalPcnt']
arList.append(ar0)
arIndex = (2 * sum(arList) - 1) / (all['good'].sum() * 1.0 / all['total'].sum())
KS = all.apply(lambda x: x.badCumRate - x.goodCumRate, axis=1)
return {'AR':arIndex, 'KS': max(KS)}














 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









