










转载:http://blog.csdn.net/u011534057/article/details/51274907
Reference link:
http://blog.csdn.NET/whiteinblue/article/details/43374195
https://www.zybuluo.com/coolwyj/note/203086#1-classification
本文是纽约大学Yann LeCun团队中Pierre Sermanet ,David Eigen和张翔等在13年撰写的一篇论文,本文改进了Alex-net,并用图像缩放和滑窗方法在test数据集上测试网络;提出了一种图像定位的方法;最后通过一个卷积网络来同时进行分类,定位和检测三个计算机视觉任务,并在ILSVRC2013中获得了很好的结果。
一,介绍
卷积网络的主要优势是提供end-to-end解决方案;劣势就是对于标签数据集很贪婪。所以在大的数据集上面取得了很大的突破,但是在小的数据集上面突破不是很大,ImageNet数据集上的分类图片,物体大致分布在图片中心,但是感兴趣的物体常常在尺寸和位置(以滑窗的方式)上有变化;
解决这个问题的想法:
第一个想法想法就是在不同位置和不同缩放比例上应用卷积网络。但是种滑窗的可视窗口可能只包涵物体的一个部分,而不是整个物体;对于分类任务是可以接受的,但是对于定位和检测有些不适合。
第二个想法就是训练一个卷积网络不仅产生类别分布,还产生一个物体位置的预测和bounding box的尺寸;
第三个想法就是积累在每个位置和尺寸对应类别的置信度。
在多缩放尺度下以滑窗的方式利用卷积网络用了侦测和定位很早就有人提出了,一些学者直接训练卷积网络进行预测物体的相对于滑窗的位置或者物体的姿势。还有一些学者通过基于卷积网络的图像分割来定位物体。
二,视觉任务
简略解释一下三个任务:
classification:给定一张图片,以及一个标签指明图片中主要物体的类别,程序猜k次其类别,看是否和标签一致。
localization:与classification类似,区别在于它需要给出你猜的这些类别的物体的框,而且这个框与真实值的差距不能小于50%。
detection:事先不知道这张图片有没有可以分类的物体,有的话他们的数量是多少,需要给出物体的框以及其类别。
分类:是啥 预测top-5分类
定位:在哪是啥 预测top-5分类+每个类别的bounding box(50%以上的覆盖率认为是正确的)
检测:在哪都有啥
定位是介于分类和检测的中间任务,分类和定位使用相同的数据集,检测的数据集有额外的数据集(物体比较小)。
下面介绍一下各个方面idea的要点:
1. classification
基于Krizhevsky的论文[笔记],区别在于:
- 没有使用对比度归一化
- 没有使用overlapping-pooling
- 第一层和第二层使用了较小的步长
在提取特征的时候Krizhevsky的论文使用了multi-view的方法,也就是对给定的图片分别取四个角,中间以及翻转的图块输入到CNN中,得到的结果取均值。这个方法的缺陷在于有些区域的组合会被忽略(比如ground truth在中间偏右,但是此方法并没有检测这个框),只关注了一个scale导致结果的置信度不高,而且重叠区域的计算很耗时。
本文对其的改进是使用了multi-scale。
传统的检测/定位算法是固定输入图像不变,采用不同大小的滑窗来支持不同尺度的物体。
对于CNN来说,滑窗的大小就是训练时输入图像的大小,是不可以改变的。那么,CNN支持多尺度的办法就是,固定滑窗的大小,改变输入图像的大小。具体来说,对于一幅给定的待处理的图像,将图像分别resize到对应的尺度上,然后,在每一个尺度上执行上述的密集采样的算法,最后,将所有尺度上的结果结合起来,得到最终的结果。
然而,对于上文所述的密集采样算法来说,采样的间隔(也就是滑窗的 stride)等于执行所有卷积和pooling操作后图像缩小的倍数,也就是所有卷积层和pooling层的 stride 的乘积。
Important points ->如果这个值较大的话,采样就显得sparse,图像中的某些位置就无法采样得到。这时,或者减小卷积层和pooling层的 stride,或者干脆去掉某个pooling层,或者采用某种方法替代某个pooling层。
文章采用的方法是使用模型前5层卷积层来提取特征,layer 5在 pooling 之前给定 x,y 一个偏移,即对每个 feature map 滑窗从(0,0), (0,1), (0,2), (1,0), (1,1)...处分别开始滑动,得到9种不同的feature map,那么下一层的 feature map 总数为9*前一层的 num_output,至此,整个分类过程结束。
其过程可以简单理解为:给定一张框定的图片,已知这张图片有某种可分类物体,但是由于框给的不是很合适,没有alignment,和训练的时候有差异,所以取不同scale图片进行检测,得到结果。对于CNN,使用不同scale需要放缩图片,由于最后的FC层的输入大小是固定的(比如5x5),所以不同scale输入经过pool5之后的 'feature map' 大小不一,此时取所有可能5x5作为输入得到特征向量.
最后的预测方法如下:对某一个类别,分别对不同scale矩阵取最大值,然后取该类别中不同矩阵最大值的均值,最后输出所有类别的top-1 or top-5。
经过FC层形成的矩阵中,一个像素就相当于原来图像中的一个图块。
示意图:

2. Localization
定位问题的模型也是一个CNN,1-5层作为特征提取层和分类问题完全一样,后面接两个全连接层,组成regressor network 。训练时,前面5层的参数由 classification network 给定,只需要训练后面的两个全连接层。这个 regressor network 的输出就是一个 bounding box ,也就是说,如果将一幅图像或者一个图像块送到这个regressor network中,那么,这个 regressor network 输出一个相对于这个图像或者图像块的区域,这个区域中包含感兴趣的物体。这个 regressor network 的最后一层是class specific的,也就是说,对于每一个class,都需要训练单独最后一层。这样,假设类别数有1000,则这个 regressor network 输出1000个 bounding box ,每一个bounding box 对应一类。
对于定位问题,测试时,在每一个尺度上同时运行 classification network 和 regressor network 。这样,对于每一个尺度来说, classification network 给出了图像块的类别的概率分布,regressor network 进一步为每一类给出了一个 bounding box,这样,对于每一个 bounding box,就有一个置信度与之对应。最后,综合这些信息,给出定位结果。
算法还给出了一个合并多余框的方法:
令Cs为top-k(例如5)标准中每个scale下找到的可能类别。令Bs为Cs中这些类别的预测框。而B集合是Bs的并集。找B集合里面两个框的中心距离和相交面积之和最小的一对,如果他们的和大于给定阈值t,则结束,否则从B中删去两个框,合并这一对用他们的均值构成新的一个框,加入B
3. Detection
其实就是上述两个结合一下
三,分类
3.1 参数设置
提取221*221的图片,batch大小,权值初始值,权值惩罚项,初始学习率和Alex-net一样。不同地方时就动量项权重从0.9变为0.6;在30, 50, 60, 70, 80次迭代后,学习率每次缩减0.5倍。
3.2模型设计
作者提出了两种模型,fast模型和accurate模型。
Fast模型:
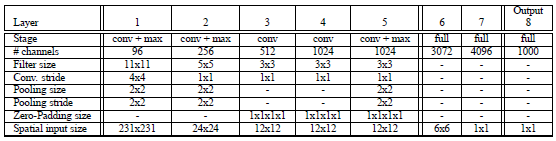
Input(231,231,3)→96F(11,11,3,s=4)→max-p(2,2,s=2)→256F(5,5,96,1) →max-p(2,2,2) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024) →max-p(2,2,2) →3072fc→4096fc→1000softmax
Fast模型改进:
1,不使用LRN;
2,不使用over-pooling使用普通pooling;
3,第3,4,5卷基层特征数变大,从Alex-net的384→384→256;变为512→1024→1024.
4,fc-6层神经元个数减少,从4096变为3072
5,卷积的方式从valid卷积变为维度不变的卷积方式,所以输入变为231*231
Accurate模型改进:
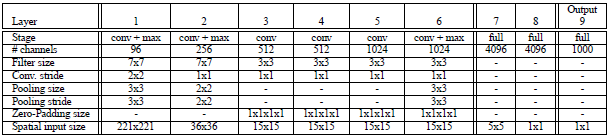
Input(231,231,3)→96F(7,7,3,s=2)→max-p(3,3,3)→256F(7,7,96,1)→max-p(2,2,2) →512F(3,3,512,1) →512F(3,3,512,1) →1024F(3,3,1024,1) →1024F(3,3,1024,1) →max-p(3,3,3) →4096fc→4096fc→1000softmax
1,不使用LRN;
2,不使用over-pooling使用普通pooling,更大的pooling间隔S=2或3
3第一个卷基层的间隔从4变为2(accurate 模型),卷积大小从11*11变为7*7;第二个卷基层filter从5*5升为7*7
4增加了一个第三层,是的卷积层变为6层;从Alex-net的384→384→256;变为512→512→1024→1024.
感觉这个调整和ZF-net的结构调整很像,毕竟他们都是纽约大学里面一个团队的;fast模型使用更小的pooling局域2*2,,增加3,4,5层特征情况下,减少fc-6层的神经元,保持网络复杂度较小的变化;accurate模型感觉有些暴力,缩小间隔,增加网络深度,增加特征数;通过提升计算复杂度,来提取更多的信息,从而提升效果.
两个模型参数和连接数目对比:
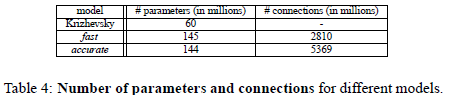
Fast模型比accurate模型的参数还多,这个让我比较意外;感觉fast模型和Alex-net参数应该差不多,而应该和accurate差很多。但是计算结果让我有些意外:
每层参数个数:=特征数M*每个filter大小(filter_x*filter_y*连接特征数(由于本文是全连接,所以连接特征数就等于前一层特征个数))没有把bias计算在内。
|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Fast | 3.5万 | 61 | 118 | 0 | 472 | 944 | 11324 | 1678 | 409 |
| Accurate | 1.4万 | 120 | 118 | 236 | 472 | 944 | 10485 | 1678 | 409 |
通过计算发现,连接方式,特征数目,filter尺寸是影响参数个数的因素;
1连接方式是关键因素,例如主要参数都分布在全连接层;
2最后一个卷基层特征图的大小也是影响参数个数的关键,例如第七层fast模型的特征图为6*6; accurate模型的输入特征为5*5,所以尽管accurate比fast多了1024个全连接神经元,但是由于输入特征图相对较小,多所以本层两个模型的参数差的不多。所以最后一个卷基层特征图大小对参数影响较大。
3.2 多尺寸分类测试
Alex-net中,使用multi-view的方式来投票分类测试;然而这种方式可能忽略图像的一些区域,在重叠的view区域会有重复计算;而且还只在单一的图片缩放比例上测试图片,这个单一比例可能不是反馈最优的置信区域。
作者在多个缩放比例,不同位置上,对整个图片密集地进行卷积计算;这种滑窗的方式对于一些模型可能由于计算复杂而被禁止,但是在卷积网络上进行滑窗计算不仅保留了滑窗的鲁棒性,而且还很高效。每一个卷积网络的都输出一个m*n-C维的空间向量,C是分类的类别数;不同的缩放比例对应不同的m和n。
整个网络的子采样比例=2*3*2*3=36,即当应用网络计算时,输入图像的每个维度上,每36个像素才能产生一个输出;在图像上密集地应用卷积网络,对比10-views的测试分类方法,此时粗糙的输出分布会降低准确率(没想明白,怎么就粗糙了);因为物体和view可能没有很好的匹配分布(物体和view越好的匹配,网络输出的置信度越高)。为了绕开这个问题,我们采取在最后一个max-pooling层换成offset max-pooling,平移pooling;这种平移max-pooling是一种数据增益技术。
offset max-pooling:
平移量△:x,y连个维度平移量都为0,1,2(由于pooling区域为3*3)
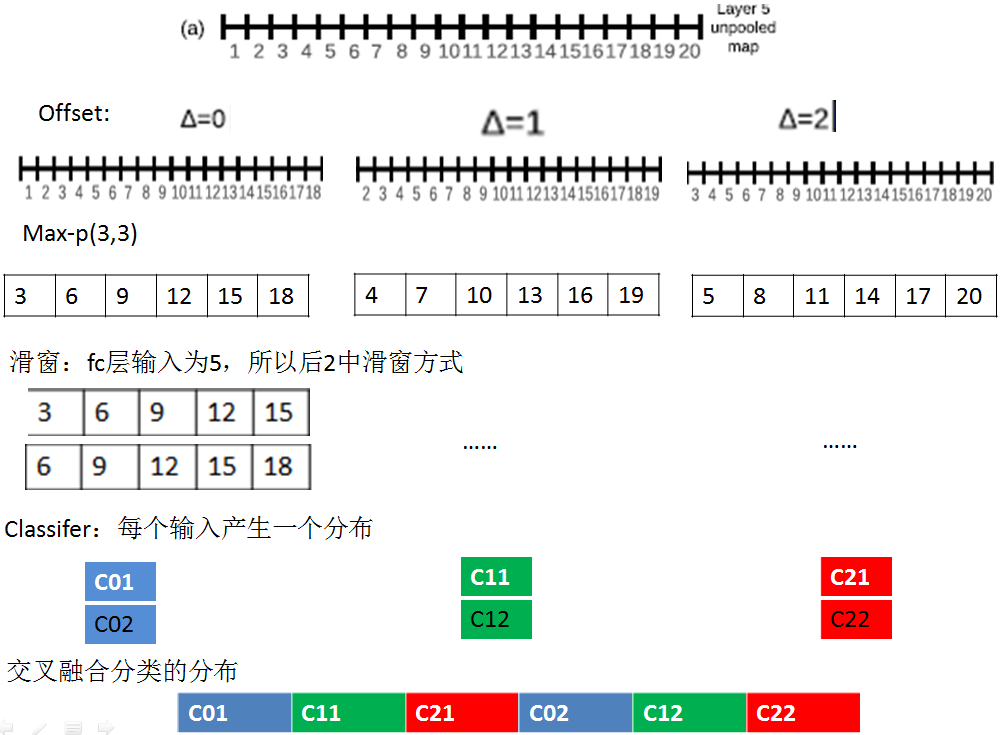
Step1计算特征图:计算layer-5未pooling的特征图unpooling-FM
Step2平移特征图:按照平移量产生不同的平移特征图;本文是x,y连个维度,每个维度平移量为0,1,2.所以每个unpooling-FM,产生9种平移特征图offset-pooling FM(一维的是3种)。
Step3max-pooling:在每个平移offset-pooling FM图上,进行普通的max-pooling操作产生pooled FM。
Step4滑窗提取输入:由于全连接层fc的输入维数和pooled FM特征维数不同,一般pooled FM较大,例如上图中一维的例子,pooled FM维数为6,而fc的输入维数为5,所以可以采用滑窗的方式来提取不同的输入向量。
Step5 输入分类器:产生分类向量
Step6交叉融合。
通过上面的这种方式,可以减少子采样比例,从36变为12;因为通过offset,每个维度产生了3个pooled输出。此外,由于每个输入窗口对应不同的原始图像位置,所以通过这种密集滑窗的方式可以找到物体和窗口很好的匹配,从而增加置信度;但是感觉好复杂。
实验结果:
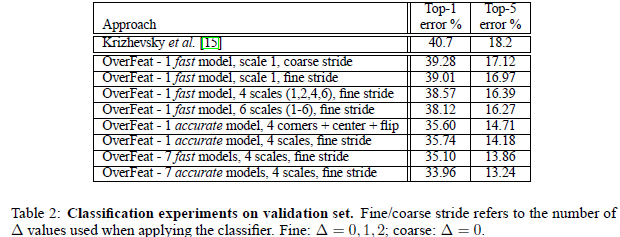
1,fast模型,比Alex-net结果提升了近1%,但是fast模型修改了很多地方,具体哪一个地方的修改其作用,这个不清楚。本文Alex-net模型结果为18.2%比他们自己测试的高2%左右
2,accurate模型单个模型提升了近4%,说明增大网络可以提高分类效果。
3,采用offset max-pooling感觉提升效果很小,感觉是因为卷积特征激活值具有很高的聚集性,每个offset特征图很相似,max-pooling后也会很相似。
4,多个缩放比例测试分类对于结果提升比较重要,通过多个比例可以把相对较小的物体放大,以便于特征捕捉。
3.5 卷积网络和滑窗效率
对比很多sliding-windows方法每次都需要计算整个网络,卷积网络非常高效,因为卷积网络在重叠区域共享计算。
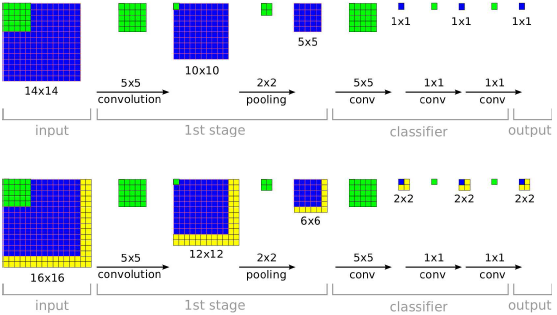
例如训练阶段在小的view(如图,14*14)下,训练网络;测试阶段在多个较大的图片上测试,由于每个14*14的view区域产生一个分类预测分布,上图在16*16的图片上测试,有4个不同的14*14的view,所以最后产生一个4个分类预测分布;组成一个具有C个特征图的2*2分类结果图,然后按照1*1卷积方式计算全连接部分;这样整个系统类似可以看做一个完整的卷积系统。
四,定位
基于训练的分类网络,用一个回归网络替换分类器网络;并在各种缩放比例和view下训练回归网络来预测boundingbox;然后融合预测的各个bounding box。
4.1 生成预测
同时在各个view和缩放比例下计算分类和回归网络,分类器对类别c的输出作为类别c在对应比例和view出现的置信分数;
4.2 回归训练
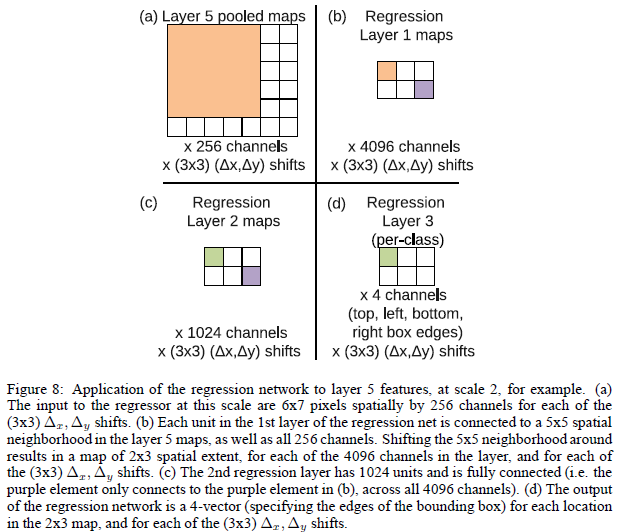
如上图所示,每个回归网络,以最后一个卷积层作为输入,回归层也有两个全连接层,隐层单元为4096,1024(为什么作者没有说,估计也是交叉实验验证的),最后的输出层有4个单元,分别是预测bounding box的四个边的坐标。和分类使用offset-pooling一样,回归预测也是用这种方式,来产生不同的预测结果。
使用预测边界和真实边界之间的L2范数作为代价函数,来训练回归网络。最终的回归层是一个类别指定的层,有1000个不同的版本。训练回归网络在多个缩放比例下对于不同缩放比例融合非常重要。在一个比例上训练网络在原比例上表现很好,在其他比例上也会表现的很好;但是多个缩放比例训练让预测在多个比例上匹配更准确,而且还会指数级别的增加预测类别的置信度。

上图展示了在单个比例上预测的在各个offset和sliding window下 pooling后,预测的多个bounding box;从图中可以看出本文通过回归预测bounding box的方法可以很好的定位出物体的位置,而且bounding box都趋向于收敛到一个固定的位置,而且还可以定位多个物体和同一个物体的不同姿势。但是感觉offset和sliding window方式,通过融合虽然增加了了准确度,但是感觉好复杂;而且很多的边框都很相似,感觉不需要这么多的预测值。就可以满足超过覆盖50%的测试要求。
4.3结合预测
a)在6个缩放比例上运行分类网络,在每个比例上选取top-k个类别,就是给每个图片进行类别标定Cs
b)在每个比例上运行预测boundingbox网络,产生每个类别对应的bounding box集合Bs
c)各个比例的Bs到放到一个大集合B
d)融合bounding box。具体过程应该是选取两个bounding box b1,b2;计算b1和b2的匹配分式,如果匹配分数大于一个阈值,就结束,如果小于阈值就在B中删除b1,b2,然后把b1和b2的融合放入B中,在进行循环计算。
最终的结果通过融合具有最高置信度的bounding box给出。
具体融合过程见下图:
1,不同的缩放比例上,预测结果不同,例如在原始图像上预测结果只有熊,在放大比例后(第三,第四个图),预测分类中不仅有熊,还有鲸鱼等其他物体

2通过offset和sliding window的方式可以有更多的类别预测

3在每个比例上预测bounding box,放大比例越大的图片,预测的bounding box越多
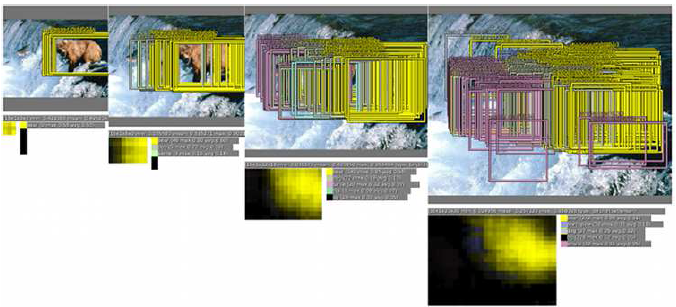
4,融合bouding box

在最终的分类中,鲸鱼预测和其他的物体消失不仅使因为更低的置信度,还有就是他们的bounding box集合Bs不像熊一样连续,具有一致性,从而没有持续的置信度积累。通过这种方式正确的物体持续增加置信度,而错误的物体识别由于缺少bounding box的一致性和置信度,最终消失。这种方法对于错误的物体具有鲁棒性(但是图片中确实有一些鱼,虽然不是鲸鱼;但是系统并没有识别出来;也可能是类别中有鲸鱼,但是没有此种鱼的类别)。
4.4实验
本文多个multi-scale和multi-view的方式非常关键,multi-view降低了4%,multi-scale降低了6%。令人惊讶的是本文PCR的结果并没有SCR好,原因是PCR的有1000个模型,每个模型都是用自己类别的数据来进行训练,训练数据不足可能导致欠拟合。而SCR通过权值共享,得到了充分的训练。
五,检测
检测和分类训练阶段相似,但是是以空间的方式进行;一张图片中的多个位置可能会同时训练。和定位不通过的是,图片内没有物体的时候,需要预测背景。
本文的方法在ILSVRC中获得了19%,在赛后改进到24.3%;赛后主要是使用更长的训练时间和利用“周围环境”(每一个scale也同时使用低像素scale作为输入;介个有点不明白)。
六,总结
1,multi-scale sliding window方式,用来分类,定位,检测
2,在一个卷积网络框架中,同时进行3个任务
本文还可以进一步改进,
1,在定位实验总,没有整个网络进行反向传播训练
2,用评价标准的IOU作为损失函数,来替换L2
3,交换bounding box的参数,帮助去掉结果的相关性(这个有点不明白)。
后来工作2被牛津大学作者做了出来。
一些困惑和理解
感觉卷积网络真的好强大,干啥都行,而且还能相互间共享特征;虽然分类,定位,和检测的难度是递增的,但是感觉分类是最基础的,分类结果的好坏决定了后面两个任务的好坏,因为图片中物体分类准确了,才能进行定位和检测;在分类阶段调整网络部分并没有过多的叙述原因,只是给出了最后的网络结构,通过暴力式的增加复杂度,提取更多信息。
本文multi-scale测试的处理方式和SPP-net(系列中的一篇博文)的方式有些不同,本文是通过multi-view的方式采用滑窗的方式产生多个数据结果,而Spp-net通过改变子采样比例,来得到固定的特征层输出。
感觉本文的滑窗方式更适合预测bounding box和detection;因为这种方式可以是物体和view很好的匹配,从而得到很好置信得分,但是还是感觉有些复杂,例如offset是否可以使用两个,sliding window感觉可以像Alex-net那样采用5-view的方式,在特征图中选取上下左右和中间5个view进行预测就可以了,因为pooling的特征具有聚集性,感觉每个view会有很大的相似性。
图中对熊的定位实例中,卷积网络在不同的scale上面会得到不同的分类结果,在联合上一篇博文中两位作者对平移,缩放和翻转不变形的探讨;卷积网络的优势就是对于平移具有不变形,但是感觉对于平移和缩放的识别能力是有限的,对于大的物体能够很好的识别,对于小的物体感觉网络有些乏力,这可能也就是为什作者在multi-scale时,从来都是放大而不是缩小;还有就是感觉和每个高层对应底层的感受野有关,例如才本文中一个layer-5的特征激活值,对应输入层图像36*36的一个小区域,如果物体比36*36区域小,或者稍微大一些;感觉网络就会识别困难。感觉后面GoogLeNet,里面的Inception模型,就和这个有关系,不同的filter和pooling可以对应不同的初始感受野(个人观点)。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









