







 本文探讨了生成对抗网络(GANs)的基本原理,包括其训练挑战与改进技巧,以及在图像合成、分类等领域的应用。GANs通过一对竞争网络学习深层表示,无需大量标注数据。
本文探讨了生成对抗网络(GANs)的基本原理,包括其训练挑战与改进技巧,以及在图像合成、分类等领域的应用。GANs通过一对竞争网络学习深层表示,无需大量标注数据。
Generative Adversarial Networks: An Overview笔记
Abstract
Generative adversarial networks (GANs) provide a way to learn deep representations without extensively annotated training data. They achieve this by deriving backpropagation signals through a competitive process involving a pair of networks. The representations that can be learned by GANs may be used in a variety of applications, including image synthesis, semantic image editing, style transfer, image superresolution, and classification. The aim of this review article is to provide an overview of GANs for the signal processing community, drawing on familiar analogies and concepts where possible. In addition to identifying different methods for training and constructing GANs, we also point to remaining challenges in their theory and application.
Preliminaries
Terminology
Generative models learn to capture the statistical distribution of training data, allowing us to synthesize samples from the learned distribution.
We occasionally refer to fully connected and convolutional layers of deep networks; these are generalizations of perceptrons or spatial filter banks with nonlinear postprocessing. In all cases, the network weights are learned through backpropagation
Notation
- P data (x) : probability density function over a random vector x that lies in R|x|
- P g (x) : the distribution of the vectors produced by the generator network of the GAN
- G : the generator networks
- D : the discriminator networks
- ΘD and ΘG :sets of parameters (weights), learned through optimization, during training
- JG(ΘG; ΘD) and JD(ΘD; ΘG) : the objective functions of the generator and discriminator
- ▽ΘG : the gradient operator with respect to the weights of the generator parameters
- ▽ΘD : the gradient operator with respect to the weights of the discriminator
- E▽ : the expected gradients
Capturing data distributions
The difficulty we face is that likelihood functions for high-dimensional, real-world image data are difficult to construct. While GANs don’t explicitly provide a way of evaluating density functions, for a generator-discriminator pair of suitable capacity, the generator implicitly captures the distribution of the data.
Related work
- Fixed basis functions underlie standard techniques such as Fourier-based and wavelet representations.
- Data-driven approaches to constructing basis functions can be traced back to the Hotelling transform, rooted in Pearson’s observation that principal components minimize a reconstruction error according to a minimum squared error criterion.
- the bases of PCA may be derived as a maximum likelihood parameter estimation problem.(PCA have both a shallow and a linear mapping, limiting the complexity of the model and, hence, of the data, that can be represented.PCA模型复杂度有限)
- Independent component analysis (ICA)(比PCA稍微复杂一些)
ICA has various formulations that differ in their objective functions used during estimating signal components or in the generative model that expresses how signals or images are generated from those components. A recent innovation explored through ICA is noise contrastive estimation (NCE); this may be seen as approaching the spirit of GANs : the objective function for learning independent components compares a statistic applied to noise with that produced by a candidate generative model
GAN与这些标准信号处理工具的区别在于:将矢量从潜在空间映射到图像空间的模型的复杂程度。由于生成网络包含非线性,并且几乎可以任意深度,因此这种映射 - 与许多其他深度学习方法一样 - 可以非常复杂。
对于基于深度图像的模型,可以将现有的生成图像建模方法分组为显式和隐式密度模型。显式密度模型要么tractable(变量模型的变化,自回归模型),要么intractable(用变分推理训练的定向模型,使用马尔可夫链训练的无向模型)。隐式密度模型通过生成过程捕获数据的统计分布,该过程利用原始采样法或基于马尔可夫链的采样。 GAN属于定向隐式模型类别。
GAN architectures
Fully connected GANs
The first GAN architectures used fully connected neural networks for both the generator and discriminator.
Convolutional GANs
Laplacian pyramid of adversarial networks (LAPGAN)
decompose the generation process using multiple scales: a ground-truth image is itself decomposed into a Laplacian pyramid and a conditional, convolutional GAN is trained to produce each layer given the one above.
deep convolutional GAN (DCGAN)
allows training a pair of deep convolutional generator and discriminator networks.
volumetric convolutions
synthesize three-dimensional (3-D) data samples
present a method map from two-dimensional (2-D) images to 3-D versions of objects portrayed in those images.
Conditional GANs
Conditional GANs have the advantage of being able to provide better representations for multimodal data generation.
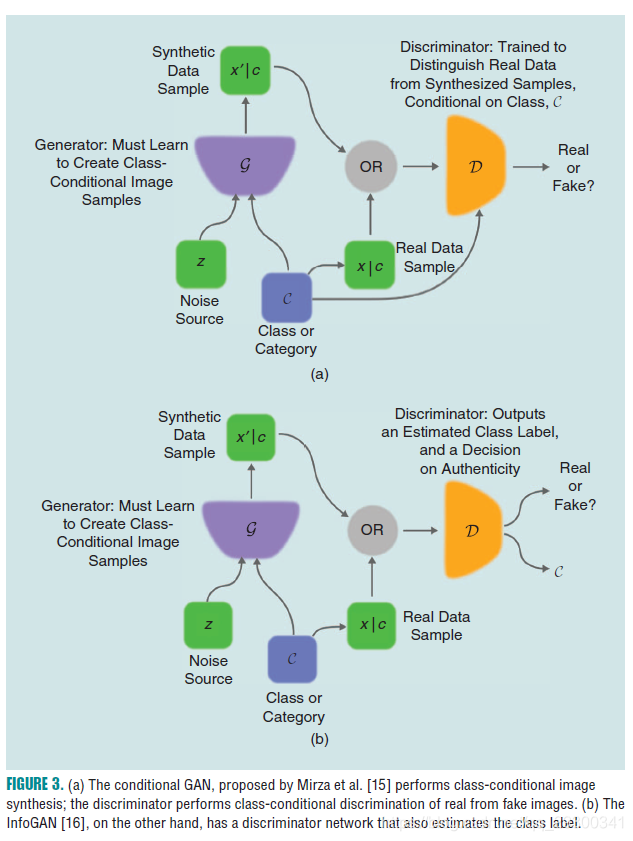
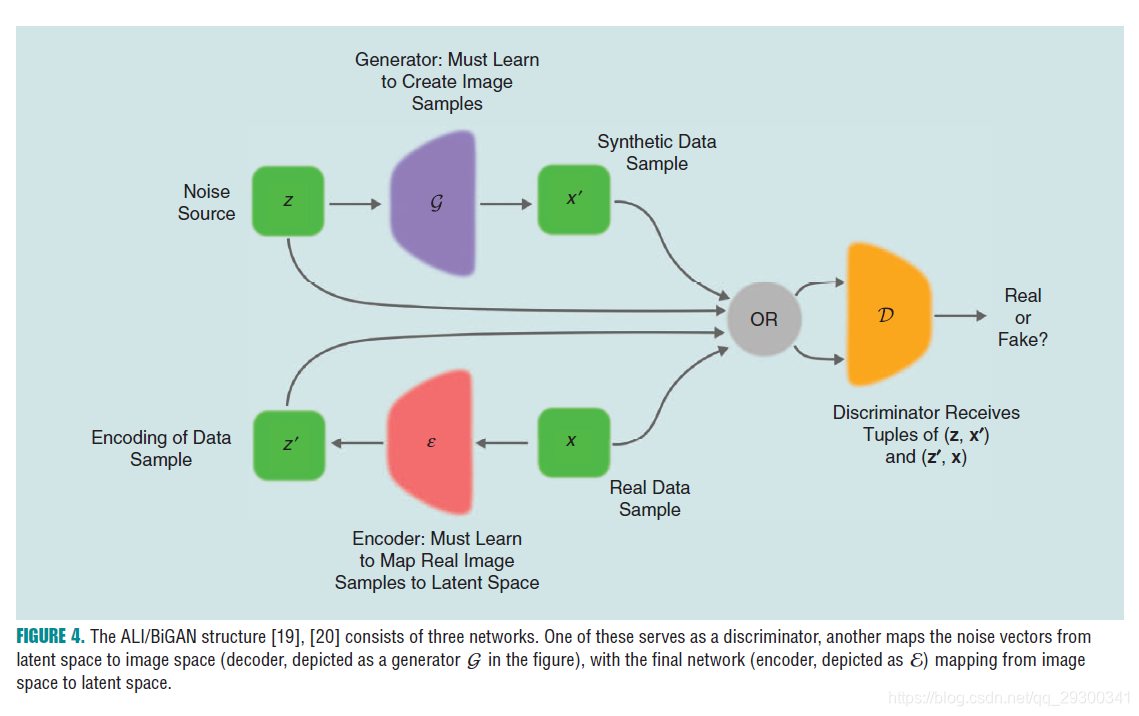
GANs with inference models
In GANs original formulation, they lacked a way to map a given observation, x, to a vector in latent space—in the GAN literature, this is often referred to as an inference mechanism.
Inference models introducing an inference network in which the discriminators examine joint (data, latent) pairs.
Adversarial autoencoders
Autoencoders are networks, composed of an encoder and decoder, which learn to map data to an internal latent representation and out again.
Learn a deterministic mapping (via the encoder) from a data space, e.g., images, into a latent or representation space, and a mapping (via the decoder) from the latent space back to data space.
自动编码器让人联想到在图像和信号处理中被广泛使用的完美重构滤波器组。
Training GANs
Introduction
The training of GANs involves both finding the parameters of a discriminator that maximize its classification accuracy and finding the parameters of a generator that maximally confuse the discriminator.
One approach to improving GAN training is to asses the empirical “symptoms” that might be experienced during training. These symptoms include:
- difficulties in getting the pair of models to converge
- the generative model “collapsing” to generate very similar samples for different inputs
- the discriminator loss converging quickly to zero, providing no reliable path for gradient updates to the generator.
Arjovsky et al. showed that the support Pg (x) and Pdata (x) lie in a lower-dimensional space than that corresponding to X. The consequence of this is that Pg (x) and Pdata (x) may have no overlap, and so there exists a nearly trivial discriminator that is capable of distinguishing real samples, x~Pdata (x) from fake samples, x~Pg (x) with 100% accuracy.
If D is not optimal, the update may be less meaningful or inaccurate.
Training tricks
One of the first major improvements in the training of GANs for generating images were the DCGAN architectures proposed by Radford et al.
- strided and fractionally strided convolutions
- batch normalization was recommended for use in both networks to stabilize training in deeper models
- Another suggestion was to minimize the number of fully connected layers used to increase the feasibility of training deeper models.
- using leaky rectifying linear units (ReLUs) activation functions between the intermediate layers of the discriminator gave superior performance over using regular ReLUs.
Later, Salimans et al. proposed further heuristic approaches for stabilizing the training of GANs.
- The first, feature matching, changes the objective of the generator slightly to increase the amount of information available.(the discriminator is still trained to distinguish between real and fake samples, but the generator is now trained to match the discriminator’s expected intermediate activations (features) of its fake samples with the expected intermediate activations of the real samples)
- The second, minibatch discrimination, adds an extra input to the discriminator, which is a feature that encodes the distance between a given sample in a minibatch and the other samples. This is intended to prevent mode collapse, as the discriminator can easily tell if the generator is producing the same outputs.
- A third trick, heuristic averaging, penalizes the network parameters if they deviate from a running average of previous values, which can help convergence to an equilibrium.
- The fourth, virtual batch normalization, reduces the dependency of one sample on the other samples in the minibatch by calculating the batch statistics for normalization with the sample placed within a reference minibatch that is fixed at the beginning of training.
- Finally, one-sided label smoothing makes the target for the discriminator 0.9 instead of one, smoothing the discriminator’s classification boundary, hence preventing an overly confident discriminator that would provide weak gradients for the generator.adding noise to the samples before feeding them into the discriminator
In practice, this can be implemented by adding Gaussian noise to both the synthesized and real images, annealing(退火) the standard deviation over time.
Alternative formulations
**Generalizations of the GAN cost function **
- Nowozin et al. showed that GAN training may be generalized to minimize not only the JS divergence, but an estimate of f-divergences; these are referred to as f-GANs.
- Uehara et al. extend the f-GAN further, where in the discriminator step the ratio of the distributions of real and fake data are predicted, and in the generator step the f-divergence is directly minimized.
** Alternative cost functions to prevent vanishing gradients **
- Wasserstein GAN (WGAN), a GAN with an alternative cost function that is derived from an approximation of the Wasserstein distance.
- WGAN is more likely to provide gradients that are useful for updating the generator
- Gulrajani et al. proposed an improved method for training the discriminator for a WGAN, by penalizing the norm of discriminator gradients with respect to data samples during training, rather than performing parameter clipping.(weight clipping adversely reduces the capacity of the discriminator model, forcing it to learn simpler
functions.)
A brief comparison of GAN variants
- 由于“梯度消失”,GAN模型很难训练,本文中adversarial autoencoder (AAE) 和 WGAN 相对容易训练。
- GAN 和 WGAN 训练出来的样本可能属于“训练集”中的任何一种Conditional GANs可以训练用户指定类别的样本。
- 隐藏层的向量包含着含义,可以用于可视化。BiGANs和ALI提供了将图片对应到隐藏层的机制(inference)
The structure of latent space
GAN的“隐藏层”构建了数据的representation,“生成器”末尾的隐藏层“highly structured”,支持high-level semantic operations。
Examples include the rotation of faces from trajectories through latent space, as well as image analogies that have the effect of adding visual attributes such as eyeglasses onto a “bare” face.
Encoder可以用于反向mapping,探索向量每一部分的含义。
Many GAN models have an encoder that additionally supports the inverse mapping.
With an encoder, collections of labeled images can be mapped into latent spaces and analyzed to discover
“concept vectors” that represent high-level attributes such as “smiling” or “wearing a hat.” These vectors can be applied at scaled offsets in latent space to influence the behavior of the generator.
Applications of GANs
- Classification and regression
- Image synthesis
- Image-to-image translation
- Superresolution
Discussion
1、Mode collapse
只生成很多相似的样本
- 平衡样本分布,或者用多个GAN来覆盖的不同概率分布
- 让“鉴别器”先多更新几步,然后用更新后的“鉴别器”来更新“生成器”unrolling the discriminator for several steps.letting it calculate its updates on the current generator for several steps, and then using the “unrolled” discriminators to update the generator using the normal minimax objective.
2、Training instability—saddle points
- 在GAN中,损失函数的Hessian是不确定的,因此最好是找到“鞍点”而不是“局部最小值”。而收敛到GAN的鞍点需要良好的初始化(如果我们随机选择优化器的初始点,则梯度下降不会收敛到概率为1的鞍点)
- 在一定容量以下,可能不存在均衡
3、Evaluating generative models
不同GAN的质量评估方法会导致相互矛盾,最好是根据“具体应用场景”,选择评估方式
Conclusions
The explosion of interest in GANs is driven not only by their potential to learn deep, highly nonlinear mappings from a latent space into a data space and back but also by their potential to make use of the vast quantities of unlabeled image data that remain closed to deep representation learning. Within the subtleties of GAN training, there are many opportunities for developments in theory and algorithms, and with the power of deep networks, there are vast opportunities for new applications.

















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









