







特征选择 feature selection
终于有时间把好久之前就想写的关于特征选择的基本介绍补上来了,主要想从以下几个方面介绍:
- 特征选择的动机–为什么要特征选择
- 常见的特征选择方法–如何特征选择
- 特征选择的效果
一. 动机
提到特征选择的动机首先要说下维灾难(the curse of dimensionality),用个图(图片来自wiki)来形象的说明维灾难:
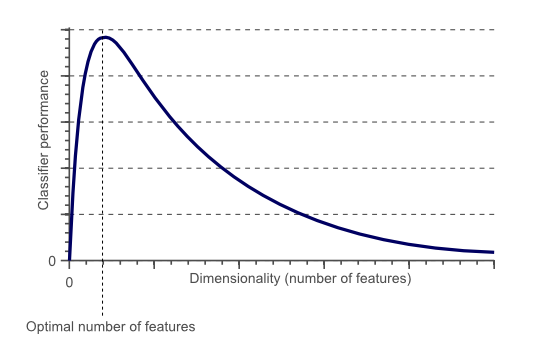
所谓的维灾难就是当特征维度超过一定界限后,分类器的性能随着特征维度的增加反而下降(而且维度越高训练模型的时间开销也会越大)。导致分类器下降的原因往往是因为这些高纬度特征中含有无关特征和冗余特征,因此特征选择的主要目的是去除特征中的无关特征和冗余特征:

无关特征:是指与当前学习任务无关的特征(该特征所提供的信息对于当前学习任务无用),如对于学生成绩而言,学号则是无关特征。
冗余特征:是指该特征所包含的信息能从其他特征推演出来,如对于“面积”这个特征而言,从能从“长”和“宽”得出,则它是冗余特征。
二. 常见的特征选择方法
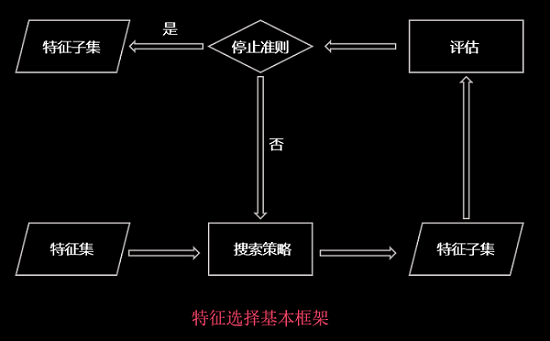
1.特征选择的基本框架
2.搜索策略
常见的搜索策略主要有三种:
- 完全搜索
也就是枚举特征集中的所有特征组合从而选出最优的特征子集,复杂度为 O(2n) ,因此实际应用中几乎不用。 - 启发式搜索
启发式搜索策略主要有序列前向选择(SFS,Sequential Forward Selection)和序列后向选择(SFS,Sequential Forward Selection)等。假定原始特征集是 f ,挑选出来的特征子集是fsub 。序列前向搜索策略首先把特征子集 fsub 初始化为空集,每一步从 f−fsub (余下的特征集)中选择使得评价函数 J(fsub+x) 最优的特征 x 直至评价函数J 无法改进,该算法便认为得到了最优的属性子集。与序列前向搜索策略相反的是,序列后向搜索策略搜索特征子集 fsub 从全集开始,每次删除一个属性 x ,重复该过程,直到评价函数J(fsub−x) 最优。序列前向搜索策略和序列后向搜索策略的思想都为贪心思想,因此有时候容易陷入到局部最优中。 - 随机搜索
随机搜索策略,即在计算过程中把特征选择问题和禁忌搜索算法、模拟退火算法和遗传算法等,或随机重采样过程结合起来以概率推理和随机采样作为算法基础,基于对分类有效性的评估,在计算过程中对每个特征赋予一定的权重,然后根据自适应的阈值或者用户自定义的阈值来对特征重要性进行评估,选择大于阈值的特征。Relief系列算法是典型的代表。
3.特征选择算法的分类
常见的特征选择方法可以大致分为三类:过滤法(filter)、包裹式(wrapper)、嵌入式(embedding)。
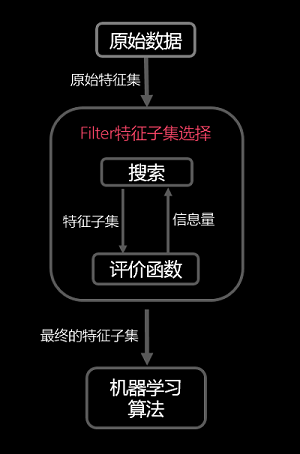
- 过滤式(filter)
过滤式的基本原理如下图所示:
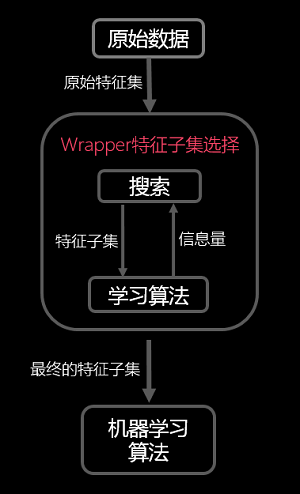
其先对数据集进行特征选择,使用选择出来的特征子集训练学习器,特征选择选择过程与后续的学习器无关。 - 包裹式(wrapper)
过滤式的基本原理如下图所示:
包装法特征选择方法直接把最终将要使用的学习器的性能作为特征子集的评价准则,这是与过滤法特征选择方法最大的区别。
Dash等人在总结Ben-Bassat等人、Doak等人的工作后将评价准则分为五类:距离度量(Distance Measure)、信息增益度量(Information Gain Measure)、依赖性度量(Dependence Measure)、一致性度量(Consistency Measure)和分类器错误率度量(Classifier Error Rate Measure)。
(1)距离度量:距离度量一般认为是差异性或者分离性的度量,常用的距离度量方法有欧式距离等。对于一个二元分类问题,对于两个特征
f1
和
f2
,如果特征
f1
引起的两类条件概率差异大于特征
f2
,则认为特征
f1
优于特征
f2
。
(2)信息增益度量:特征f的信息增益定义为使用特征f的先验不确定性与期望的后验不确性之间的差异。若特征
f1
的信息增益大于特征
f2
的信息增益,则认为特征
f1
优于特征
f2
。
(3)依赖性度量:依赖性度量又称为相关性度量(Correlation Measure)、通常可采用皮尔逊相关系数(Pearson correlation coefficient)来计算特征f与类别C之间的相关度,若特征
f1
与类别C之间的相关性大于特征
f2
与类别C之间的相关性,则认为特征
f1
优于特征
f2
。同样也可以计算得到属性与属性之间的相关度,属性与属性之间的相关性越低越好。
(4)一致性度量:假定两个样本,若它们的特征值相同,且所属类别也相同,则认为它们是一致的:否则,则称它们不一致。一致性常用不一致率来衡量,其尝试找出与原始特征集具有一样辨别能力的最小的属性子集。
(5)分类器错误率度量:该度量使用学习器的性能作为最终的评价阈值。它倾向于选择那些在分类器上表现较好的子集。
以上5种度量方法中,距离度量(Distance Measure)、信息增益度量(Information Gain Measure)、依赖性度量(Dependence Measure)、一致性度量(Consistency Measure)常用于过滤式(filter);分类器错误率度量(Classifier Error Rate Measure)则用于包裹式(wrapper)。

因为包装式特征选择直接将最终将要使用的学习器的性能作为评价函数,因此从模型性能的角度出发,能够发现包装式特征选择的性能要优于过滤式特征选择,但是包装式特征选择的时间开销较大。而过滤式特征选择由于和特定的学习器无关,所以计算开销小,泛化能力强于包装式特征选择。因此,在实际应用中由于数据集很大,特征维度高,过滤式特征选择应用的更广泛些。
- 嵌入式(embedding)
嵌入式特征选择方法是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动完成了特征选择。具体的内容可以参见周志华大牛的《机器学习》(西瓜书)。
三. 特征选择的效果
通过在平时的应用中能够发现特征选择能够明显的改善学习器的精度,减少模型训练时间,有效的避免维灾难问题。
参考文献:
[1]Dash M, Liu H. Feature Selection for Classification[J]. Intelligent Data Analysis, 1997,1(1-4):131–156.
[2]周志华.机器学习[M].北京:清华大学出版社,2016:252-253.
未经博主同意,不得盗用博文插图,转载请注明出处














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









