







本文主要是对上采样和dilated convolution进行了修改,优点在于:1.扩大网络的感受野,以聚集更多的全局信息,2.解决由标准dilated convolution所引起的"gridding效应",最后在cityscapes达到很好的效果。
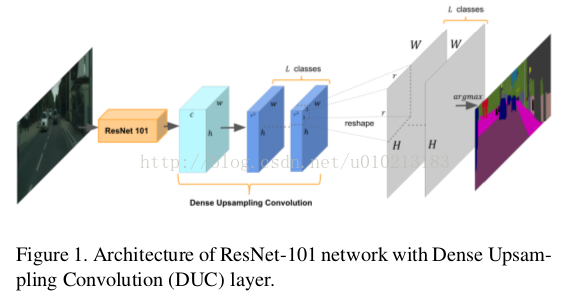
DUC:不同于传统的一次性回复全分辨率的label Map,我们通过学习一系列放大滤波器将缩小的特征图放大到所需大小的密集特征图。DUC能够自适应FCN框架,进行端到端的训练,在cityscapes上得到较高的mIOU,尤其对相对较小的物体上效果较好。
dilated convolution:主要的思想是在卷积核的像素之间插入“holes(也就是0)”,来增加图像的分辨率以及提高网络的感受野,从而可以在deep CNNs中提取密集特征,消除下采样的使用(max-pooling或者是strided convolution)。
假设原图大小为H×W,经过ResNet后维度变为h×w×c(其中h=H/r,w=W/r),通过卷积后输出feature map维度为h×w×(r^2×L),其中L是语义分割的类别数。最后通过reshape到H×W×L尺寸就可以了。DUC的核心思想就是将整个label map分成若干个和输入特征图(heatmap)大小相等的部分。所有的子部分被叠加r^2次就可以产生整个label map了。这种变化允许我们直接在输入特征图和输出标签图之间进行卷积操作,而无需像反卷积层一样插入额外的值(“unpooling”操作)。”
此外,DUC网络可以融入到FCN框架中,可以使整个编码和解码过程变成端到端的训练。
HDC主要是为了解决使用dilated convolution会产生的“gridding issue”。

当dilated convolution在高层使用的rate变大时,对输入的采样将变得很稀疏,将不利于学习——因为一些局部信息完全丢失了,而长距离上的一些信息可能并不相关;并且gridding效应可能会打断局部信息之间的连续性。
DUC:不同于传统的一次性回复全分辨率的label Map,我们通过学习一系列放大滤波器将缩小的特征图放大到所需大小的密集特征图。DUC能够自适应FCN框架,进行端到端的训练,在cityscapes上得到较高的mIOU,尤其对相对较小的物体上效果较好。
dilated convolution:主要的思想是在卷积核的像素之间插入“holes(也就是0)”,来增加图像的分辨率以及提高网络的感受野,从而可以在deep CNNs中提取密集特征,消除下采样的使用(max-pooling或者是strided convolution)。
假设原图大小为H×W,经过ResNet后维度变为h×w×c(其中h=H/r,w=W/r),通过卷积后输出feature map维度为h×w×(r^2×L),其中L是语义分割的类别数。最后通过reshape到H×W×L尺寸就可以了。DUC的核心思想就是将整个label map分成若干个和输入特征图(heatmap)大小相等的部分。所有的子部分被叠加r^2次就可以产生整个label map了。这种变化允许我们直接在输入特征图和输出标签图之间进行卷积操作,而无需像反卷积层一样插入额外的值(“unpooling”操作)。”
此外,DUC网络可以融入到FCN框架中,可以使整个编码和解码过程变成端到端的训练。















 1699
1699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









