




 本文介绍了一种利用视频信息提升语义分割精度的方法,通过预测运动矢量增加训练数据,采用label relaxation策略优化物体边缘分割,实验结果显著提升了Cityscapes、CamVid和KITTI数据集上的分割效果。
本文介绍了一种利用视频信息提升语义分割精度的方法,通过预测运动矢量增加训练数据,采用label relaxation策略优化物体边缘分割,实验结果显著提升了Cityscapes、CamVid和KITTI数据集上的分割效果。

一篇使用视频信息提升semantic segmentation 精度的工作,可以看成合理的进行data augmentation方法,文章试验做的很全面,总体来说非常扎实。文章继承了英伟达该组之前的sdc net (见本文附录)的工作。
Methodology
- 使用SDC-net 预测某片段前后k 帧图像motion vectors从而得到相应的image和label,增加了网络的训练数据。
- 物体边缘的分割历来是分割任务中比较难的地方,使用motion vectors可能存在预测不准的case更是加重了这种问题,文章缓解这种问题的方法如下图:
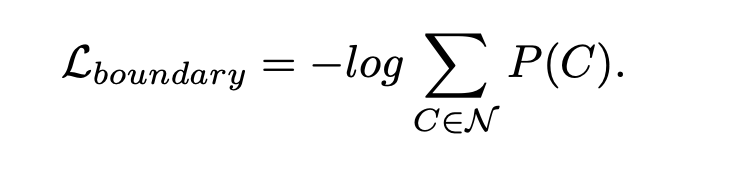
其中C是某像素周围3x3范围gt存在的种类数,直观来看softmax cross entropy中倾向于使单个类别的概率为1,本文中的label relaxation倾向于使得该像素成为相邻gt中若干类加在一起的概率为1,如果C只取一类就是标准的cross entropy,如果取全部类别相当于ignore。
文章的cityscape baseline也比较强,使用了ma’pi’llary pretrin, Class Uniform Sampling,resnext 50 的deeplab v3 val集miou 79.46%,video propagation 和label relaxation各提高接近一个点。 在camvid 和kitti这种小数据集上提升更明显。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 743
743



 到【灌水乐园】发言
到【灌水乐园】发言







