







C3D:视频动作分类demo实现
C3D这个网络是来自于learning Spatiotemporal feature with 3DConvolutional Networks这篇文章,我也对这篇文章仔细的研读过,我觉得这个网络具有两个非常具有竞争力的优点:一是速度快;而是单纯的使用未进过任何预处理的RGB特征进行训练就具有很不错的准确率;我对项目主页上的代码也运行过,而且按照C3D Guide 的步骤让ucf101数据集上在已有的网络上进行微调,微调后的测试准确率达到了80.169%,下面主要是简单的介绍我实现C3D network的项目主页上的视频动作分类演示的demo。下面演示的视频都是来自于ucf101数据中的。
1.ucf101数据集总共有101类,如下图,我使用批量获取文件夹名的方式获得了这101类的名称并保存在list.txt文件中如下:


下面是我再ucf101数据集中随机选取的部分视频,将这些视频输入到C3D网络中,获得了这些视频的分类结果,并将结果保存在了相应的.prob文件中,如下:

文件夹的文件如下:

下面是相应的代码:
#include<iostream>
#include<stdio.h>
#include<vector>
#include<fstream>
#include<opencv2/opencv.hpp>
#define video_index_max 101
/************************************************************************
函数功能:从已经获取ucf101数据集所有类名称的txt文件中读入视频类别名称,共101类
输入参数:filename是.txt文件路径,videoname是保存101类的名称
输出参数:
************************************************************************/
void ReadVideoClass(const std::string& filename, std::vector<std::string>&videoname)
{
std::fstream file0;
file0.open(filename);
if (!file0.is_open())
{
std::cerr << "fail to open the all name file" << std::endl;
exit(0);
}
char temp0[1000];
while (!file0.eof())
{
file0.getline(temp0, 1000);
std::string line(temp0);
videoname.push_back(line);
}
if (videoname.size() != video_index_max) //如果读入的所有名称数量小于101类,则输入文件有误
{
std::cerr << " video class file have error size" << std::endl;
exit(0);
}
file0.close();
}
/************************************************************************
函数功能:获取所有的从C3D网络输出并保存的.prob文件的路径
输入参数:filename是.txt文件路径,videoname是保存101类的名称
输出参数:
************************************************************************/
void ReadAllTestResultPath(const std::string& filename, std::vector<std::string>&ResultPath)
{
std::fstream file1;
file1.open(filename);//读取视频文件路径
if (!file1.is_open())
{
std::cerr << "fail to open the test result file" << std::endl;
exit(0);
}
char temp[1000];
while (!file1.eof())
{
file1.getline(temp, 1000);
std::string line(temp);
//去除可能存在的空格,并添加后缀.prob
std::string PostfixLine;//测试结果文件保存路径
std::string::size_type npos0 = line.find_last_of(" ");
if (npos0 == line.size() - 1){
PostfixLine = line.substr(0, npos0);
PostfixLine += ".prob";
}
else
PostfixLine = line + ".prob";
std::cout << PostfixLine <<std::endl;
ResultPath.push_back(PostfixLine);
}
file1.close();
}
/************************************************************************
函数功能:
输入参数:
输出参数:
************************************************************************/
void ReadLine(const std::string & path, std::string &Videopath, int &StartIndex, std::string& ground_truth)
{
std::string line = path;
StartIndex = atoi(line.substr(line.find_last_of("/") + 1, line.size() - 5).c_str());
ground_truth = line.substr(line.find("output/") + strlen("output/"), line.find("/v_") - strlen("output/"));
line.erase(0, 6); line.erase(line.find_last_of("/"), line.size());
line.insert(0, "F:/ucf101"); line += ".avi";
Videopath = line;
}
/************************************************************************
函数功能:从.prob文件中读入C3D网络的输出结果
输入参数:.prob文件路径
输出参数:101类的预测输出结果 blob
************************************************************************/
bool read_blob(const std::string &probfile, std::vector<float>&blob)
{
/*读取模型提取的特征文件中的参数*/
std::ifstream fin(probfile, std::ios::binary);
if (!fin.is_open()){ std::cerr << probfile << "file not exist " << std::endl; return 0; }
int num=0, channel=0, length=0, height=0, width=0;
fin.read((char*)&num, sizeof(int));
fin.read((char*)&channel, sizeof(int)); if (channel != video_index_max) return 0;
fin.read((char*)&length, sizeof(int));fin.read((char*)&height, sizeof(int));
fin.read((char*)&width, sizeof(int));
float ptr = 0;
for (int i = 0; i < channel; i++)
{
fin.read((char*)&ptr, sizeof(float));
blob.push_back(ptr);
}
return 1;
}
/************************************************************************
函数功能:从数组vec中找出最大值,返回最大值和最大值对应的序号
输入参数:数组vec,数组大小num,引用返回的数组最大值rate
输出参数:最大值对应的序号
************************************************************************/
int find_sec_max(std::vector<float>vec,int num,float &rate)
{
int index = -1;
if (vec.size() != num)
return -1;
float maxc = 0;
for (int i = 0; i < vec.size();i++)
{
if (vec[i]>maxc)
{
maxc = vec[i]; index = i;
}
}
rate = maxc;
return index;
}
int main()
{
using namespace std;
using namespace cv;
std::vector<std::string>videoname;
ReadVideoClass("output\\list.txt", videoname);
std::vector<std::string>ResultPath;
ReadAllTestResultPath("output\\last-test-output.lst", ResultPath);
VideoWriter writer("VideoTest.avi", CV_FOURCC('M', 'J', 'P', 'G'), 25.0, Size(320,240));
vector<string>TestResultAll;
vector<float>TestResultAllRate;
vector<string>GroundTrueAll;
for (size_t i = 0; i < ResultPath.size(); i++)
{
std::string Videopath; int StartIndex; std::string ground_truth;
ReadLine(ResultPath[i], Videopath, StartIndex, ground_truth);
std::vector<float>blob;
int flag = read_blob(ResultPath[i], blob);
if (!flag) { cerr << "blob read failed" << endl; exit(0); }
float maxrate = 0;
int TestResult = find_sec_max(blob, video_index_max, maxrate);
VideoCapture capture;
capture.open(Videopath);
int count = StartIndex;
int countcopy = count;
Mat frame;
while (countcopy--)//每次写视频时,都跳过前count帧开始写
{
capture >> frame;
}
while (count<StartIndex+16)//每个视频段的大小都是16帧,
{
capture >> frame;//先读入至frame中
writer << frame;//将frame保存到writer中
TestResultAll.push_back(videoname[TestResult]);//每一帧都赋予一个检测结果(string类型),并将检测结果保存在TestResultAll中
TestResultAllRate.push_back(maxrate);//每一帧每一帧都赋予一个检测概率(float类型),并将检测概率值保存在TestResultAllRate中
GroundTrueAll.push_back(ground_truth);//每一帧都有一个ground truth
count++;
}
}
//writer.release();
VideoCapture writercapture; writercapture.open("VideoTest.avi");
VideoWriter VideoTest("VideoTestAll.avi", CV_FOURCC('M', 'J', 'P', 'G'), 25.0, Size(320, 240));
int count = 0;
while (1)
{
Mat frame;
writercapture >> frame;
if (!frame.data)
break;
string result = TestResultAll[count];
float ratio = TestResultAllRate[count];
char stemp[200];
sprintf(stemp, "( %.3f )", ratio);
string truth = GroundTrueAll[count];
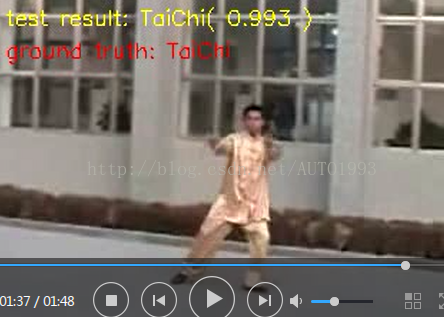
cv::putText(frame, "test result: "+result+stemp, cv::Point(5, 25), CV_FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 255));
cv::putText(frame, "ground truth: "+truth, cv::Point(5, 48), CV_FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 255));
imshow("frame", frame);
waitKey(30);
VideoTest << frame;
count++;
}
VideoTest.release();
return 0;
}




下面是提出C3D这个网络的原文learning Spatiotemporal feature with 3DConvolutional Networks的介绍,摘自一位很牛的博主的一篇笔记:
http://blog.csdn.net/wzmsltw/article/details/61192243
这篇文章提出的网络的卷积神经网络(CNN)近年被广泛应用于计算机视觉中,包括分类、检测、分割等任务。这些任务一般都是针对图像进行的,使用的是二维卷积(即卷积核的维度为二维)。而对于基于视频分析的问题,2D convolution不能很好得捕获时序上的信息。因此3D convolution就被提出来了。3D convolution 最早应该是在[1]中被提出并用于行为识别的,本篇文章则主要介绍下面这篇文章 C3D,C3D network是作为一个通用的网络提出的,文章中将其用于行为识别,场景识别,视频相似度分析等领域。
可以访问C3D network的项目主页或是github获得其项目代码及模型,项目基于caffe实现。最近作者还更新了残差网络结构的新C3D模型,但是还没有放出对应的论文,暂时不做讨论。
2D 与 3D 卷积操作

首先简要介绍一下2D与3D卷积之间的区别。a)和b)分别为2D卷积用于单通道图像和多通道图像的情况(此处多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的图片,即一小段视频),对于一个滤波器,输出为一张二维的特征图,多通道的信息被完全压缩了。而c)中的3D卷积的输出仍然为3D的特征图。
现在考虑一个视频段输入,其大小为 c∗l∗h∗w ,其中c为图像通道(一般为3),l为视频序列的长度,h和w分别为视频的宽与高。进行一次kernel size为 3∗3∗3 ,stride为1,padding=True,滤波器个数为K的3D 卷积后,输出的大小为 K∗l∗h∗w 。池化同理。
3D 卷积核参数的选择

作者还对卷积核的尺寸进行了实验研究,结果表面 3∗3∗3 大小的卷积核效果最好。
C3D network 结构

基于3D卷积操作,作者设计了如上图所示的C3D network结构。共有8次卷积操作,4次池化操作。其中卷积核的大小均为 3∗3∗3 ,步长为 1∗1∗1 。池化核的大小为 2∗2∗2 ,步长为 2∗2∗2 ,但第一层池化除外,其大小和步长均为 1∗2∗2 。这是为了不过早缩减时序上的长度。最终网络在经过两次全连接层和softmax层后就得到了最终的输出结果。网络的输入尺寸为 3∗16∗112∗112 ,即一次输入16帧图像。
实验结果
接下来介绍一下C3D的实验结果,作者将C3D在行为识别、动作相似度标注、场景与物体识别这三个方向的数据库上进行了测试,均取得了不错的效果。注意以下结果均为当时情况下的比较(2015年),从那时候到现在这些数据库不知道又被刷了多少遍了。。
行为识别-Action Recognition

行为识别用的数据库是UCF101,C3D+SVM的结果达到了85.2%。UCF101这个数据库目前为止(2017年3月)看到最高的结果已经达到了96%左右。
动作相似度标注-Action Similarity Labeling

动作相似度标注问题的任务是判断给出的两段视频是否属于相同的动作。文章中使用的数据库为ASLAN。C3D的效果超过了当时的state of the art 不少。
场景识别-Scene Recognition

场景识别问题主要使用了Maryland和YUPENN,也都达到了不错的效果。
运行时间分析
下表中是C3D与其他一些算法的速度比较。其中iDT是行为识别领域的非深度学习方法中效果最好的方法,可以见我之前的博文iDT算法介绍。Brox指Brox提出的光流计算方法[3].

这几部分我都跑过相关的实验,其中光流计算(GPU版本)现在的速度可以达到20-25fps,我使用的光流计算代码的github地址为gpu_flow。表中C3D的速度应该是在视频帧无重叠的情况下获得的。将一段16帧的视频作为一个输入,则C3D一秒可以处理约42个输入(显卡为1080, batch size选为50),换算成无重叠情况下的fps为672。可见C3D的速度还是非常快的。
总结
C3D使用3D CNN构造了一个效果不错的网络结构,对于基于视频的问题均可以用来提取特征。可以将其全连接层去掉,将前面的卷积层放入自己的模型中,就像使用预训练好的VGG模型一样。















 2951
2951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









