







跟LSTM初探一样,这次依旧选择利用Keras来构建CNN。
基本的构建代码如下:
def CNN_model(trainArray, testArray, trainLabels, testLabels):
model = Sequential()
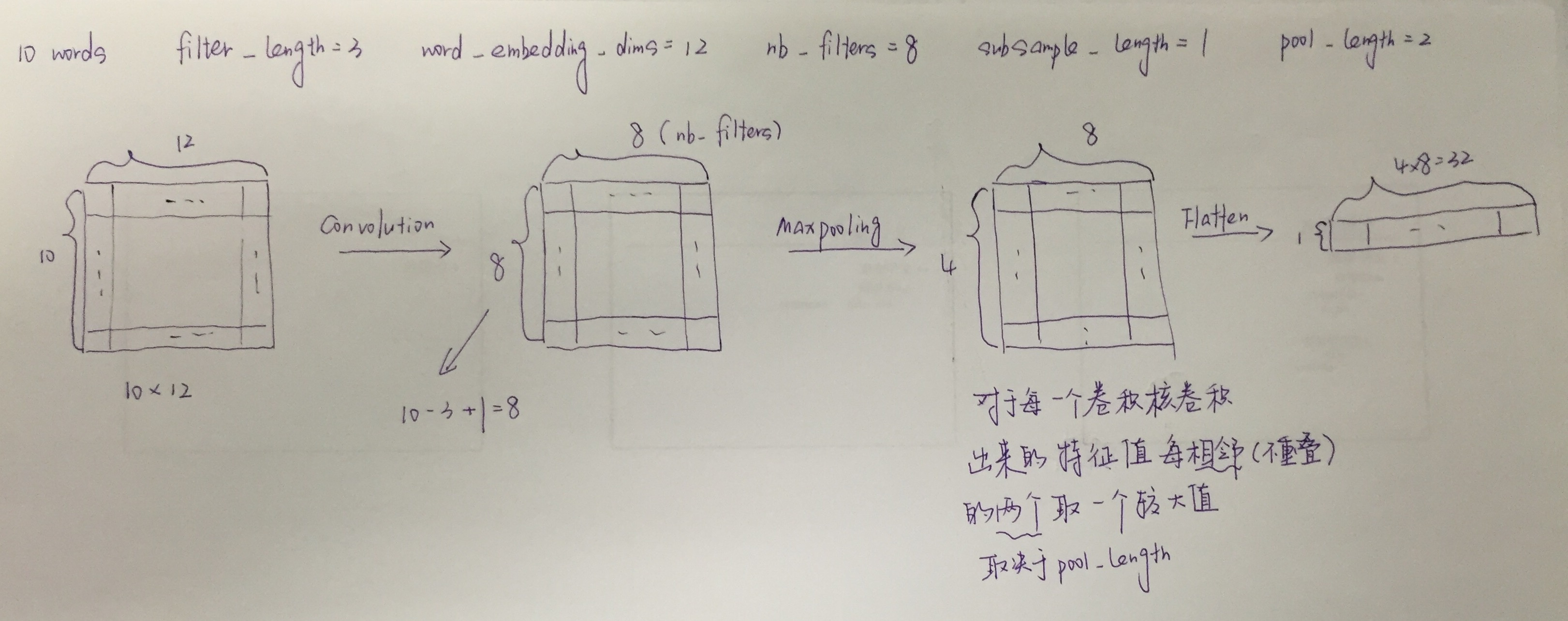
model.add(Convolution1D(nb_filter = nb_filters, filter_length = filter_length, border_mode = "valid", activation = "relu", input_shape = (maxlen, embedding_dims), subsample_length = 1))
model.add(MaxPooling1D(pool_length = 2))
model.add(Flatten())
model.add(Dense(hidden_dims, activation = "relu"))
model.add(Dropout(0.25))
model.add(Dense(1, activation = "sigmoid"))
model.compile(loss = "binary_crossentropy", optimizer = "rmsprop", class_mode = "binary")
hist = model.fit(trainArray, trainLabels, batch_size = batch_size, nb_epoch = nb_epoch, verbose = 2, validation_data = (valArray, valLabels))
preLabels = model.predict_classes(testArray, batch_size = batch_size, verbose = 2)Convolution1D用于定义一个卷积操作,1D代表过滤一维输入的相邻元素。nb_filter代表卷积核的数目,filter_length 代表每次参与卷积的词数,border_mode 代表卷积的模式,有valid跟same两种,activation代表激励函数,input_shape代表输入数据的形状,CNN中输入数据的第一个维度为词数,subsample_length代表每次卷积操作的步长。
MaxPooling1D用于定义一个池化操作,也就是所谓的子采样。pool_length代表采样间隔。
Flatten用于将多维的输入转换为一维。
其他的操作跟构建LSTM时类似。
我用一张图大概解释了一下整个过程,字丑勿喷。














 3256
3256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









