







 本文详细介绍了卷积神经网络的训练过程,包括全连接层的前向传播和反向传播,以及卷积层和池化层的误差计算方法。通过对各层的输出和误差分析,展示了如何利用梯度下降等方法进行权值更新。
本文详细介绍了卷积神经网络的训练过程,包括全连接层的前向传播和反向传播,以及卷积层和池化层的误差计算方法。通过对各层的输出和误差分析,展示了如何利用梯度下降等方法进行权值更新。
第一部分 全连接网络的权值更新
卷积神经网络使用基于梯度的学习方法进行监督训练,实践中,一般使用随机梯度下降(机器学习中几种常见的梯度下降方式)的版本,对于每个训练样本均更新一次权值,误差函数使用误差平方和函数,误差方式采用平方误差代价函数。
注:本文主要按照参考文献中内容来写的,其中某些部分加入了自己解释,此文内容不断更新充实中,直到让人可以看完之后完全了解卷积神经网络的计算过程。
1.1 前向传播中样本的误差以及每层的输出
全连接区的第l层(l来表示当前层)的输出函数为:
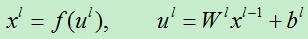
全部训练集上的误差只是每个训练样本的误差的总和,先考虑对于一个样本的BP。则对于第n个样本的误差,表示为:
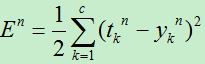
其中tk表示第n个样本对应的标签的第k维,yk表示第n个样本对应的网络输出的第k个输出。
1.2 反向传播中样本的权值更新
权值更新具体来说就是,对一个给定的神经元,得到它的输入,然后用这个神经元的delta(即δ)来进行缩放。用向量的形式表述就是,对于第l层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的δ组合成一个向量的形式)的叉乘。然后得到的偏导数乘以一个负学习率就是该层的神经元的权值的更新了:
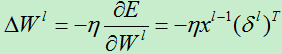
A)对于第L层的权值,我们有:
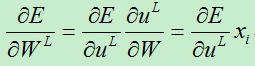
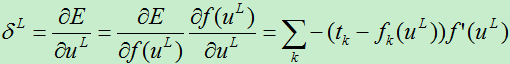
B)对于第l层的权值,求偏导数:
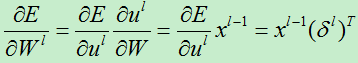
第二部分 当接在卷积层的下一层为pooling层时,卷积层的误差敏感项
在一个卷积层,上一层的特征maps被一个可学习的卷积核进行卷积,然后通过一个激活函数,就可以得到输出特征map,每一个输出map可能是组合卷积多个输入maps的值。首先卷积层的输出为:
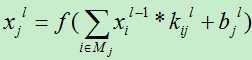
上面的*号实质是让卷积核k在第l-1层所有关联的feature maps上做卷积运算。
由于卷积层的下一层为抽样层,那么首先需要知道在下一层哪些神经元与该卷积层的节点i的联系,然后根据原来的采样方式进行误差分析。由于采样层在从卷积层采样时,同一个结点不会被重复采样(注意这里不会重复采样,就是不会有重叠区域,这里和卷积操作时的滑窗操作不相同),因而,卷积层的一个局部感受野对应采样层中的神经元的一个输入。
假设我们现在分析的卷积层是第l层,则其下一层为l+1层(为池化层)。采用的是一对一非重叠采样。则第l层的节点j的误差项为:
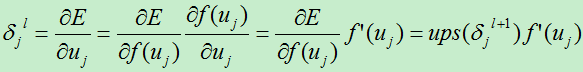
上式并未考虑到第l层到下一层的权值:
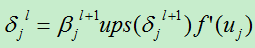
其中:Ups (x):对x进行上采样,此处表示下一层的误差项中x的贡献值。
接下来我们需要知道这个ups()是怎么得到的。其具体操作要根据前面的pooling的方法,因为下一层的pooling层的每个节点由l层的多个节点共同计算得出,pooling层每个节点的误差敏感值也是由卷积层中多个节点的误差敏感值共同产生的,常见的采样方式有最大池化与平均池化两种。
A)若前面使用mean-pooling方法,则将下一层的误差项除以下一层所用的滤波器的大小。假如下一层的滤波器的大小为k*k,则:
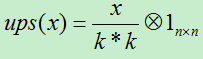
mean-pooling时的unsample操作可以使用matalb中的函数kron()来实现,因为是采用的矩阵Kronecker乘积。C=kron(A, B)表示的是矩阵B分别与矩阵A中每个元素相乘,然后将相乘的结果放在C中对应的位置。
B)若前面使用max-pooling方法,则将需要记录前向传播过程中pooling区域中最大值的位置,然后判断当前的结点是否在最大位置上,若在最大位置上则直接将当前的下一层的误差值赋值过来即可,否则其值赋0。也就是说原convolution区块中输出最大值的那个neuron进行反向传播,其他neuron对权值更新的贡献算做0。
有了上面了误差损失项,现在我们开始计算损失函数对基的偏导数和对权向量的偏导数(也就是所谓的梯度计算):
A)基的偏导数,损失函数对基的偏导数为:
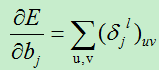
B)权值的变化量,损失函数对权值的偏导数为:
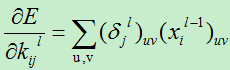
第三部分 当接在pooling层的下一层为卷积层时,该pooling层的误差敏感项
对于采样层,其输出值计算公式为:

其中down(xj)为神经元j的下采样。
在这里我们向上面卷积层一样,需要先计算出误差项,然后通过误差项就可以计算得到其他权值和偏置。
由于采样层的下一层为卷积层,采样层的每个节点可能被卷积多次。假如当前的采样层为第l层,我们需要计算第j个结点的神经元的误差,则我们首先需要找到第l+1层中哪些神经元用到过结点j,这需要我们在将l层卷积到l+1层的时候保存神经元的映射过程,因为在计算反向传播误差时需要用到。先假设第l+1层中用到结点j的神经元的集合个数为M,
则第l层的误差项为:
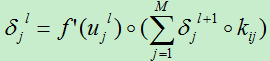
现在我们可以很轻松的对训练偏置和位移偏置的导数:
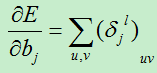
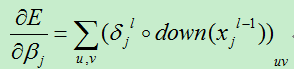
最核心的步骤就是求解误差项(又称灵敏度),其他的计算都是以此为基础。误差项的求解首先要分析需要计算的结点j与下一层的哪个或哪些节点节点有关联,因为结点j是通过下一层与该节点相连的神经元来影响最终的输出结果,这也就需要保存每一层节点与上一层节点之间的联系,以便在反向计算误差时方便使用。
下篇博文对卷积神经网络中出现的一些问题进行一个详细的阐述。博客地址:http://blog.csdn.net/u010402786/article/details/51228405
主要参考文献:
http://blog.csdn.net/zouxy09/article/details/9993371
http://www.cnblogs.com/liuwu265/p/4707760.html
http://www.cnblogs.com/loujiayu/p/3545155.html?utm_source=tuicool

















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









