







Maybe this competition is easy to complete but it might be a good chance to practice my Caffe skill.
https://www.kaggle.com/c/digit-recognizer
1 Csv -> lmdb
http://www.cnblogs.com/dcsds1/p/5205669.html
Firstly, maybe we need to know:
train.csv.shape= (42000, 785)
test.csv.shape= (28000, 784)
#train.csv's col_index
#28*28=784
label pixel0 pixel1 ... pixel782 pixel783import
import numpy as np
import pandas as pd
import lmdb
import caffe
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_splitvisuliza a digit
path='/yourpath/'
train_path=path+'train.csv'
test_path=path+'test.csv'
train_df=pd.read_csv(train_path)#42000
test_df=pd.read_csv(test_path)#28000
train_np=train_df.values
y=train_np [:,0]
X=train_np [:,1:]
X=X.reshape((X.shape[0],1,28,28))
im1=X[10,0]
print y[10]
plt.rcParams['image.cmap']='gray'
plt.imshow(im1)
plt.show()y[10]=8

Converting…
def covert_lmdb(X,y,path):
m=X.shape[0]
map_size=X.nbytes*10#donot worry , mapsize no harm
# http://lmdb.readthedocs.io/en/release/#environment-class
env=lmdb.open(path,map_size=map_size)
# http://lmdb.readthedocs.io/en/release/#lmdb.Transaction
with env.begin(write=True) as txn:
for i in range(m):
datum=caffe.proto.caffe_pb2.Datum()
datum.channels=X.shape[1]
datum.height=X.shape[2]
datum.width=X.shape[3]
datum.data=X[i].tostring()#tobeytes if np.version.version >1.9
datum.label=int(y[i])
str_id='{:08}'.format(i)
txn.put(str_id.encode('ascii'),datum.SerializeToString())
train_lmdb_path=path+'train_lmdb'
test_score_lmdb_path=path+'test_score_lmdb'
covert_lmdb(X_train,y_train,train_lmdb_path)
covert_lmdb(X_test,y_test,test_score_lmdb_path)we get these lmdbs:

train_lmdb=301.7mb
2 Creating the net and solover
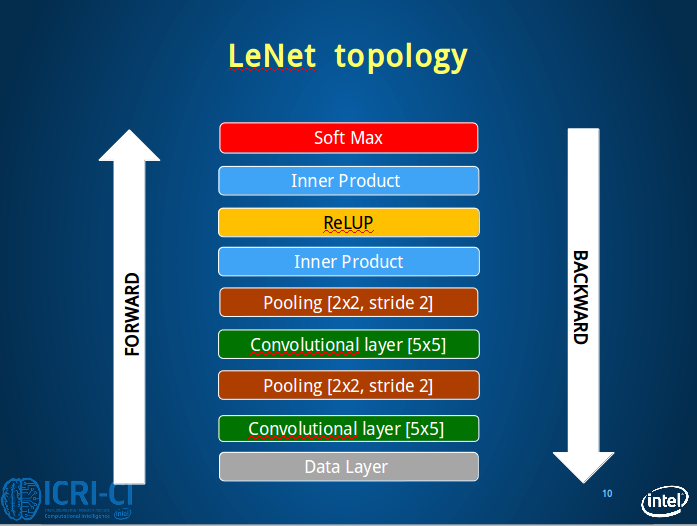
see the details:
http://blog.csdn.net/bea_tree/article/details/51601197#t14
def lenet(lmdb_path,batch_size):
n=caffe.NetSpec()
n.data,n.label=L.Data(batch_size=batch_size,backend=P.Data.LMDB,source=lmdb_path,
transform_param=dict(scale=1./255),ntop=2)
n.conv1=L.Convolution(n.data,kernel_size=5,num_output=20,weight_filler=dict(type='xavier'))
n.pool1=L.Pooling(n.conv1,kernel_size=2,stride=2,pool=P.Pooling.MAX)
n.conv2=L.Convolution(n.pool1,kernel_size=5,num_output=50,weight_filler=dict(type='xavier'))
n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.fc1=L.InnerProduct(n.pool2,num_output=10,weight_filler=dict(type='xavier'))
n.relu1 = L.ReLU(n.fc1, in_place=True)
n.score=L.InnerProduct(n.relu1,num_output=10,weight_filler=dict(type='xavier'))
n.loss=L.SoftmaxWithLoss(n.score,n.label)
return n.to_proto()
path='/media/beatree/file/note for project/work/conpetitions/kaggle/digit recognizer/data/'
train_net_path=path+'mnist/lenet_train.prototxt'
test_net_path=path+'mnist/lenet_test.prototxt'
#with open(path+'mnist/lenet_train.prototxt','w') as f:
# f.write(str(lenet(train_path,64)))
#with open(path+'mnist/lenet_test.prototxt','w') as f:
# f.write(str(lenet(test_path,64)))
from caffe.proto import caffe_pb2
def solver(train_net_path,test_net_path):
s=caffe_pb2.SolverParameter()
s.train_net=train_net_path
s.test_net.append(test_net_path)
s.test_iter.append(66)
s.test_interval=1000
s.base_lr=0.01
s.momentum=0.9
s.weight_decay=0.0005
s.lr_policy='inv'
s.gamma=0.0001
s.power=0.75
s.display=100
s.max_iter=10000
s.snapshot=5000
s.snapshot_prefix=path+'mnist/lenet'
s.solver_mode=caffe_pb2.SolverParameter.GPU
return s
#with open(path + 'mnist/solver.prototxt', 'w') as f:
# f.write(str(solver(train_net_path, test_net_path)))3 predict
path='/path/'
test_path=path+'test.csv'
prototxt_path=path+'lenet2.prototxt'
caffemodel_path=path+'mnist/lenet_5_iter_10000.caffemodel'
#caffemodel_path='/home/beatree/caffe-rc3/examples/mnist/model/lenet_iter_10000.caffemodel'
caffe.set_device(0)
caffe.set_mode_gpu()
clf=caffe.Classifier(prototxt_path,caffemodel_path,image_dims=(28,28))
test=pd.read_csv(test_path)
test_array=test.values
n=np.shape(test_array)[0]
a=[]
for i in xrange(n):
input=test_array[i,:]/255.
input=input.reshape((1,28,28,1))
reslut=clf.predict(input,oversample=False).argmax()
a.append(reslut)
ImageId=[i+1 for i in range(n)]
submit_pd=pd.DataFrame({'ImageId':ImageId,'Label':a})
submit_pd.to_csv(path+'model.csv',index=False)
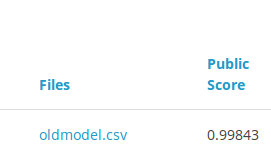
4 result
this result is created by the model which we have done in caffe example.














 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









