







 本文介绍了如何使用深度学习模仿Prisma,将普通图片转换为艺术风格图像。通过训练深层卷积神经网络,提取艺术作品的风格特征,然后应用到输入图片上。文章展示了不同阶段的艺术作画效果,并探讨了实现快速艺术作画的策略,包括特征提取、图像预处理和滤波方法。最后,提供了实现代码和GUI界面,以方便进一步的实验和调整。
本文介绍了如何使用深度学习模仿Prisma,将普通图片转换为艺术风格图像。通过训练深层卷积神经网络,提取艺术作品的风格特征,然后应用到输入图片上。文章展示了不同阶段的艺术作画效果,并探讨了实现快速艺术作画的策略,包括特征提取、图像预处理和滤波方法。最后,提供了实现代码和GUI界面,以方便进一步的实验和调整。
编者按:本书节选自图书《机器学习之路——Caffe、Keras、scikit-learn实战》,高深的数学理论,复杂的算法又让很多机器学习入门者忘而却步,不知从何下手,本书绕过理论障碍,打通了一条由浅入深的机器学习之路。
丰富的实战案例讲解,介绍如何将机器学习技术运用到股票量化交易、图片渲染、图片识别等领域。
本文将探索深度学习落地到图像处理领域的方案,适合有一定深度学习实践经验的读者进阶阅读。
使用深度学习作画的起源是有三个德国研究员想把计算机调教成梵高,他们研发了一种算法,模拟人类视觉的处理方式。具体是通过训练多层卷积神经网络,让计算机识别,并学会梵高的“风格”,然后将任何一张普通的照片变成梵高的《星空》。

后来他们开创了Deep Art公司,在Deep Art公司,负责绘画的程序员是卷积神经网络(CNN)。输入一个艺术作品,比如梵高的《星空》,卷积神经网络就会自动提取出这幅画作的“风格特征”,并转换成风格模板保存下来。也就是说,卷积神经网络可以被看作是一个机器艺术家。
Prisma第一次将这项艺术作画技术成功商业化。Prisma诞生于俄罗斯,是一个仅有4个年轻人历时一个半月开发出的图片处理应用。他们充分考虑了智能手机覆盖率的飞速增长,并且细致研究了用户行为。Prisma接入的是以亿数量级的市场,俄国总统梅德韦杰夫也成为了Prisma的用户,他在Instgram上晒出了一张Prisma作品,迅速获得8.7万个赞。
Google的Deep Dream也是一个会画画的计算机。它能够自动识别图像,筛选其中一些部分,进行夸张,以创造出一种迷幻效果。Deep Dream完全开源,在几个主流的深度学习库如Keras、Caffe的官方example中,都有Deep Dream的实现Demo。
本章我们将探索实现类似Prisma的效果。
备注:
本章完整项目地址:https://github.com/bbfamily/prisma_abu
本项目演示视频:m.v.qq.com/play.html?&vid=v0397sv1fab,也可以在公众号abu_quant中直接观看视频。
机器学习初探艺术作画
好的艺术家模仿皮毛,伟大的艺术家窃取灵魂。 ——毕加索
本节介绍机器学习作画的简单原理,并展示输出效果。
艺术作画概念基础
第6章介绍了CNN如何提取图片中的图形特征,进而识别图片实物。现在,假设这里已经训练好了一个“识别毕加索绘制的猫”的深层卷积神经网络模型,如果把一张完全不同的照片输入模型,比如一张狗的照片,会发生什么呢?
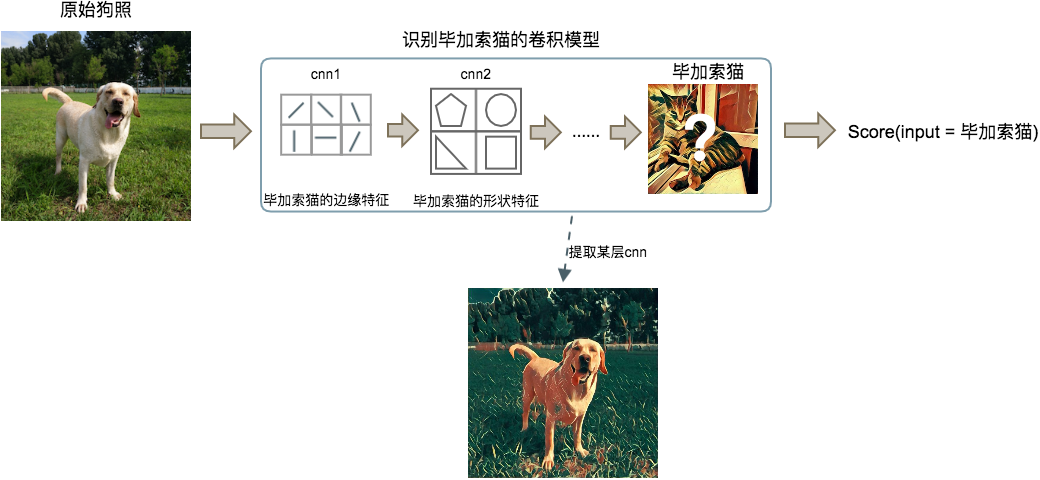
模型会给你反馈一个概率分数,表示它相信这是一张“毕加索猫”照片的程度。这中间经历了很多CNN层,每层CNN都在狗狗照片上寻找输入样本是毕加索猫的图形特征证据,越底层的神经元分析的特征越具体,越高层越抽象。当然,最后模型会给出很低的分数。
上面在狗照上识别毕加索猫的过程中,如果让模型能够修改输入的样本又会怎样呢?
给模型网络中加一个反馈回路,让每一层网络可以朝着使最后分数变大的方向上修改狗狗照片。每次迭代网络中的每层都会在狗照上增加一些毕加索猫的特征痕迹,可以迭代很多次,让狗狗照片中加入越来越多的毕加索猫的实物特征。
这就是使用卷积神经网络艺术作画的概念基础,让艺术风格模型的CNN按图形特征修改输入图片,叠加艺术效果。大致的实现思路如下:
- 输入特征图像,训练风格模型,让计算机学会艺术风格。
- 输入待处理图,风格模型引导修改输入图片,生成新的图像,输出“艺术画”。
接下来将模拟Prisma的效果,实现艺术作画。
直观感受一下机器艺术家
这里我们展示一下机器艺术作画的效果,原图如图9-3所示。

下面我们用这几个浅层神经元对原图风格化的效果进行展示(备注:代码实现见本书Git库),如图9-4所示。

有没有感觉到特征的识别由浅入深的一步一步增强,也就是从edge,到shape,再到复杂的shape循序渐进的过程,这里主要是卷基层把每层的特质放大进行夸张凸显。
图9-5展示了更多其他风格作画。

一个有意思的实验
如果用Prisma做出一个图像,然后将它作为特征图像去引导新的图像生成会有什么效果呢?
guide = np.float32(
tp.resize_img(PIL.Image.open('../prisma_gd/106480401.jpg')))
PrismaHelper.show_array_ipython(guide)输出:

如图9-7所示,有些特征还是挖掘到了。
PrismaHelper.show_array_ipython(tp.fit_guide_img(s_file, gd_path, resize=True, size=640, iter_n=1500))
输出:

机器艺术作画的愿景
当机器能够根据图像的平面特征作画时,很多灵感也随之而来。比如我们可以从引导图中发现图像特征,从多个特征中寻找出存在的对象,并将这个特征融合到另一个图像中做特征融合。如果能够将特征识别融合做到极致,就可以完成如下假想场景。
- 抬起头看到天边一朵云,看起来好像我家拉布拉多犬呢,是不是可以替换一下呢?
- 用手机拍下这朵云,将狗狗的照片和云的照片发到云端进行特征识别融合。
- 云端将融合好后的图像发回给用户。

回顾
本节我们介绍了深度学习艺术作画的原理,并展示了直观的效果,在使用Deep Dream等开源项目实现上述效果时,速度非常缓慢,所以从9.2节开始我们将使用自己的方式实现快速Prisma,实现秒级作画。
实现秒级艺术作画
天下武功,唯快不破。互联网竞争的利器就是快。——雷军
和Deep Art相比,Prisma的优势在于大大缩短了图像处理的时间,每张照片在Prisma系统内的处理时间控制在秒级别。而Deep Art更像是精工细作的手艺人,算法跑得虽然慢一些,但在细节表现力上更胜一筹。
在本书写作之前,笔者参考了几个艺术作画开源项目,都达不到真实Prisma的速度要求,本节将要使用的方式都是笔者原创的方法。首先笔者并不知道Prisma到底使用了什么方式使图像效果又好,速度又快,但是大概猜测的方向包括这几种可能:
- 大量的多CPU、GPU的机器(绝对不现实,成本根本无法控制)。
- 未知的算法优化、网络框架优化(就算是这样,这也是我们没有能力突破的黑盒)。
- 拥有很大的图像数据库,可以很快地检索出与输入图像相似度最高的图像,之后相似特征提取、权重渲染。
- 针对图像的部分区域使用机器学习算法将特征层放大,配合一些图像处理技术,提升渲染速度。
第三种方式是说在拥有海量图片数据的前提下,作一个分类模型。对于一个输入图片,模型先分类出这是哪种类型,根据类型选择固定的特征提取方式进行渲染。而第四种方式是使用一些图片预处理技术减少机器学习算法的工作量。
由于我们没有足够的图片资源,而且第三点实现方式的速度瓶颈会在检索和相似度计算上,所以下面讲的内容是针对第四点展开试验的,可以在速度及渲染效果上都达到比较满意的效果。而唯一的缺陷就在适用性上,实际使用时需要调整一下参数,所以在实际使用中可以结合上述第三种方式,针对一定数量的样本作为训练集x,对应的y是效果参数,对输入进行分类,再配合使用相似度等提高自动适配的能力。
主要实现思路分解讲解
下面还是使用abu1这张图片作为输入:
from PrismaCaffe import CaffePrismaClass
import PrismaHelper
import numpy as np
import PIL.Image
abu1_file = '../sample/abu1.jpg'
cp = CaffePrismaClass(dog_mode=False)
PrismaHelper.show_array_ipython(
np.float32(cp.resize_img(PIL.Image.open(abu1_file))))
输出如图9.9所示。

下一步,挑一张引导特征图像:
gd_path = '../prisma_gd/tooopen_sy_127260228921.jpg'
guide_img = np.float32(
cp.resize_img(PIL.Image.open(gd_path), base_width=480,
keep_size=False))
PrismaHelper.show_array_ipython(guide_img)
输出:

如下所示,首先将图像转化为单通道,用otsu寻找mask, 通过mask确定border和edges。
说明:otsu(大津算法, 自适应阈值)
- 关于skimage otsu等使用请参考:http://scikit-image.org/
- 关于scipy ndimage等使用请参考:https://docs.scipy.org
输入:
r_img = cp.resize_img(PIL.Image.open(abu1_file), base_width=480,
keep_size=False)
# rgb转化为单通道灰阶图像
l_img = np.float32(r_img.convert('L'))
# filters.threshold_otsu需要(-1, 1)之间
l_img = np.float32(l_img / 255)
r_img = np.float32(r_img)
# 找出大于otsu的阀值作为mask,需找border
mask = l_img > filters.threshold_otsu(l_img)
# 不是适用所有图像都要clear border,比如图像主题大部分需要保留时就不需要
clean_border = segmentation.clear_border(mask).astype(np.int)
coins_edges = segmentation.mark_boundaries(l_img, clean_border)
# 将值再次转换到0-255
clean_border_img = np.float32(clean_border * 255)
clean_border_img = np.uint8(np.clip(clean_border_img, 0, 255))
PrismaHelper.show_array_ipython(clean_border_img)
输出:

目标就是只想摘取狗狗的图像,其他的都认为是噪音,可以使用ndimage.binary _opening。达到效果了吗,试试看:
clean_border_img = ndimage.binary_opening(
np.float32(clean_border_img / 255),
structure=np 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3348
3348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









