






本文使用CNN模型,Conv1d卷积进行时间序列的分析处理。将数据导入模型后,可以运行。但模型预测精度不高,且输出十分不稳定。此模型仅用于熟悉CNN模型的基本结构,如有错误,还望海涵。
一、数据介绍
数据长度为252,在导入模型时,将80%的数据用于模型训练,20%的数据用于模型验证。
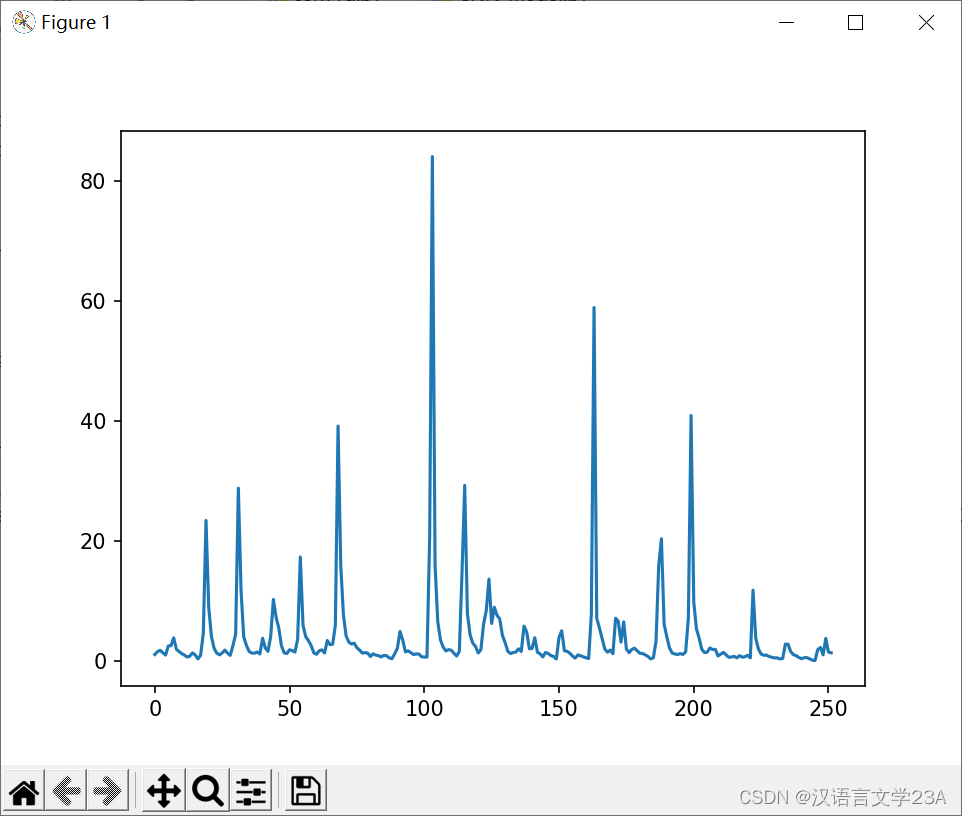
二、数据预处理
先对数据进行归一化处理,以加快模型运行速度。数据预测原理为,将n个数据分为一组,用前n-1个数据来预测第n个数据,通过预测值与实际值计算损失值。再向后推进,每次推进长度为1。
例如,如果数据序列为[1,2,3,4,5,6],n=4。则第一次将[1,2,3]输入模型,将模型输出结果和4导入损失计算函数进行损失计算,下一次将[2,3,4]导入,以此类推。
三、模型代码
模型结构

模型定义代码
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
class CNNnetwork(nn.Module):
def __init__(self):
super().__init__()
self.conv1d = nn.Conv1d(1, 64, kernel_size=2)
self.relu = nn.ReLU(inplace=True)
self.Linear1 = nn.Linear(64 * 8, 50)
self.Linear2 = nn.Linear(50, 1)
def forward(self, x):
x = self.conv1d(x)
x = self.relu(x)
x = x.view(-1)
x = self.Linear1(x)
x = self.relu(x)
x = self.Linear2(x)
return x
if __name__ == '__main__':
mod = CNNnetwork()
input = torch.ones(1, 1, 9)
out = mod(input)
print(out.shape)
writer = SummaryWriter('logdir')
writer.add_graph(mod, input)
writer.close()
模型训练与验证
import pandas as pd
import numpy as np
import torch
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from CNN_model import *
Datasets = pd.read_excel(io='dataset.xlsx', sheet_name='Sheet1', usecols='D')
data = Datasets['data'].values.astype(float)
train_set = data[:-int(len(data) * 0.2)]
test_set = data[-int(len(data) * 0.2):]
# print(len(train_set)) # 202
# print(len(test_set)) # 50
scaler = MinMaxScaler(feature_range=(-1, 1))
train_norm = scaler.fit_transform(train_set.reshape(-1, 1))
train_norm = torch.FloatTensor(train_norm).view(-1)
train_data = []
seq_size = 9
for i in range(len(train_norm) - seq_size):
window = train_norm[i:i + seq_size]
label = train_norm[i + seq_size]
train_data.append((window, label))
mod = CNNnetwork()
loss_fn = nn.MSELoss()
learning_rate = 1e-2
optimizer = torch.optim.SGD(mod.parameters(), lr=learning_rate)
# optimizer = torch.optim.Adam(mod.parameters(), lr=learning_rate)
total_train_step = 0
epoch = 500
loss_list = []
mod.train()
for i in range(epoch):
for seq, y_true in train_data:
optimizer.zero_grad()
out = mod(seq.reshape(1, 1, -1))
loss = loss_fn(out, y_true)
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 1000 == 0:
print('训练次数:{},loss:{}'.format(total_train_step, loss.item()))
loss_list.append(loss.item())
preds = train_norm[-seq_size:].tolist()
mod.eval()
for i in range(52):
seq = torch.FloatTensor(preds[-seq_size:])
with torch.no_grad():
preds.append(mod(seq.reshape(1, 1, -1)).item())
print(preds)
true_value = scaler.inverse_transform(np.array(preds[seq_size:]).reshape(-1, 1))
print(true_value.tolist())
print(test_set)
plt.figure(1)
plt.plot(test_set, label='true value')
plt.plot(true_value, label='predict value')
plt.legend(loc="upper left")
plt.figure(2)
plt.plot(loss_list, label='loss')
plt.show()
torch.save(mod, 'mod_1.pth')
代码中,每10个数据为一组,用reshape函数使数据符合Conv1d要求。
四、模型输出结果
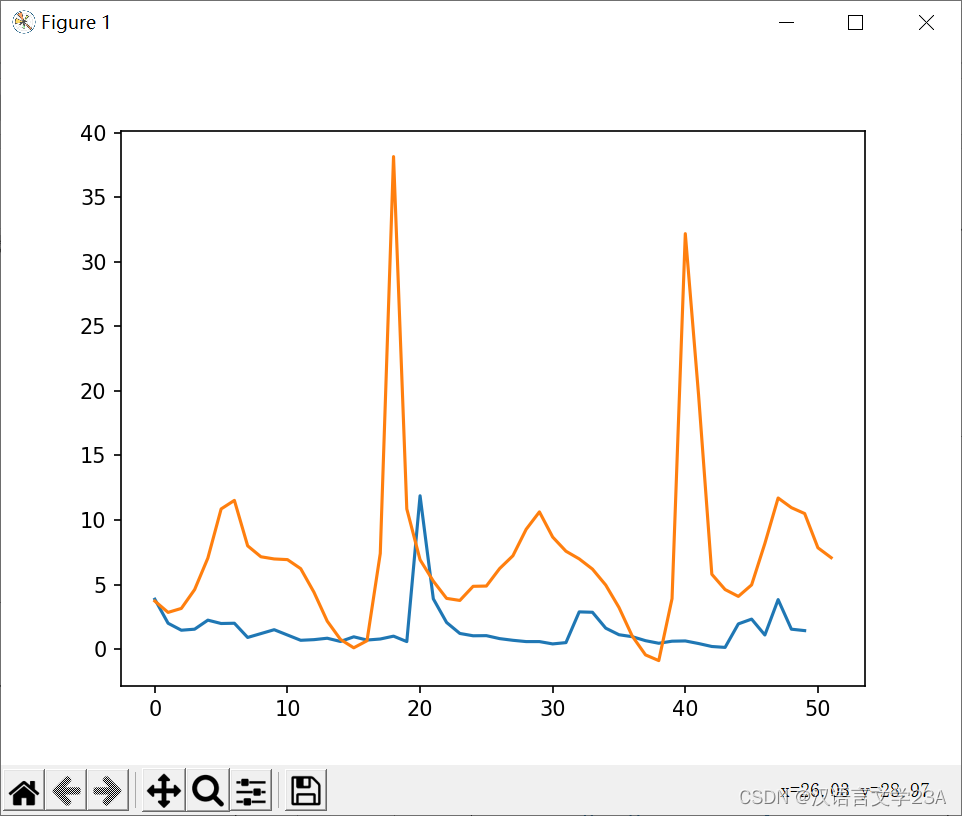
再不断调整损失函数、优化器、学习率、训练次数后,模型拟合效果依然不稳定。最大的原因可能为数据之间无直接关联性,无法通过数字间的关联找出规律。
下面为50个验证数据的拟合效果,蓝色线条为真实值,橙色为模型拟合值。
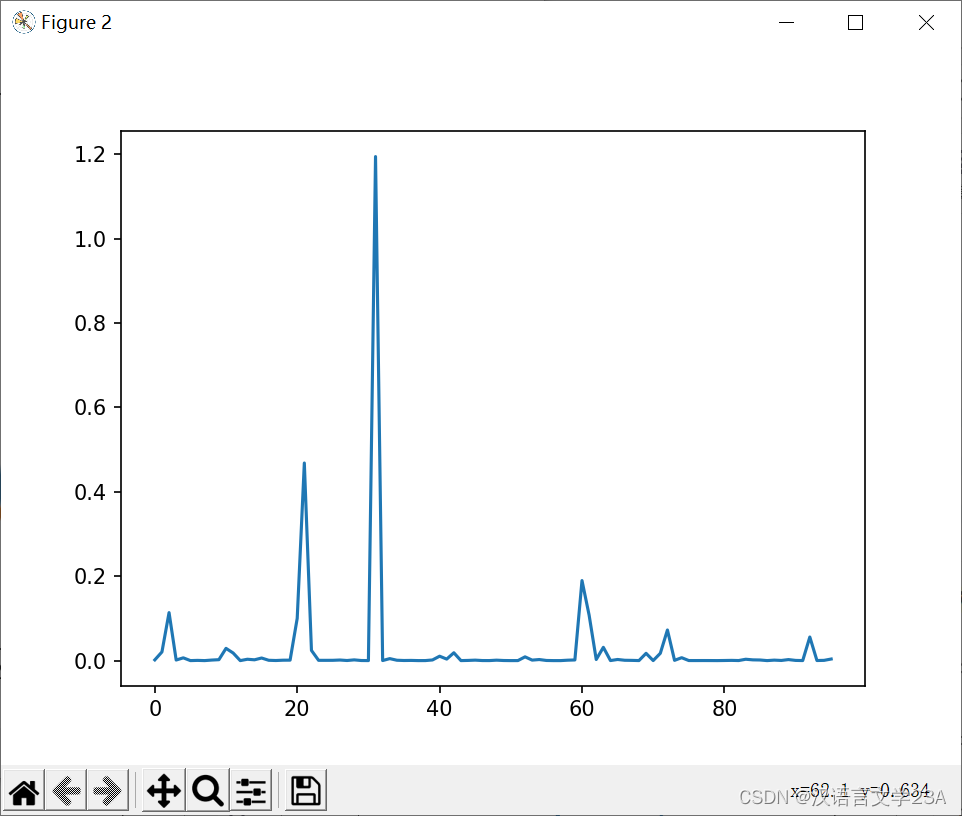
下图为模型训练过程中损失变化,每一千次训练记录一次损失。
五、参考文献
本文数据处理及模型构建思路参考了以下文章:CNN实现时间序列预测(PyTorch版)















 1050
1050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









