







Supervised Hashing
for Image Retrieval via Image Representation Learning
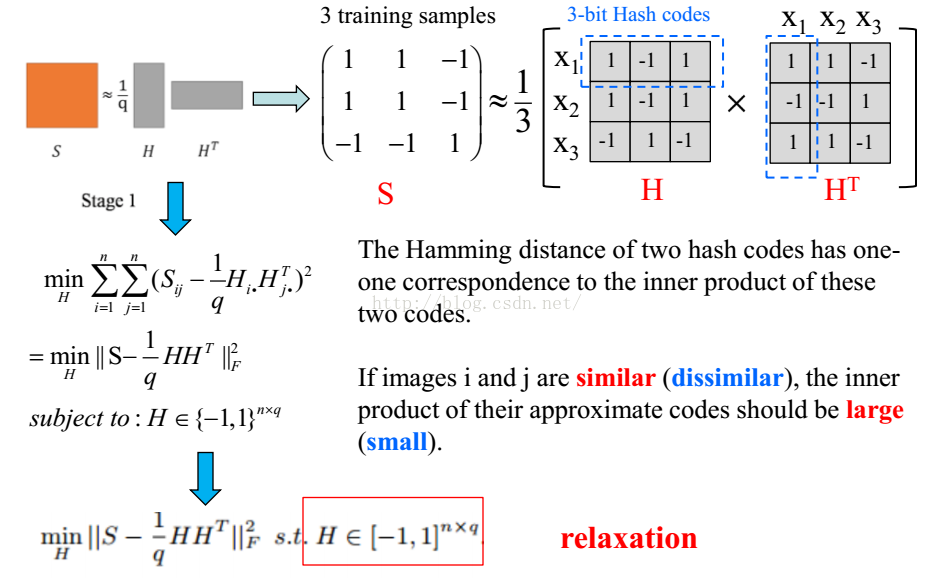
这篇论文主要是哈希方法引入CNN的首篇文章。核心思想是把一个image encode成为一个二进制表示的vector。这样做的好处是可以大幅度的减少存储feature的磁盘开销。该片paper分为两个stage,第一个阶段主要是从LMNN受到的启发,先做一个相似度矩阵S,其中sij=1表示相似的图片,sij=-1表示不相似的图像。S的大小是n*n,n表示图像的个数。
下一步是把S分解成为S=H*H^T,H大小为N*Q,Q直观地表示是把N压缩之后的大小,也就是说用大小为Q的vector表示大小为N的vector,这里的vector中的每个元素表示的是和其他vector的区别(用1和-1表示),之后会使用压缩之后的Q作为label。
第一阶段:hash的目标使得相似的映射到相近的区域。不同的label尽量的远一些,相同的尽量放到一起。如图所示:
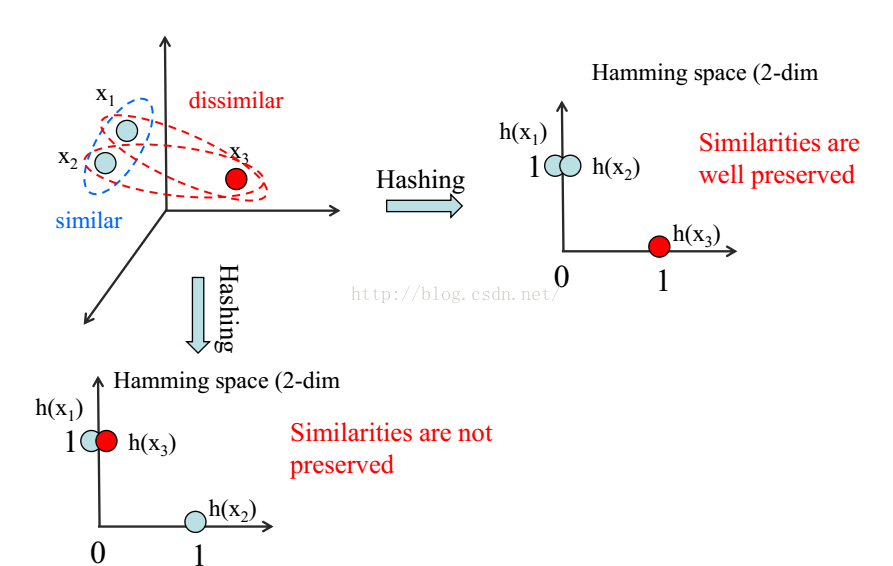
第一阶段主要是把S分解成为H,如下图的左侧,右侧表示的把学习到的H,(红色点)
作为label,原始的图像作为输入的data,去学习image representations。这些学习到的representations具有discriminative的能力。

下一阶段分为两种方法,CNNH和CNNH+
CNNH:

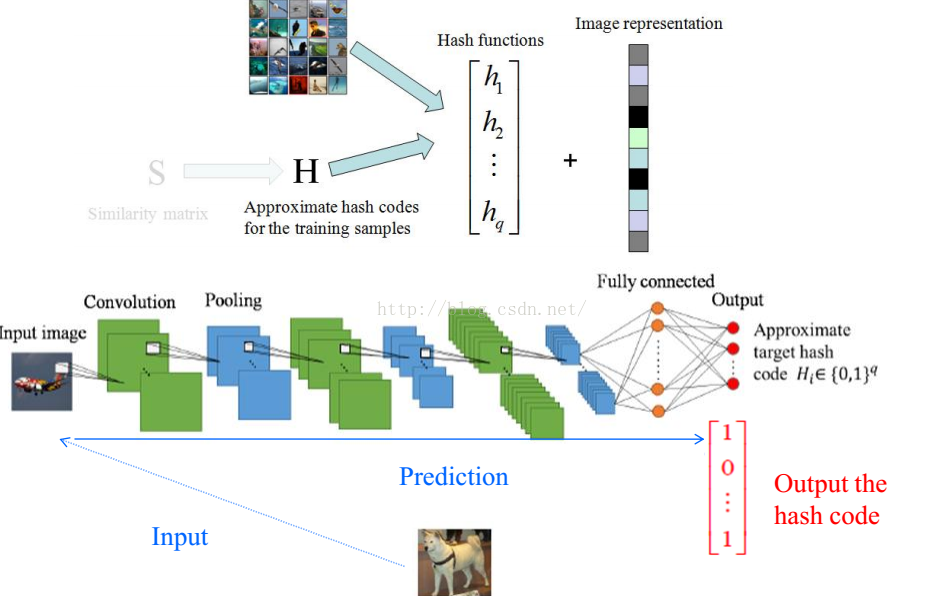
CNNH的输入时image,对应的label是stage1学习到的Q,这里用红色表示。
CNNH+:

CNNH+加入了黑色的点。这些点是原image的对应标签,输入的图像是多标签的,有沙滩天空,对应的位置标签是1。这里使用加入了黑色的label。CNNH+使用黑色和红色的点作为label,学习特征。














 3586
3586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









