







第二天上午两大主题:富有新意活力的图像与语言部分,以及在传统中更上层楼的多视几何。
D2-AM-A. Image and Language
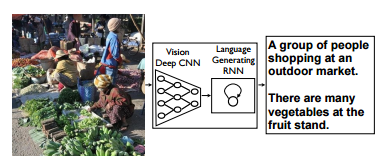
【Show and Tell: A Neural Image Caption Generator】
看图说话:神经网络图像标题生成器
(Google)
输入图片,输出一句描述性语言。
训练:最大化训练集中,标定的文本的似然函数。
vision CNN + language RNN(recursive)
在machine translation中,最近的潮流是:不在单独翻译单词、对齐单词,而是直接最大化P(Target|Source)
源语言用RNN进行encode,而后再用另一个RNN进行decode。
本文用图像的CNN来代替第一部分。
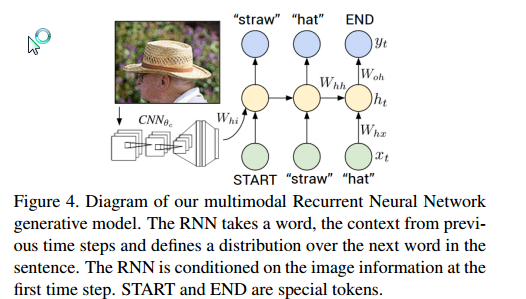
【Deep Visual-Semantic Alignments for Generating Image Descriptions】
用于生成图像描述的深度网络视觉语义对齐
(Li Fei-Fei)
输入图片,输出一句描述性语言。同时给出词组和图片区域的对应关系。
把训练集中标定的文本当做weak label,其中相邻的词组表示图片中的某一未知区域。
使用multimodal RNN,把图片作为输入,生成文本。
【Long-Term Recurrent Convolutional Networks for Visual Recognition and Description】
用于视觉识别和描述的长时RCNN
输入短视频,输出描述。三个特征:long term处理时序,recurrent处理文本,convolutional处理图像。
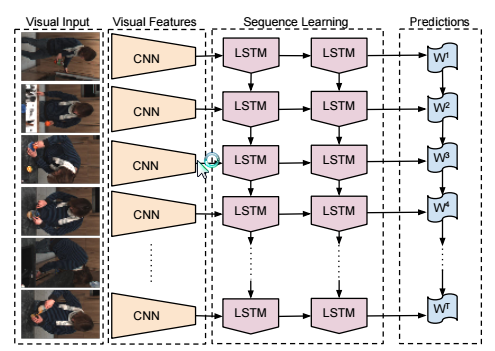
LSTM (long-short term memory):一种时间递归神经网络。
【Image Specificity】
图像明晰度
specific:图片的主题明确程度。如果不同人给一张图片写说明,结果关键词非常类似,则说明specificity高。
可以用在图像搜索中:
如果图像主题明确,则图像和搜索词的相似度很高,才能认为“命中”;如果图像主题模糊,则较低的相似度,也可以返回“命中”。
分类使用SVR。主要贡献是提出了这个问题。

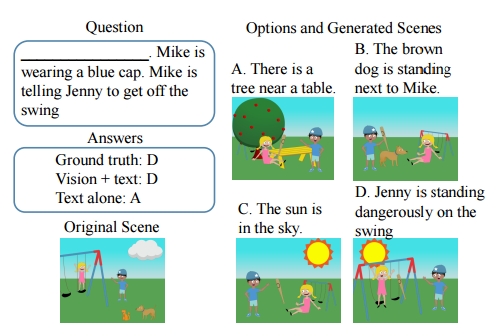
【Don't Just Listen, Use Your Imagination: Leveraging Visual Common Sense for Non-Visual Tasks】
别光听,还要想:利用视觉常识处理非视觉任务
利用视觉信息回答常识性问题。
一般的artificial agent系统搜索网络上的文本,来回答简单的常识性问题。
但有些问题网上没人讨论(可能太简单),有些难以用语句描述,需要多层次推理。

正确答案D包含了推理:熊很危险->人需要危险应该远离->躲起来可以远离。
这样的问题实际已经超出了recognition范畴。
训练集:Abstract Scene Dataset,人工生成的剪贴画场景,包含文本描述。
对于一个填空问题,首先“想象”还原其对应的场景,而后推断填空内容。
这篇实际不涉及CV算法,但利用了图像的思想。
代码和数据库公开。
【Becoming the Expert - Interactive Multi-Class Machine Teaching】
成为专家 - 交互多类计算机教学
非常有趣的场景:计算机教人 machine teaching。
人在学习一类目标时,应该先学习有代表性的样本,之后学习较模糊微妙的样本。
本文的系统能够自动根据学习者每一次的分类正误,顺序给出教学样本。
用graph based semi-supervised learning给学生这个分类器建模。
每次给出的教学样本,应该能最大降低未来的分类误差。

最后一行为本文方法。这样本也够糊弄的...
D2-AM-B. Multiple View Geometry
【Reconstructing the World* in Six Days *(As Captured by the Yahoo 100 Million Image Dataset)】
六天重建世界
SFM(structure-from-motion)问题。亿量级图像,生成多个城市的多视角结构。
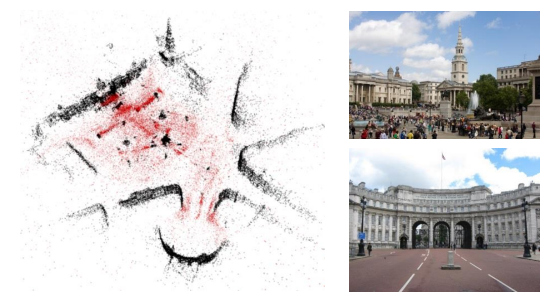
黑点为重建的三维结构,红点为相机位置。
基本方法:找出有交叠的图像,这些交叠图像组成connected component;而后找出全部数据中的connected component。
由于数据量极大,需要用基于streaming的结构(序列化方法)找出connected component:即每张图片只载入一次,在一段时间之后即被丢弃。
用iconic image表示一个connected component。随着遍历整个数据库,更新这些iconic image。
【Joint Vanishing Point Extraction and Tracking】
联合灭点提取和跟踪
(Luc Van Gool, ETH)
VP检测:找出场景中的消失点。三种颜色的线段对应三个消失点。
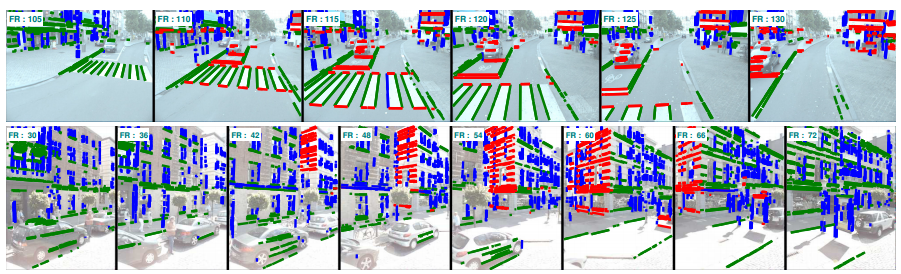
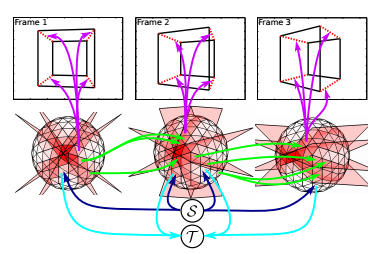
本文创新:从视频多帧中联合提取VP,不知道相机运动。
球面上的面片是离散化的VP位置,红色的深浅表示VP处于此位置的可能性。
和球面相交的四个平面是由摄像机位置计算出来的interpretation planes(?)。
借鉴多目标跟踪中的flow networks方法:不同帧中可能匹配的对有边相连。
网络的分割结果决定,是否属于同一个物体。(完全没懂)
【Robust Camera Location Estimation by Convex Programming】
鲁棒的凸规划估计摄像机位置
从多张2D图片回复3D结构。本文方法对outlier鲁棒。
全是数学。
【Efficient Globally Optimal Consensus Maximisation With Tree Search】
利用树搜索进行高效的全局一致性搜索
求解maximum consensus问题。
传统方法:挑几个,试一试,不能达到最优。
全局方法:太慢。
本文提供一种高效的全局方法。使用A*搜索。
【R6P - Rolling Shutter Absolute Camera Pose】
卷帘快门估计照相机姿态
absolute pose:从多张照片恢复拍照时的相机姿态。
rolling shutter: 各个感光元件不同时曝光。当相机运动时,会造成图像变形。
大多数消费级照相机、手机都是用CMOS传感器,而CMOS传感器使用的就是rolling shutter。
使用这样的图像恢复照相机姿态时,会受到干扰。本文使用解决这类问题。
【Building Proteins in a Day: Efficient 3D Molecular Reconstruction】
一天重建蛋白质结构
从一系列高噪声、未对齐的2D投影(particle images),重建一个高解析度的3D结构。
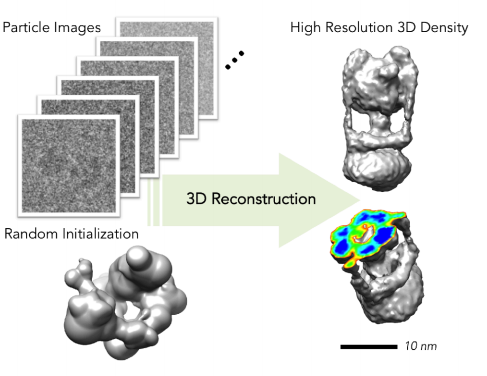
使用统计优化方法。用约1小时生成粗糙模型,再利用一个importance sampling方法大大提高生成精密结构的速度。















 2089
2089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









