







抓取的网页https://movie.douban.com/review/best/
Python源码:
import sys
import requests
import time
url='https://movie.douban.com/review/best/'
data=requests.get(url) #用requests爬取整个页面
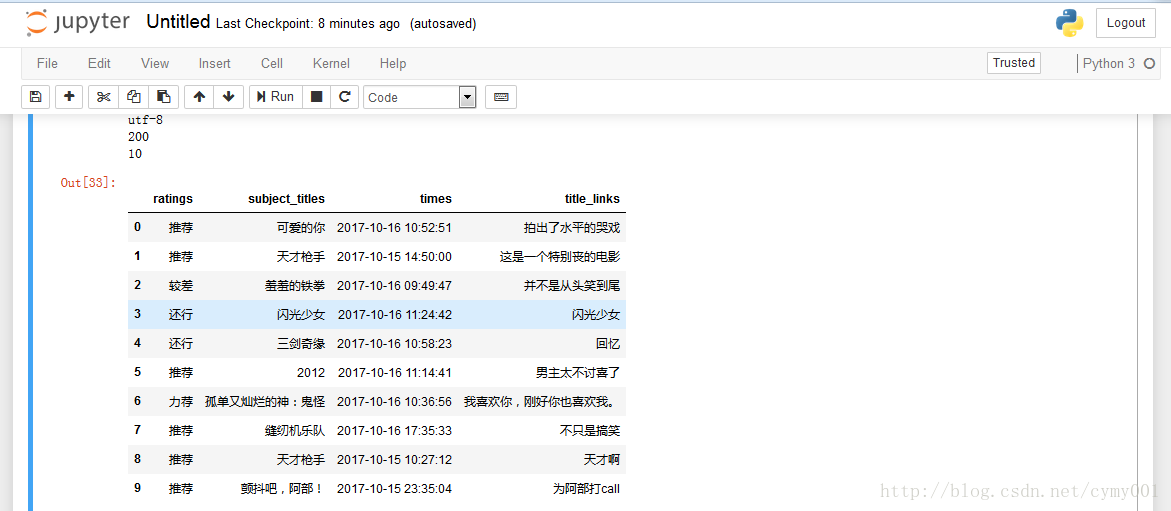
print(data.encoding)
print(data.status_code)
from lxml import etree
selector=etree.HTML(data.text) #用lxml.etree对爬取的页面进行解析
# 存储解析到的内容
title_links=[] #评论主题
subject_titles=[] #电影名字
ratings=[] #评星
times=[] #评论时间
comments=selector.xpath('//*[@id="content"]/div/div[1]/div[1]/div')
#“*”可以代替所有的节点名,HTML文档里copy XPATH查看定位xml字段,小技巧(查看同等级类别的xpath取定位符)
print(len(comments)) #comments是一个列表
for comment in comments:
title_link=comment.xpath('.//header/h3/a/text()')[0]
##html:<a href="https://movie.douban.com/review/8868602/" class="title-link">拍出了水平的哭戏</a>
subject_title=comment.xpath('.//header/div/a[2]/text()')[0]
##html:<a class="subject-title" href="https://movie.douban.com/subject/25870236/">可爱的你</a>
rating=comment.xpath('.//header/div/span[1]/@title')[0]
##html:<span class="allstar40 main-title-rating" title="推荐"></span>
time=comment.xpath('.//header/div/span[3]/text()')[0]
##html:<span property="v:dtreviewed" content="2017-10-16" class="main-meta">2017-10-16 10:52:51</span>
title_links.append(title_link)
subject_titles.append(subject_title)
ratings.append(rating)
times.append(time)
comment_dict={'title_links':title_links,'subject_titles':subject_titles,'ratings':ratings,'times':times}
import pandas as pd
comment_df=pd.DataFrame(comment_dict)#'contents'
comment_df抓取结果:















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









