









首先安利一个blog,https://www.cnblogs.com/wangxiaocvpr/
这个blog写的内容涵盖计算机视觉与深度学习的很多方面,作者update的很快。
这篇文章(NIPS2016)是基于Generative Adversarial Networks (GAN)而来的,GAN有两个部分,第一部分是生成器Generator,第二部分是判别器Discriminator。Generator输入时随机变量vector(噪声), 输出是一个经过层层反卷积出来的图片。 Discriminator是一个判别器,依次输入真实的图片和generator产生的图片。Discriminator需要做到能够正确的区分两者,而generator需要做的是尽量产生足够真实的图片来混淆Discriminator。于是两个相互对抗,最后使得Generator能够从噪声中产生足够真实的图片出来,让discriminator无法区分生成的图片是real还是fake。而couple的意思就是有两个这样的GAN组合在了一起。
Abstract:
作者提出了一个coupled generative adversarial network (CoGAN) 来学习关于multi-domain images的联合分布出来。本质上GAN是学习一个图像分布p(x’)出来,这个分布要足够逼近训练样本的分布p(x)。这样的结果就是能够使我们任意输入噪声到训练好的generator中去,都能够产生一个足够像训练样本的图片出来。而这里作者将单个分布p(x)拓展到联合分布p(x,y)分布上来了。这样做的目的很深刻,因为涉及到domain adaption 问题。也就是说,在传统的domain adaption中,我们需要学习或者训练一个domain adaptor出来,而这个domain adaptor需要 用source domain和对应的target domain的训练图片来训练。而本文中的CoGAN可以无监督的学习一个联合分布。方法就是对网络加上权值共享约束,同时求解一个体育编辑分布的内积的分布解(不是很懂)。 作者测试这个CoGAN做联合分布学习的任务,包括学习图片的颜色和深度两个的联合分布,学习一个带有不同属性的联合分布出来。作者将其拓展到了domain adaption和image transformation task。
Introduction:
这篇文章考虑是从multi-domains的图片(比如图片分别来源不同的数据集(caltech 256, mnist),或者是modalitie不同的图片( color image vs depth image))。一旦我们学习好了其中一个domain的分布,就可以将其应用到生成一组新的image tuples。为了克服需要correspondence dependency这个限制,我们提出了couple GAN。这儿coupleGAN不需要训练集中包含对应的图片,而只需要在每次训练中从每个domain地边际分布中采样少量图片就可以了,这些样本不需要一一对应。COCGA 有一组GAN构成,这里选取两个GAN组成,每一个GAN针对一个image domain。 如果直接训练这两个GAN,那么导致的CoGAN是两个边际分布的内积而不是一个联合分布(p(x,y) != p(x)p(y)). 我们于是要讲CoGAN中加上一个权值共享的约束,从而使得coGAN可以在两个domain不存在corresponding images的情况下学出一个联合分布出来。同时,由于深度网络中,高层的语义信息进行权值共享的话,可以保证GAN的生成器能够解码出高层的语义信息出来。而生成器中那些解码底层细节的层可以将共性的表达变换成各自domain中不同的内容,然后可以混淆判别器。(不得不说这个idea很妙)。
Generative Adversarial Networks

Couple GAN

CoGAN的结构如图所示,由一对GAN构成,GAN1和GAN2构成,每一个针对合成各自domain的图片。在训练过程中,我们让两个GAN共享一部分参数。我们假设x1和x2是从两个domain的边际分布中采样的图片,g1和g2是GAN1和GAN2的生成器,于是可以公式化为:
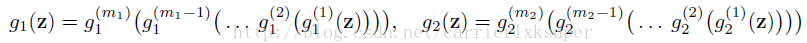
这个公式的物理意义就是说,生成模型可以逐渐的从抽象的概念出来一点点解码出具体地细节出来。因此generator的前面几层解码的是高层的语义信息,比如目标的轮廓,而后面几层解码的是细节,比如边缘。由于我们需要保证高层信息的相关性,因此我们需要g1和g2的前几个层是共享权值的。后面几层的权值就不同了,这样可以根绝高层语义信息解码出不同的细节出来,用来fool各自的判别器。
而判别器和标准的gan是一样的,公式化为:
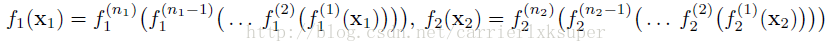
这个时候,权值共享的层就是后面几层了,因为后面几层涉及到高层的语义信息。
learning:

OK,CoGAN的精华已经讲完了,实验部分介绍一下unsupervised domain adaption (UDA)的部分:
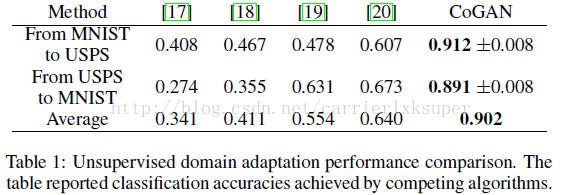
UDA 尝试解决这样一个问题,就是我们在某个domain上训练好一个分类器,然后将这个分类器adapt到另外一个domain,这个domain只有训练样本,没有label。比如说我们在mnist数据集上训练好有一个分类器,然后adapt到USPS数据集上去分类。如果直接将这个分类器去分usps,效果很差,因为domain shift。于是,我们利用domain adaption来解决这个问题。
具体而言,我们首先采集2000mnist图构成集合D1,从USPS中随机选取1800图片构成D2数据集。 CoGAN用来实现图像生成的任务。对于数字分类,我们在判别器的最后一个隐层上加上一个softmax 层。于是CoGAN的训练需要完成两个任务,一个任务是mnist的数字分类问题,因为提供了图片和对应的label。还有就是D1和D2上的图片生成问题。针对每一个domain定义有一个分类器:对于MNIST,分类器是: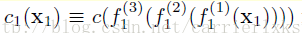
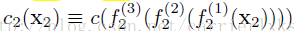
由于D2中没有label信息可以用,因此c2分类器在训练过程中没法被训练。在完成训练之后,我们利用c2来分类USPS数据集,结果如下:
作者代码链接:https://github.com/mingyuliutw/CoGAN














 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









