









bias-variance tradeoffs是有监督学习面临的一个重要的问题。我们希望达到的最佳的状态就是low variance, low bias。 一旦出现过拟合现象, 就容易造成low bias, high variance的线性, 欠拟合是high bias, low variance。
对于线性模型中, 我们假设样本取自的分布为:
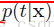
好了, 我们根据这就可以求出最佳的hyposis, 并可以使用这个hyposis进行预测:

我们的loss function 如下:
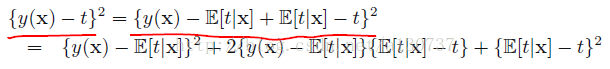
对上述值取期望, 就是expected loss function, 如下:
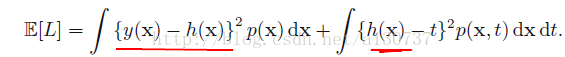
注意, 上述的式子的第二项与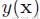
的。 但是实际中, 我们只有一个有限大小的训练数据集D(假如样本的数目为N), 所以我们根本无法准确的求得
。
对于一个数据集D,我们使用学习算法能够获得一个对应的. 注意当我们的训练样本集D发生变化的时候, 我们可能得到一个不同的预测函数。
所以我们的预测函数是依赖于我们的训练样本集的。 于是E[L]的第一项的积分对象如下:
进行如下变化:
于是, 上述两边去期望:
上述第一项称为squared bias, 代表着对于所有可能的训练data sets的一个平均预测误差(较之于desired regression funtion), 第二项被称为variance, 计算的是对于每一个单独的data set, 得到的偏离他们自身的均值的程度。 也就是说第二项是衡量函数
对一个particular choice of data set的灵敏度(sentivitity)。
最终, 我们吧我们的期望二次缺损表示成如下的表达式:
其中:
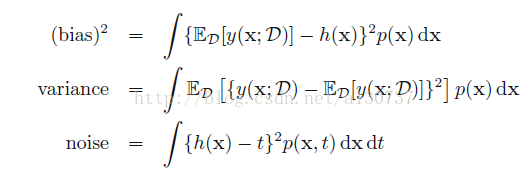














 2598
2598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









