







Backpropagation Algorithm
反向传导算法
建立损失函数
首先要明确,神经网络的训练就是寻找最佳的权重W和偏置项b的过程,单个样本的求解的目标函数,也就是损失函数为:
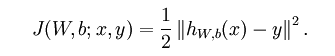
如果有多个样本,那么就是将多个损失函数求和,通常为了防止过拟合要加入规则化项(权重衰减项),公式如下:
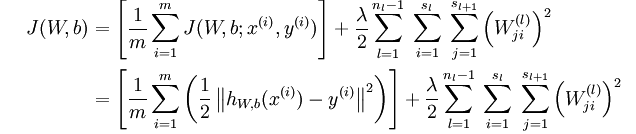
为什么这样会防止过拟合呢?
将w单独列出,如果其惩罚因子越大那么它的值就会越小,试想一下,如果在二维平面中,斜率减小,是不是会减小震荡呢?减小震荡意味着更加鲁棒!
梯度下降求解
上面可以看出神经网络的求解是一个二次规划的问题,就可以利用梯度下降法等等迭代公式来求了。迭代求解公式如下:
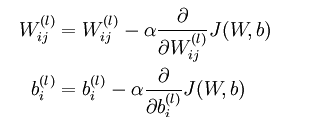
注意初值设置
要注意的是最初值的选取不能是全都一样的值,为什么呢?
原文是这样说的:
最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为 0。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数
(也就是说,对于所有 i,
W(1)ij
都会取相同的值,那么对于任何输入 x 都会有:
a(2)1=a(2)2=a(2)3=…
。)
随机初始化的目的是使对称失效。
具体一点,还记得上节中神经网络的表达式了没
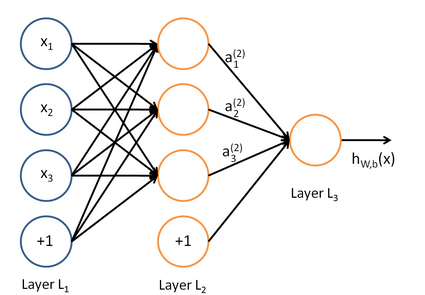
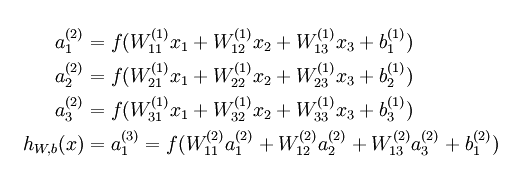
如果全部的W都一样,那么a1,a2,a3….等隐藏层的单元输入都为相同的值,如果输入都一样那么和只有一个也就没有什么两样了。因为代入到后面的算法中得到的答案是相同的(还可以看知乎的相关问题)。
反向传递算法
现在开始进入重头戏了,到前面为止,我们还没有完全解出此神经网络的
Wi,j
,下面就开始利用反向传导算法了
前面的迭代求导公式的关键在于如何求出偏导数的值
这个偏导数是求
Wi,j
的偏导数,对于每一个样本都会有一个
Wi,j
,上式的偏导数就是所有点的偏导数的平均值(这样说不严谨了,原文有公式)。
说了 这么多还是没有开始计算偏导数,下面真的开始了
首先根据链式求导
其中第二部分为输入值 a ,第一部分为原文中的
http://ufldl.stanford.edu/wiki/index.php/%E5%8F%8D%E5%90%91%E4%BC%A0%E5%AF%BC%E7%AE%97%E6%B3%95
后面要做的就是利用求导的偏导数,进行逐步迭代计算了。
============
发现之前没写完,给个链接
http://www.mamicode.com/info-detail-671452.html

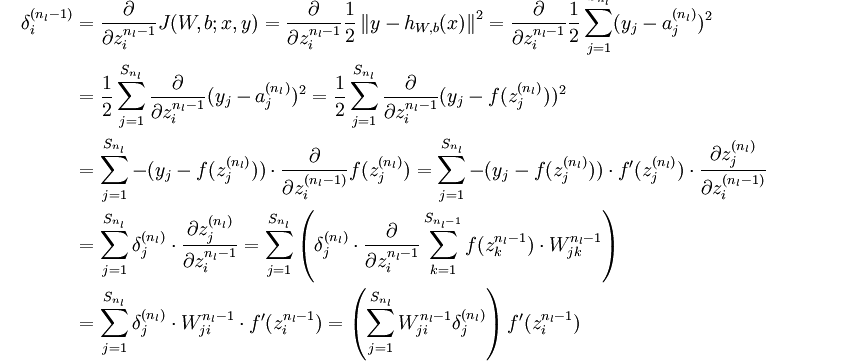
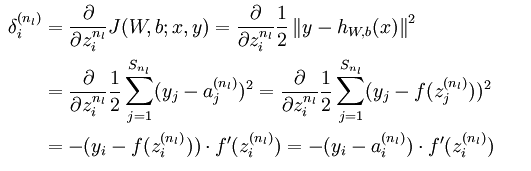















 6288
6288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









