









放完暑假回到实验室,tensorflow的代码已经忘得都差不多了。因此急需要对以前的代码进行复习,并且对未来一段时间的方向进行安排。在github上有一篇使用了最近几年深度学习常用模型,来做文本分类的例子。是作者brightmart参加知乎“看山杯”数据竞赛的各种模型的baseline的代码,因此拿来做以后这段时间学习的规划。下面是这个开源项目所用模型:
专栏里实现过使用char-CNN和char-RNN来做文本分类,TextCNN和TextRNN实际上和基于字符的文本分类过程差不多,数据处理阶段比基于字符的还要简单,所以不再单独实现。fastText模型更是极致的简单,这里也不再单独实现。模型4和模型5是下一阶段的主要实现目标。这篇文章主要讲加入attention模块的层次RNN,想法来自于论文Implementation of Hierarchical Attention Networks for Document Classification。代码已经上传至github。
Attention机制来自于论文 NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE,最早提出是在机器翻译领域,这里引用该论文的插图来简要介绍attention机制的思想。
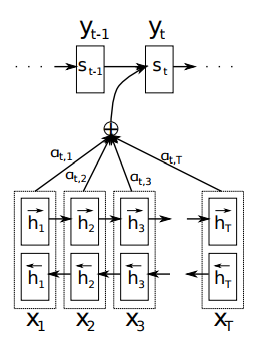
在上图中,
xT
代表的是源语言的一个词,
yt
代表的是目标语言的一个词。在得到翻译目标词
yt
的过程中,翻译结果取决于
yt
的上一个词
yt−1
和源语言的词
x1−−xT
的表示。比如,源语言为”I love you” 翻译为“我/爱/你”,在把翻译结果为”你”的过程中,起重要作用的是单词“you”而与”I love”无关,所以attention机制就是给源语言的词
x1−−xT
表示赋予权重
α
,以代表在翻译过程中,每个单词起的不同作用。
具体到Hierarchical Attention Networks文本分类的项目,框架可以分为四层,从下到上依次为:word encoder,word attention, sentence encoder, sentence attention。
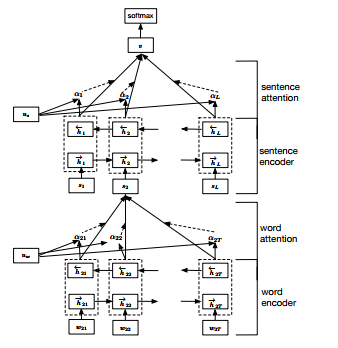
在拿到一个新的论文以后,主要应该考虑两个问题:1、数据怎么处理?2、模型怎么训练?那我们首先解决第一个问题。
数据处理
首先说明数据集,yelp的review数据。大规模的数据可以在官网上下载,压缩数据大概2GB左右,还有一个较小规模的数据集,大概200M+,适用于我们进行练手。这里采用第二个数据,将yelp_academic_dataset_review.json文件解压,读取其中的’text’项作为文本,代表点评网站yelp上客人的评价;’starts’项作为分类结果,代表客人的评分。论文中提到的一些细节:
- 构建词库时,将在数据集中没有超过5次的词,统一作为UNK处理。
- 采用单个神经元采用GRU,要比LSTM得到的效果好。
- 采用通过word2vec方式预训练好的词向量。在本次试验中没有另外预训练,直接采用随机初始化嵌入层的矩阵,这样会导致小数据集的训练结果不好,但是比较方便。
- 词向量维度为2000维
有了这些参数的设置,再通过下面的注释,处理数据集的代码data_helper.py应该就能很好看懂了。在数据中,每篇文档的句子个数不一样,每个句子的单词数也不一样,本例中采用实验室同学的想法,将每篇文档都处理为30*30的矩阵,将每篇文章中多余30的句子截断,将每个句子中多于30的单词进行截断,当然这样的处理是很粗糙的,正确的想法应该是google的nmt采用bucket将句子个数相近的,单词个数相近的文章排到一起,然后取当前batch中最大的长度进行截断,但是我自己在写代码的过程中还是出现问题,所以留作待处理问题。
#coding=utf-8
import os
import json
import pickle
import nltk
import numpy as np
from nltk.tokenize import WordPunctTokenizer
from collections import defaultdict
# 使用nltk分词分句器
sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
word_tokenizer = WordPunctTokenizer()
def build_vocab(vocab_path, yelp_json_path):
if os.path.exists(vocab_path):
vocab_file = open(vocab_path, 'rb')
vocab = pickle.load(vocab_file)
print "load focab finish!"
else:
# 记录每个单词及其出现的频率
word_freq = defaultdict(int)
# 读取数据集,并进行分词,统计每个单词出现次数,保存在word freq中
with open(yelp_json_path, 'rb') as f:
for line in f:
review = json.loads(line)
words = word_tokenizer.tokenize(review['text'])
for word in words:
word_freq[word] += 1
print "load finished"
# 构建vocablary,并将出现次数小于5的单词全部去除,视为UNKNOW
vocab = {}
i = 1
vocab['UNKNOW_TOKEN'] = 0
for word, freq in word_freq.items():
if freq > 5:
vocab[word] = i
i += 1
# 将词汇表保存下来
with open(vocab_path, 'wb') as g:
pickle.dump(vocab, g)
print len(vocab) # 159654
print "vocab save finished"
return vocab
def load_dataset(yelp_json_path, max_sent_in_doc, max_word_in_sent):
yelp_data_path = yelp_json_path[0:-5] + "_data.pickle"
vocab_path = yelp_json_path[0:-5] + "_vocab.pickle"
doc_num = 229907 #数据个数
if not os.path.exists(yelp_data_path):
vocab = build_vocab(vocab_path, yelp_json_path)
num_classes = 5
UNKNOWN = 0
# data_x的shape: [doc_num,max_sent_in_doc,max_word_in_sent]
# 而model中input_x的shape: [batch,max_sent_in_doc,max_word_in_sent]
data_x = np.zeros([doc_num,max_sent_in_doc,max_word_in_sent])
data_y = []
#将所有的评论文件都转化为30*30的索引矩阵,也就是每篇都有30个句子,每个句子有30个单词
# 不够的补零,多余的删除,并保存到最终的数据集文件之中
with open(yelp_json_path, 'rb') as f:
for line_index, line in enumerate(f):
review = json.loads(line)
sents = sent_tokenizer.tokenize(review['text'])
doc = np.zeros([max_sent_in_doc, max_word_in_sent])
for i, sent in enumerate(sents):
if i < max_sent_in_doc:
word_to_index = np.zeros([max_word_in_sent],dtype=int)
for j, word in enumerate(word_tokenizer.tokenize(sent)):
if j < max_word_in_sent:
word_to_index[j] = vocab.get(word, UNKNOWN)
doc[i] = word_to_index
data_x[line_index] = doc
label = int(review['stars'])
labels = [0] * num_classes
labels[label-1] = 1
data_y.append(labels)
print line_index
pickle.dump((data_x, data_y), open(yelp_data_path, 'wb'))
print len(data_x) #229907
else:
data_file = open(yelp_data_path, 'rb')
data_x, data_y = pickle.load(data_file)
length = len(data_x)
train_x, dev_x = data_x[:int(length*0.9)], data_x[int(length*0.9)+1 :]
train_y, dev_y = data_y[:int(length*0.9)], data_y[int(length*0.9)+1 :]
return train_x, train_y, dev_x, dev_y
if __name__ == '__main__':
load_dataset("data/yelp_academic_dataset_review.json", 30, 30)模型构建
这篇文章比较复杂的部分是模型构建。GRU的公式在Implementation of Hierarchical Attention Networks for Document Classification 论文中写的很清楚。在brightmart的例子的代码中,具体的写出了GRU的公式,当时就给我看跪了,我还傻傻的GRU和LSTM记不住呢!对于大多数初学者来说,可以使用tensorflow内置的RNN函数(在本例中为BidirectionalGRUEncoder)。对于想要实现这篇论文的同学,最好的办法还是clone github的代码,在模型中加断点观察shape,来与模型架构层次进行比对。
#coding=utf8
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.contrib import layers
def length(sequences):
used = tf.sign(tf.reduce_max(tf.abs(sequences), reduction_indices=2))
seq_len = tf.reduce_sum(used, reduction_indices=1)
return tf.cast(seq_len, tf.int32)
class HAN():
def __init__(self, vocab_size, num_classes, embedding_size=200, hidden_size=50):
self.vocab_size = vocab_size
self.num_classes = num_classes
self.embedding_size = embedding_size
self.hidden_size = hidden_size
with tf.name_scope('placeholder'):
self.max_sentence_num = tf.placeholder(tf.int32, name='max_sentence_num')
self.max_sentence_length = tf.placeholder(tf.int32, name='max_sentence_length')
self.batch_size = tf.placeholder(tf.int32, name='batch_size')
#x的shape为[batch_size, 句子数, 句子长度(单词个数)],但是每个样本的数据都不一样,,所以这里指定为空
#y的shape为[batch_size, num_classes]
self.input_x = tf.placeholder(tf.int32, [None, None, None], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name='input_y')
#构建模型
word_embedded = self.word2vec()
sent_vec = self.sent2vec(word_embedded)
doc_vec = self.doc2vec(sent_vec)
out = self.classifer(doc_vec)
self.out = out
def word2vec(self):
with tf.name_scope("embedding"):
embedding_mat = tf.Variable(tf.truncated_normal((self.vocab_size, self.embedding_size)))
#shape为[batch_size, sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.nn.embedding_lookup(embedding_mat, self.input_x)
return word_embedded
def sent2vec(self, word_embedded):
with tf.name_scope("sent2vec"):
#GRU的输入tensor是[batch_size, max_time, ...].在构造句子向量时max_time应该是每个句子的长度,所以这里将
#batch_size * sent_in_doc当做是batch_size.这样一来,每个GRU的cell处理的都是一个单词的词向量
#并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量
#shape为[batch_size*sent_in_doc, word_in_sent, embedding_size]
word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size])
#shape为[batch_size*sent_in_doce, word_in_sent, hidden_size*2]
word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder')
#shape为[batch_size*sent_in_doc, hidden_size*2]
sent_vec = self.AttentionLayer(word_encoded, name='word_attention')
return sent_vec
def doc2vec(self, sent_vec):
with tf.name_scope("doc2vec"):
sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size*2])
#shape为[batch_size, sent_in_doc, hidden_size*2]
doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder')
#shape为[batch_szie, hidden_szie*2]
doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention')
return doc_vec
def classifer(self, doc_vec):
with tf.name_scope('doc_classification'):
out = layers.fully_connected(inputs=doc_vec, num_outputs=self.num_classes, activation_fn=None)
return out
def BidirectionalGRUEncoder(self, inputs, name):
#输入inputs的shape是[batch_size, max_time, voc_size]
with tf.variable_scope(name):
GRU_cell_fw = rnn.GRUCell(self.hidden_size)
GRU_cell_bw = rnn.GRUCell(self.hidden_size)
#fw_outputs和bw_outputs的size都是[batch_size, max_time, hidden_size]
((fw_outputs, bw_outputs), (_, _)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=GRU_cell_fw,
cell_bw=GRU_cell_bw,
inputs=inputs,
sequence_length=length(inputs),
dtype=tf.float32)
#outputs的size是[batch_size, max_time, hidden_size*2]
outputs = tf.concat((fw_outputs, bw_outputs), 2)
return outputs
def AttentionLayer(self, inputs, name):
#inputs是GRU的输出,size是[batch_size, max_time, encoder_size(hidden_size * 2)]
with tf.variable_scope(name):
# u_context是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度,
# 因为使用双向GRU,所以其长度为2×hidden_szie
u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context')
#使用一个全连接层编码GRU的输出的到期隐层表示,输出u的size是[batch_size, max_time, hidden_size * 2]
h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh)
#shape为[batch_size, max_time, 1]
alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1)
#reduce_sum之前shape为[batch_szie, max_time, hidden_szie*2],之后shape为[batch_size, hidden_size*2]
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)
return atten_output模型训练
模型训练部分的代码如下,都是一些常用的训练过程。模型的训练效果不太好,经过一万多步的训练,准确率只能达到40%左右。原因主要有两个,首先数据集较小,采用随机初始化的方式做嵌入层,词向量的表达就不太准确。其次,用30*30的矩阵代表一篇文章,并不能很好的表示文章,所以应该首先进行排序,将相似大小的文章放在一起然后再做截断或者填充。我会在实现了brightmart所有模型以后,再来处理这些细节的问题,从整体上看问题有助于理解文本分类的各种处理方法。
#coding=utf-8
import tensorflow as tf
import time
import os
from data_helper import load_dataset
from HAN_model import HAN
# Data loading params
tf.flags.DEFINE_string("yelp_json_path", 'data/yelp_academic_dataset_review.json', "data directory")
tf.flags.DEFINE_integer("vocab_size", 46960, "vocabulary size")
tf.flags.DEFINE_integer("num_classes", 5, "number of classes")
tf.flags.DEFINE_integer("embedding_size", 200, "Dimensionality of character embedding (default: 200)")
tf.flags.DEFINE_integer("hidden_size", 50, "Dimensionality of GRU hidden layer (default: 50)")
tf.flags.DEFINE_integer("batch_size", 32, "Batch Size (default: 64)")
tf.flags.DEFINE_integer("num_epochs", 10, "Number of training epochs (default: 50)")
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)")
tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("max_sent_in_doc", 30, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("max_word_in_sent", 30, "Number of checkpoints to store (default: 5)")
tf.flags.DEFINE_integer("evaluate_every", 100, "evaluate every this many batches")
tf.flags.DEFINE_float("learning_rate", 0.01, "learning rate")
tf.flags.DEFINE_float("grad_clip", 5, "grad clip to prevent gradient explode")
FLAGS = tf.flags.FLAGS
train_x, train_y, dev_x, dev_y = load_dataset(FLAGS.yelp_json_path, FLAGS.max_sent_in_doc, FLAGS.max_word_in_sent)
print "data load finished"
with tf.Session() as sess:
han = HAN(vocab_size=FLAGS.vocab_size,
num_classes=FLAGS.num_classes,
embedding_size=FLAGS.embedding_size,
hidden_size=FLAGS.hidden_size)
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=han.input_y,
logits=han.out,
name='loss'))
with tf.name_scope('accuracy'):
predict = tf.argmax(han.out, axis=1, name='predict')
label = tf.argmax(han.input_y, axis=1, name='label')
acc = tf.reduce_mean(tf.cast(tf.equal(predict, label), tf.float32))
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
global_step = tf.Variable(0, trainable=False)
optimizer = tf.train.AdamOptimizer(FLAGS.learning_rate)
# RNN中常用的梯度截断,防止出现梯度过大难以求导的现象
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), FLAGS.grad_clip)
grads_and_vars = tuple(zip(grads, tvars))
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g is not None:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
grad_summaries.append(grad_hist_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
loss_summary = tf.summary.scalar('loss', loss)
acc_summary = tf.summary.scalar('accuracy', acc)
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph)
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=FLAGS.num_checkpoints)
sess.run(tf.global_variables_initializer())
def train_step(x_batch, y_batch):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
_, step, summaries, cost, accuracy = sess.run([train_op, global_step, train_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
train_summary_writer.add_summary(summaries, step)
return step
def dev_step(x_batch, y_batch, writer=None):
feed_dict = {
han.input_x: x_batch,
han.input_y: y_batch,
han.max_sentence_num: 30,
han.max_sentence_length: 30,
han.batch_size: 64
}
step, summaries, cost, accuracy = sess.run([global_step, dev_summary_op, loss, acc], feed_dict)
time_str = str(int(time.time()))
print("++++++++++++++++++dev++++++++++++++{}: step {}, loss {:g}, acc {:g}".format(time_str, step, cost, accuracy))
if writer:
writer.add_summary(summaries, step)
for epoch in range(FLAGS.num_epochs):
print('current epoch %s' % (epoch + 1))
for i in range(0, 200000, FLAGS.batch_size):
x = train_x[i:i + FLAGS.batch_size]
y = train_y[i:i + FLAGS.batch_size]
step = train_step(x, y)
if step % FLAGS.evaluate_every == 0:
dev_step(dev_x, dev_y, dev_summary_writer)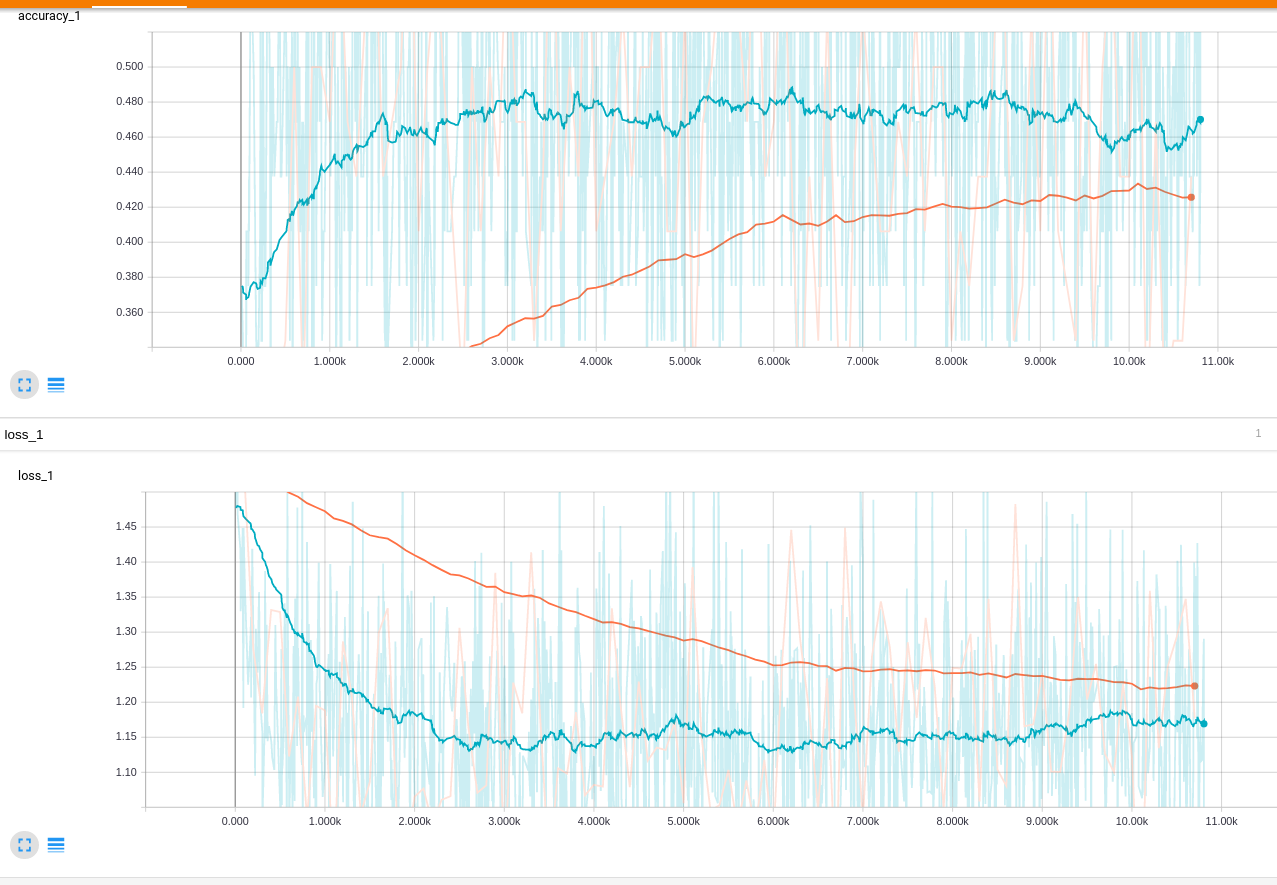















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









