









 本文介绍在虚幻引擎4中实现内存追踪功能的过程和技术细节。涵盖了内存分配方法、API使用、容器跟踪、作用域定义等内容。
本文介绍在虚幻引擎4中实现内存追踪功能的过程和技术细节。涵盖了内存分配方法、API使用、容器跟踪、作用域定义等内容。
本文章由cartzhang编写,转载请注明出处。 所有权利保留。
文章链接:http://blog.csdn.net/cartzhang/article/details/50524317
作者:cartzhang
本篇译文同发与蛮牛译馆,
地址:http://www.manew.com/thread-46327-1-1.html?_dsign=ae91354a
从我上次谈论内存申请和跟踪已经有一段时间了。我得抽出时间来在虚幻4上实现跟踪,并且已经完成了。我假设你已经阅读过来之前的博客:“虚幻引擎4中内存跟踪功能的局限性”和“内存申请和跟踪”。
虚幻引擎4内存管理的API
基本的内存分配方法。
虚幻引擎4中,有三种基本的内存分配和释放方法:
1.使用GMalloc指针。这种方法是获得全局的分配器,分配器的使用依赖于GCreateMalloc()函数。
2.FMemory函数。有静态函数比如:Malloc(),Realloc(),Free()。他们也是使用GMalloc来申请内存,但是在此之前,它会在每次allocation, reallocation或free之前检查GMalloc 是否定义。若GMalloc 是空,就调用GCreateMalloc() 。
3.全局的的New和delete操作。缺省情况下,只在模块的ModuleBoilerplate.h 的文件中定义,也就是说,很多调用new和delete的操作不在虚幻4的内存系统中管理。重载操作实际上调用的是FMemory函数。
这些情况就会出现使用这些机制就可能出现内存不会释放和清空的问题。为了扑捉这些问题,我提交了一个申请,已经被整合并发布在版本4.9上,通过C运行时库调用_CrtSetAllocHook()来获取这些分配。其中一个例子,是引擎中Zlib集成并没有使用引擎工具来分配,它使用了_CrtSetAllocHook() ,我提交了一个修复版本在4.9版本发布。
直接调用GMalloc 和FMemory 函数这两个基础的API,如下:
virtual void* Malloc( SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT ) = 0;
virtual void* Realloc( void* Original, SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT ) = 0;
virtual void Free( void* Original ) = 0;
These are the places that would need to be modified if we want to add any new piece of data per allocation.
引擎的整合
为了写法类似,我重载了分配器,我从FMalloc继承了一个新类,叫做FMallocTracker,这样就可以勾到虚幻的内存分配系统上。因为一个有效的分配器必须在创建FMallocTracker 实例时所有实际的分配已经由其分配器完成。FMallocTracker 只是保存了跟踪信息。但是这是不够的,实际上需要知道分配器所有方法来跟踪数据。因此,第一步就是当我们使用内存跟踪功能时,修改分配器函数。
#if USE_MALLOC_TRACKER
virtual void* Malloc( SIZE_T Count, uint32 Alignment, const uint32 GroupId, const char * const Name ) = 0;
virtual void* Realloc( void* Original, SIZE_T Count, uint32 Alignment, const uint32 GroupId, const char * const Name ) = 0;
#else
virtual void* Malloc( SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT ) = 0;
virtual void* Realloc( void* Original, SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT ) = 0;
#endif // USE_MALLOC_TRACKER
新参数:
名称:分配名称。这个名称可以任何名称,但是建议写易懂便于搜索。在本文后面,将会展示更多相关内容。
分组:组ID是针对于当前所分配的。有些分组我已经定义过来,但是有些你需要根据你的需要来定义。
这个改变就意味着,所有的分配器在引擎中都是透明的,一旦完成,你可以标记分配器,而不用担心底层的实现。标记分配的目的不仅仅是为了跟踪,也涉及到代码调试。一旦这些便签在很大的代码库中实现后,当内存飙升,处理不同组的交互,修复相关的内存崩溃时,就会有很大的好处了。
下一步是集成new和delete操作。我之前提到过,在引擎的ModuleBoilerplate.h文件中已经定义好,为了更好的的覆盖,我把它移动到MemoryBase.h中。下一步是定义新的重载操作,并传入名称和分组。
OPERATOR_NEW_MSVC_PRAGMA FORCEINLINE void* operator new (size_t Size, const uint32 Alignment, const uint32 GroupId, const char * const Name) OPERATOR_NEW_NOTHROW_SPEC{ return FMemory::Malloc(Size, Alignment, GroupId, Name); }
OPERATOR_NEW_MSVC_PRAGMA FORCEINLINE void* operator new[](size_t Size, const uint32 Alignment, const uint32 GroupId, const char * const Name) OPERATOR_NEW_NOTHROW_SPEC{ return FMemory::Malloc(Size, Alignment, GroupId, Name); }
OPERATOR_NEW_MSVC_PRAGMA FORCEINLINE void* operator new (size_t Size, const uint32 Alignment, const uint32 GroupId, const char * const Name, const std::nothrow_t&) OPERATOR_NEW_NOTHROW_SPEC { return FMemory::Malloc(Size, Alignment, GroupId, Name); }
OPERATOR_NEW_MSVC_PRAGMA FORCEINLINE void* operator new[](size_t Size, const uint32 Alignment, const uint32 GroupId, const char * const Name, const std::nothrow_t&) OPERATOR_NEW_NOTHROW_SPEC { return FMemory::Malloc(Size, Alignment, GroupId, Name); }为避免使用USE_MALLOC_TRACKER来进行检测,提供这些定义来创建这些申请,在使用USE_MALLOC_TRACKER设置,但当不设置时并不增加不必要的开销。其目的是不增加任何不必要的开销。下面是基本定义:
#if USE_MALLOC_TRACKER
#define PZ_NEW(GroupId, Name) new(DEFAULT_ALIGNMENT, (Name), (GroupId))
#define PZ_NEW_ALIGNED(Alignment, GroupId, Name) new((Alignment), (Name), (GroupId))
#define PZ_NEW_ARRAY(GroupId, Name, Type, Num) reinterpret_cast<##Type*>(FMemory::Malloc((Num) * sizeof(##Type), DEFAULT_ALIGNMENT, (Name), (GroupId)))
#define PZ_NEW_ARRAY_ALIGNED(Alignment, GroupId, Name, Type, Num) reinterpret_cast<##Type*>(FMemory::Malloc((Num) * sizeof(##Type), (Alignment), (Name), (GroupId)))
#else
#define PZ_NEW(GroupId, Name) new(DEFAULT_ALIGNMENT)
#define PZ_NEW_ALIGNED(Alignment, GroupId, Name) new((Alignment))
#define PZ_NEW_ARRAY(GroupId, Name, Type, Num) reinterpret_cast<##Type*>(FMemory::Malloc((Num) * sizeof(##Type), DEFAULT_ALIGNMENT))
#define PZ_NEW_ARRAY_ALIGNED(Alignment, GroupId, Name, Type, Num) reinterpret_cast<##Type*>(FMemory::Malloc((Num) * sizeof(##Type), (Alignment)))
#endif // USE_MALLOC_TRACKER下面是两个例子,说明在代码中,带标签和不带标签内存分配的比较:
分配器的跟踪由容器来完成
在命名分配空间时出现了一个问题,用一个简单方法来识别,我们使用容器来处理。引擎中所有对象几乎不可能只有一个单例,在做游戏时,可放置的例子,几个玩家,所以引擎中使用很多容器。在使用带容器的分配器时,使用一个通用的名字是没有什么用处的。我们来看看这个FMeshParticleVertexFactory::DataType例子:


/** The streams to read the texture coordinates from. */
TArray<FVertexStreamComponent,TFixedAllocator<MAX_TEXCOORDS> > TextureCoordinates;在容器中,一个普通的名字分配器类似于“TFixedAllocator::ResizeAllocation”。没有太多意义。反之,对于容器来说,一个好的名字像这样“FMeshParticleVertexFactory::DataType::TextureCoordinates”。因此,我们需要给容器标记名称和分组,如此以来,当一个分配器在容器中后,通过容器的名称和分组获得所有的内存分配。因此,我们需要改变容器,让分配器额可以使用这些容器。这将涉及到当使用USE_MALLOC_TRACKER时,需要为每个容器添加指针和一个32位的无符号整数,并修改必要的构造函数来添加选项信息。TArray的一个构造函数如下:
TArray(const uint32 GroupId = GROUP_UNKNOWN, const char * const Name = "UnnamedTArray")
: ArrayNum(0)
, ArrayMax(0)
#if USE_MALLOC_TRACKER
, ArrayName(Name)
, ArrayGroupId(GroupId)
#endif // USE_MALLOC_TRACKER
{}这样以来,我们可以把必要的信息传递给分配器来标记这些分配。接下来是要保证把这些改变信息传递到底层内存分配器中被使用。这些容器分配器通常使用FMemory来分配内存,FContainerAllocatorInterface定义ResizeAllocation 函数来做实际的内存申请。与之前的修改一样,我们需要为内存分配添加名称和分组。
#if USE_MALLOC_TRACKER
void ResizeAllocation(int32 PreviousNumElements, int32 NumElements, SIZE_T NumBytesPerElement, const uint32 GroupId, const char * const Name);
#else
void ResizeAllocation(int32 PreviousNumElements, int32 NumElements, SIZE_T NumBytesPerElement);
#endif // USE_MALLOC_TRACKER同样,因为我们不想使用那个ifdefs来填充引擎的代码,我们再次使用定义来简化:
#if USE_MALLOC_TRACKER
#define PZ_CONTAINER_RESIZE_ALLOCATION(ContainerPtr, PreviousNumElements, NumElements, NumBytesPerElement, GroupId, Name) (ContainerPtr)->ResizeAllocation((PreviousNumElements), (NumElements), (NumBytesPerElement), (GroupId), (Name))
#else
#define PZ_CONTAINER_RESIZE_ALLOCATION(ContainerPtr, PreviousNumElements, NumElements, NumBytesPerElement, GroupId, Name) (ContainerPtr)->ResizeAllocation((PreviousNumElements), (NumElements), (NumBytesPerElement))
#endif // USE_MALLOC_TRACKER这样,我们可以把ArrayName和ArrayGroup传递给容器分配器。
在构造之后,还有一个需要修改容器的名称或分组,因为给容器的容器命名分配器是非常有必要的。其中的一个例子就是,在任一TMap容器中FindOrAdd后,我们需要设置名称或分组。
/** Map of object to their outers, used to avoid an object iterator to find such things. **/
TMap<UObjectBase*, TSet<UObjectBase*> > ObjectOuterMap;
TMap<UClass*, TSet<UObjectBase*> > ClassToObjectListMap;
TMap<UClass*, TSet<UClass*> > ClassToChildListMap;这样以来,所有的容器内存分配器有了标签属性。现在,我们需要的是给容器设置名称。以FMeshParticleVertexFactory::DataType::TextureCoordinates为例,我们可以设置它的名称和分组:
DataType()
: TextureCoordinates(GROUP_RENDERING, "FMeshParticleVertexFactory::DataType::TextureCoordinates")
, bInitialized(false)
{
}定义作用域
作为“内存申请和跟踪”博客中一部分,为提供上下文链接,我提及到内存分配定义作用域的必要性。这个作用域与调用栈(它已经由MallocProfiler提供)不一样。很多分配在同一栈中,但是涉及到完全不同的对象。在使用蓝图过程中更是普遍。正是由于这个,作用域在跟踪或甚至带蓝图的内存使用都是非常有用的。
为利用引擎中已有的代码,我采用了重用FScopeCycleCounterUObject 结构体的方法,这个结构体用来在状态系统中定义作用域的相关对象。引擎已经给他们配置了必要的作用域,并且你也可以使用FMallocTrackerScope 类来放置我们的内存跟踪特性的作用域。也在每个FScopeCycleCounterUObject上自动创建的两个域的可见性上做了改进,一个是对象类名的域,一个是对象名的域。这样当我们最终创建一个可视数据工具时,对每个类名进行折叠时就会更简单。让我们从精灵Demo来看一看单独作用域,它是一个感觉还不错的复杂东西。
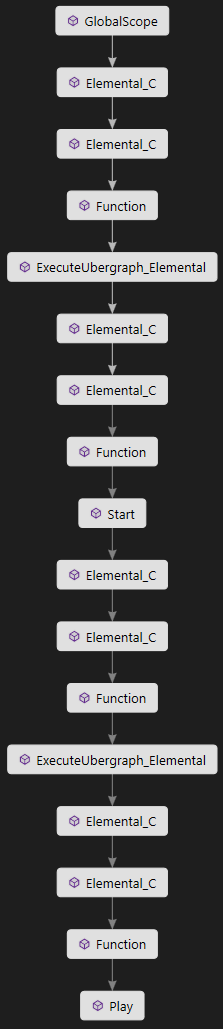
我们分析作用域下的内存分配,结果如下:
Address Thread Name Group Bytes Name
0x0000000023156420 Main Thread UObject 96 InterpGroupInst
0x00000000231cf000 Main Thread Unknown 64 UnnamedTSet
0x0000000023168480 Main Thread UObject 80 InterpTrackInstMove
0x0000000028ee8480 Main Thread Unknown 64 UnnamedTSet
0x0000000022bc2420 Main Thread Unknown 32 UnnamedTArray
0x00000000231563c0 Main Thread UObject 96 InterpGroupInst
0x00000000231cefc0 Main Thread Unknown 64 UnnamedTSet
0x0000000023168430 Main Thread UObject 80 InterpTrackInstMove
0x00000000231cef80 Main Thread Unknown 64 UnnamedTSet
0x0000000022bc2400 Main Thread Unknown 32 UnnamedTArray
0x0000000023156360 Main Thread UObject 96 InterpGroupInst
0x00000000231cef40 Main Thread Unknown 64 UnnamedTSet
0x00000000231683e0 Main Thread UObject 80 InterpTrackInstMove
0x0000000028ee8380 Main Thread Unknown 64 UnnamedTSet
0x0000000022bc23e0 Main Thread Unknown 32 UnnamedTArray
0x00000000231cef00 Main Thread UObject 64 InterpTrackInstAnimControl
0x00000000231ceec0 Main Thread UObject 64 InterpTrackInstVisibility
在蓝图的运行函数中只有17个内存分配。当我扑捉精灵Demo中实际的内存分配数为584454。唯一名称的作用域数量高达4175。还有我们在捕捉时的内存分配为607M,而内存峰值为603M。这说明了对于这些需要内存跟踪的必要性。
MallocTracker的实现
正如之前所说,MallocTracker 的使用方法与之前内存分配很相似。MallocTracker 是轻量级的,并且依据在“内存分配和跟踪”文章中所说的性能需求。
使用方法在缺省状态下是足够快的,不会有太多的性能影响,并在内存方面有相当地的开销。例如元素Demo显示跟踪开销~30M,在Debug模式下CPU时间低于2ms,更不用说在优化发布版本下了。与平时一样,在内存消耗和性能之前有个取舍,这些数字取决于我所选取的方法。还有其他的方法,可以优化性能或内存开销,但是我想还是保持合理的平衡。
为分析应用,我们来看一个具体的例子。下面是当 FMemory::Malloc()调用时所发生的:
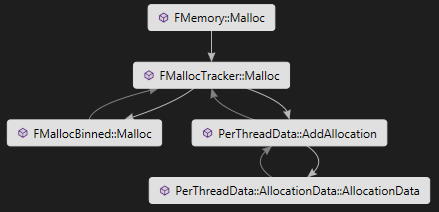
1.
FMemory::Malloc() 被调用,名字和分组需要一定的字节分配。
2.
FMemory::Malloc()调用带同样参数的FMallocTracker::Malloc(),假设GMalloc指针指向的是FMallocTracker 的实例。
3.
FMallocTracker::Malloc()在FMallocTracker创建期间,使用传进来的分配器分配实际的内存,本例中是FMallocBinned类。
4.
FMallocTracker::Malloc() 自动修改一些全局内存分配状态,例如内存分配峰值内存大小,内存峰值数等等。
5.
FMallocTracker::Malloc()关联到当前线程PerThreadData 实例。
6.
FMallocTracker::Malloc() 调用PerThreadData::AddAllocation来保存在此线程容器中的的内存分配数据。
7.
FMallocTracker::Malloc() 返回指针给步骤三中的底层内存分配器。
全局静态
几乎不包含全局状态。只是给你一个快速的概览而已。全局状态包括:
分配的字节。数据入栈时分配字节数。
分配次数。数据入栈时分配次数。数越大就会有更多的内存碎片。
分配字节的峰值。从MallocTracker 可用以后的最大字节分配数。
内存分配峰值次数。从MallocTracker 可用后,实时分配的最大数。
消耗字节。MallocTracker 的内部开销字节数。
从所有线程分配内存开始,所有这些状态自动更新。
各线程的数据
为提高性能和避免多线程下内存分配和释放的资源竞争,大部分工作在每个线程基础中完成。所有内存分配和栈的作用域范围被存储在每个线程中。所有分配有一个相对的栈域定义,最大域范围为GlobalScope。同样的域名常出现在多域栈中。由此,为最小化内存开销,某个线程的所有域名被存储为独一无二的,并关联到域的栈上。因为域栈可以在多个内存分配中显示,所有我们可以独一无二的保存在域栈上。我们来看具体的例子,域名为蓝色,分配器为桔黄色:
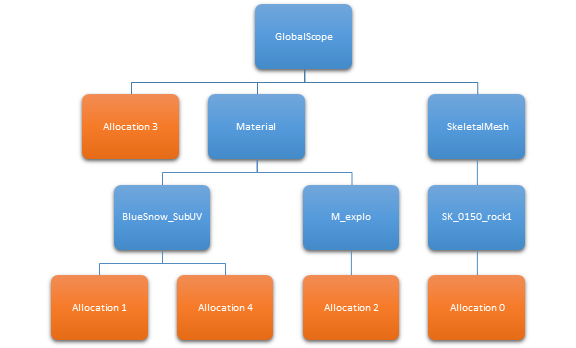
为保存数据,我们有三个不同的数组,它们在不同线程中不共享:
唯一域名。保存本线程中唯一域名。至少GlobalScope 要在这里。它将会保存它们加入到栈中的新的域名。
唯一的域栈。它用一个固定长度的动态数组保存唯一栈,用索引指向相关的域名。
分配器。每个分配器的数据。它包含分配器地址,字节大小,分组和名称,还有唯一域栈的索引。
若我们参考之前的图,我们可以看到五个分配器。下面为5个分配器的数据存储:
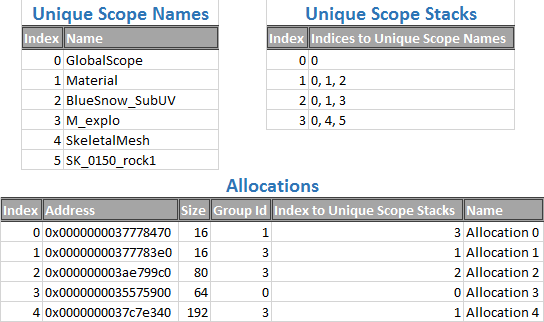
重新分配和释放内存
重新分配内存和释放内存有点复杂,因为实际上在虚幻引擎中在一个线程中分配多个实例,然后被重新分配或在其他线程释放或是很普遍的。也就是说,我们不能假设我们找到每个调用线程上的每个线程数据。因为那样的话,也就意味着我们需要加一些锁。为减少竞争,使用全局锁而不是每个线程数据类有自己的锁。在重新分配和释放当前调用线程的每个线程数据时,对当前存在分配器进行检测。若没有找到,当前分配器在其他线程数据中在处理中被锁定了。这用来确保减少竞争,并让它们尽可能的忙碌。
命名的处理
为使MallocTracker足够快和内存消耗可被接受,我不得不制定严格的命名规范,无论是分配内存或域名命名。这种限制是,这些名字与内存的生命周期内,必须一致或比实际申请或域的存在时间要长。原因是,任何数据拷贝影响性能和内存开销,所以只保存指针。虽然这貌似是一个复杂的规则,我觉得这个是完全正常的,因为你应该知道你分配器的生命周期。若你不知道你分配器的生命周期,为要知道这些名字要存在多久,那么你有了大麻烦处理了。
另外一个关于分配器和域名的特别应用是需要ANSI和宽字节。为使这些更透明,所有指针假定为ANSI,除非指针中的第63位字节被设置,它会假定指针指向一个宽字节。FMallocTracker提供了一个获取为宽字节设置位的指针操作方法,并对宽字节或ANSI的FNames在必要情况下可设置。在输出到文件时,名字是正确的并转存到文件中。
结论
只有当制作了一个可视的工具来展示数据时,我才会说这个系统真的很有用啊!你可以继续我的工作,它真的很有用。查找碎片问题和处理内存使用使用这个数据会更加简单。这个真的比引擎中已经提供的性能工具,内存消耗和数据质量要好。
下一步将真正全面转换引擎使用标签内存分配,但是仍有事情必须完成。若大部分内存没有冲突,真的没有必要花费太多时间来只是为了标记内存分配。它不只是更好标记大的内存分配,而是获取更多的洞察细节的问题。尽管你会觉得标记分配器非常无聊,但是你仍会获得有用的数据。下面是精灵Demo中截取的最大分配器的数据:
样例数据和源代码
为说明问题,我提供了样例数据。样例数据来自测试版本的精灵Demo的修改版本的运行。你可以在这里下载,在支持大文件的文本编辑器中打开。
若Epic Game 接受了我的代码更新请求,你可以通过下载我上传请求到Epic Games的代码来查看。上传请求的有效地址:虚幻4上传请求地址。
Video overview.
视频概述
[译者注:28分钟的视频,有需要的可以下!]
原文地址:https://pzurita.wordpress.com/2015/08/26/adding-memory-tracking-features-to-unreal-engine-4/
-THE—END–
若有问题,请随时联系!!!
非常感谢!!!

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









