










一、BackPropagation
- wljk :表示第 l−1 层第k个神经元到第 l 层第j个神经元的连接权重;
- blj :表示第 l 层第j个神经元的偏置;
- zlj :表示第 l 层第j个神经元的带权输入;
- alj :表示第 l 层第j个神经元的激活值;
- σ :表示一个激活函数(sigmoid,relu,tanh);
向量化上面的公式:
- L(W,b,x,y):表示损失函数,其中y是正确值,x是输入,下面是二次方损失函数的计算;
- 阿达马(Hadamard)乘积,表示两个同维度向量a,b按元素相乘的结果向量,用 a⊙b 表示。
- 反向传播BP计算的目标: ∂L∂wljk 和 ∂L∂blj ,也就是L对所有参数的偏导数。
- δlj :表示第 l 层第j个单元的残差。也就是 ∂L∂zlj 。
- δLj=∂L∂aLjσ′(zLj) :表示顶层(输出层,假设是第L层)的残差,也就是损失函数对输出层的带权输入的偏导数。这个公式也可以进行向量化,为以下的形式:
- 当使用二次损失函数的时候, δl=(aL−y)⊙σ′(zL) 。
- 使用上一层的残差表示当前层的残差:
- 最后,利用链式求导求出来的结果:
向量化以上的结果,得到:
二、RNN
- RNN能够从之前的输入中映射出输出,具有一定程度的记忆能力,能够从之前的输入中存储网络的内部状态。
- 有足够多隐藏单元的RNN能够模拟任何Sequence-to-Sequence的映射。
1.RNN的forward pass
注:下面这段使用的符号和上面的符号定义又有些不同,没办法,下面这篇论文就是这么用的。
Graves A. Supervised Sequence Labelling with Recurrent Neural Networks[M]. Springer Berlin Heidelberg, 2012.
- 一个I个输入单元、H个隐藏单元和K个输出单元的RNN,输入序列是 x ,长度为 T , xti 是输入单元 i 在 t 时刻的输入。
- 对每一个隐藏单元h,其t时刻的带权输入值 ath 如下所示,也就是本文第一章中的 zth ,(⊙o⊙)…好乱:
- 也就是,其带权输入值不仅与这一时刻的输入层单元值相关,还与上一时刻所有隐藏单元的激活值 bt−1h′ 相关,而激活值计算如下所示,其中 θh 是激活函数(tanh,sigmoid,….),这里是一样的:
- 整个网络从t=1开始迭代, b0h 可以取全0,不过2006年之后也有人提出,使用非0来初始化能够提高RNN的性能和稳定性。
- 第k个输出单元t时刻的值按照下面的公式计算,就是每个隐藏单元激活值的连接,这里并没有引入偏置向量,不过可以认为是第0个单元,不影响:
2.RNN的Output层和损失函数
按照实际情况选择RNN输出层的激活函数(sigmoid,softmax)和损失函数(cross_entropy)。
RNN应用在时间序列分析。
3.RNN的backward pass
现在计算出cross_entropy损失函数L关于输出y的偏导数,下一步就是计算L关于权重的偏导数。
已经提出的两种算法,可以有效的计算RNN的权重偏导数
- real time recurrent learning(RTRL,1987)
- backpropagation through time(BPTT,1990)
这里对BPTT进行介绍,因为它的思想更简单,而且计算效率更高。
BPTT也是通过链式法则的应用进行权值训练,但是对于递归神经网络,一个隐藏层单元激活值的影响不仅仅通过通往输出层的连接,还可以通过对下一时刻(timestep)隐藏层的影响。所以,残差 δth 的计算也应该包含这两条线路,如下所示:
这里的残差计算方式和第一章相同, δtj=∂L∂atj 。其中a是带权输入。
这样从T开始计算,算到1,就可以得出 ∂L∂wij ,注意在这里整个网络在所有时刻使用的是同一权重。
4.双向RNN
BRNN,1997、1999年提出。能够使用输入序列当前时刻后面的内容作为上下文。使用两个隐藏层,一个从前往后一个从后向前,两个隐藏层互不连接。
- 前向过程
从1到T,前向隐藏层的前向过程,存储每个t的激活值。
从T到1,后向隐藏层的前向过程,存储每个t的激活值。
对于所有t,使用前两步计算的激活值,进行输出层的前向过程。
- 后向过程
对所有t,计算输出层的 δ 值。
对T到1,利用 δ 进行前向隐藏层的后向过程。
对1到T,利用 δ 进行后向隐藏层的前向过程。
BRNN可以应用于像蛋白质结构预测(2001)、时间序列任务、自动听写等应用中。
5.序列雅克比矩阵(sequential Jacobian原谅我不知道它怎么翻译)
6.训练神经网络的一些tricks
- 梯度下降算法:批量vs在线,梯度下降、动量momentum
- 一些批量梯度下降算法:RPROP、quickprop、conjugate gradients、L-BFGS
- 在线学习算法:stochastic meta-descent
- 泛化方式
- early stopping
- 输入增加高斯噪声
- 权重增加高斯噪声
- 输入的表示,输入的标准化(把输入向量化为均值0,标准差1)很重要。
- 权重的初始化,小而随机
三、LSTM
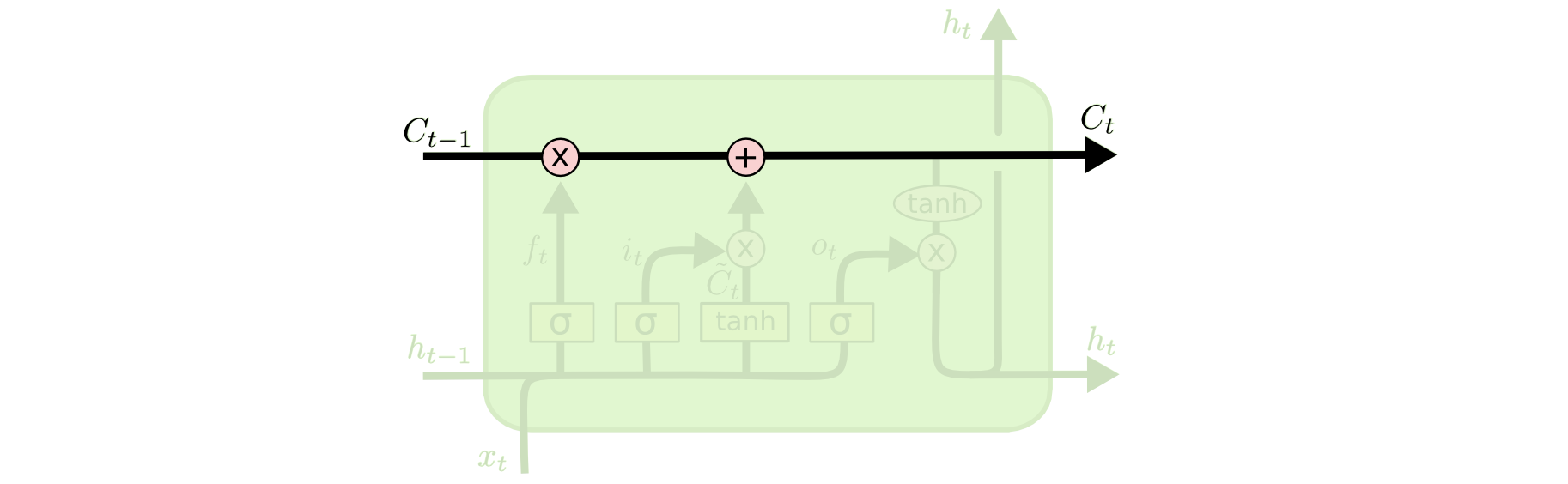
1.网络结构
- Memory Block(Memory Cell)
- 输入: xt
- input gate输入门: it
- output gate输出门: Ot
- forget gate遗忘门: ft
- 细胞状态: Ct
- 单元激活值: ht
盗个图过来吧,文字还是有点描述不清楚,以后别记不得了。
2.LSTM的变种和进一步研究
- 2000年,增加了窥视孔连接Peephole,所有或者部分公式中的$[h{t-1},x_t] 替换为 [C{t-1},h_{t-1},x_t]$。
- 配对了遗忘门和输入门,即 it=1−ft 。
- 2014年,Gated Recurrent Unit(GRU),合并了细胞状态和单元激活值,合并输入门和遗忘门为更新门,模型更加简单。
- Depth Gated RNNs, Clockwork RNNs等
- 注意力机制、Grid LSTM等
3.预处理
预处理能够通过采样减少输入序列的长度,从而使得LSTM能够更好的进行处理,上下文信息更少。
4.双向LSTM
5.LSTM的正向(激活)和反向(BPTT)过程
下面的过程都是带peephole的LSTM。输入公式还是不如手写方便,还是手写吧。。。
- 正向过程:
- 反向过程:
6.参考
http://blog.csdn.net/ycheng_sjtu/article/details/48792467














 5821
5821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









