







 本文介绍了如何使用Theano构建一个具有单隐层的多层感知器(MLP)神经网络,包括激活函数的选择、权重初始化、模型结构及优化过程。通过对比逻辑回归,展示了MLP如何解决非线性问题。并提供了完整的MLP实现代码,以MNIST数据集为例,展示训练过程和结果,揭示了MLP相对于逻辑回归的性能优势。
本文介绍了如何使用Theano构建一个具有单隐层的多层感知器(MLP)神经网络,包括激活函数的选择、权重初始化、模型结构及优化过程。通过对比逻辑回归,展示了MLP如何解决非线性问题。并提供了完整的MLP实现代码,以MNIST数据集为例,展示训练过程和结果,揭示了MLP相对于逻辑回归的性能优势。
前言
上一章学习了用逻辑回归函数对MNIST数据集分类,本章将是逻辑回归模型的升级——多层感知器(MLP,神经网络)。本章将学习具有一个隐层的神经网络,它首先将输入进行非线性变换,再输入逻辑回归模型,这样模型就可以拟合非线性问题。非线性层称为隐层,通常一个隐层就可使得模型性能足够优异,但在深度学习中会有更多的隐层。有关神经网络反向梯度更新的理解可以参考:11行Python代码编写神经网络。
MLP模型
具有单隐层的神经网络结构如下图所示:
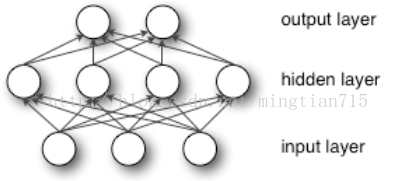
网络对应的映射函数f:Rd->RL,其中d是输入层(input layer)的节点数,L是输出层(output layer)的节点数。f(x)定义:
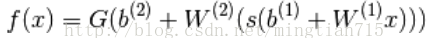
以上参数:W(1),W(2)为2层的权重系数,b(1),b(2)为偏移系数,s和G为2层的激活函数。
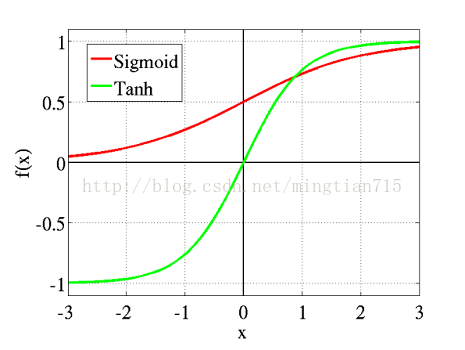
h(x) = s(b(1)+w(1)x)表示隐层节点值,s通常为sigmoid函数,sigmoid(a) = 1/(1+exp(-a)),但此处我们采用激活函数tanh(a) = (exp(a) - exp(-a))/(exp(a) + exp(-a)),因为tanh会使得训练速度更快。tanh函数和sigmoid函数图如下,它们的取值区间不同,但都属于一种压缩函数,且导数形式简单。
o(x)=G(b(2)+W(2)h(x))就是上一章逻辑回归的内容啦,因此激活函数G选择softmax函数。
优化过程依然采用批量梯度下降法,需要确定的参数包括{W(1),W(2),b(1),b(2)},至于如何根据输出更新参数,可以参看我之前有关神经网络的文章。
从逻辑回归到MLP
我们已经有了逻辑回归类了,只需要再定义隐层类:
class HiddenLayer(object):
def __init__(self, rng, input, n_in, n_out, W=None, b=None,
activation=T.tanh):
"""
Typical hidden layer of a MLP: units are fully-connected and have
sigmoidal activation function. Weight matrix W is of shape (n_in,n_out)
and the bias vector b is of shape (n_out,).
NOTE : The nonlinearity used here is tanh
Hidden unit activation is given by: tanh(dot(input,W) + b)
:type rng: numpy.random.RandomState
:param rng: a random number generator used to initialize weights
:type input: theano.tensor.dmatrix
:param input: a symbolic tensor of shape (n_examples, n_in)
:type n_in: int
:param n_in: dimensionality of input
:type n_out: int
:param n_out: number of hidden units
:type activation: theano.Op or function
:param activation: Non linearity to be applied in the hidden
layer
"""
self.input = input如何初始化隐层权重与激活函数的选择有关,一般是从一个对称区间内随机采样。
激活函数为tanh时,W从![[-\sqrt{\frac{6}{fan_{in}+fan_{out}}},\sqrt{\frac{6}{fan_{in}+fan_{out}}}]](http://www.deeplearning.net/tutorial/_images/math/1dfc4a270526d7a1f3411a25a81a580f05b61d84.png) 采样;激活函数是sigmoid时,从
采样;激活函数是sigmoid时,从![[-4\sqrt{\frac{6}{fan_{in}+fan_{out}}},4\sqrt{\frac{6}{fan_{in}+fan_{out}}}]](http://www.deeplearning.net/tutorial/_images/math/67fb8dc5b0626d0673435da43542cab7e3453c38.png) 采样,其中
采样,其中 是第 i-1 层神经元数量,
是第 i-1 层神经元数量, 是第 i 层神经元的数量;b初值为0。
是第 i 层神经元的数量;b初值为0。
采样;激活函数是sigmoid时,从采样,其中是第 i-1 层神经元数量,是第 i 层神经元的数量;b初值为0。
这样初始化可以保证在初始优化阶段,神经网络可以顺利地进行正向传播和反向传播,其实这跟W的梯度公式也有关系,如果W为0,则梯度会一直保持0,网络无法更新。
# `W` is initialized with `W_values` which is uniformely sampled
# from sqrt(-6./(n_in+n_hidden)) and sqrt(6./(n_in+n_hidden))
# for tanh activation function
# the output of uniform if converted using asarray to dtype
# theano.config.floatX so that the code is runable on GPU
# Note : optimal initialization of weights is dependent on the
# activation function used (among other things).
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









