









1. VQA
Visual Question Answering,给出一张图片,就该图片提出任何问题?自动get到你所期望的答案。
这属于Visual Reasoning 的范畴,学者们不满足于传统的图像识别、分割、Caption等工作,尝试去挖掘更高级的机器推理能力。
来看解决思路,CNN、LSTM(RNN)、Attention Model、BOW,都是图像、文本、NLP领域的通用手法,没什么新词。
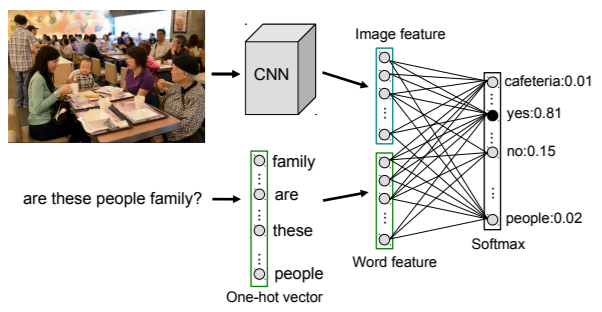
参考一下MIT周博磊同学的 demo(基于BOW+IMG):
http://visualqa.csail.mit.edu/
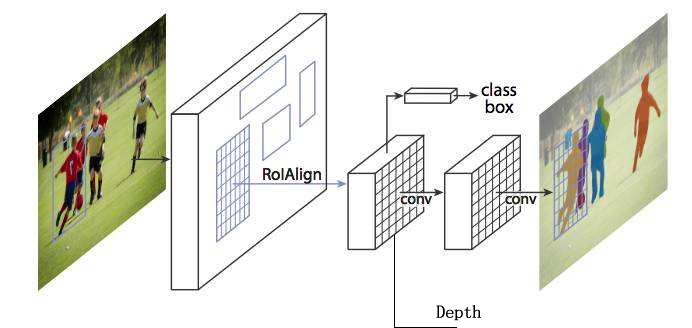
2. 单图像目标深度估计
基于单图像的深度做的比较多了,目前基于目标的检测做的工作非常多,如何提取有效景深还是蛮重要的一个话题,目前已经有不少团队在尝试了。
设想基于Mask-RCNN,再添加一个分支,用来做depth。
3. 基于视频流的分析
视频解码的代价太大了,如果在视频不解码的基础上做分析,能解决非常大的计算量,各种嵌入式设备上的应用,有什么办法能够有效的解决这个问题,能解决伐?想想做梦能笑醒!
4. AI水军
最近很火的一个话题,好多5毛党要失业了,这才是刚需啊。
与之相比,摆摊安装caffe、tensorflow啥的真是太low了。
















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









